directory | systems:research :)
@ -23,7 +23,7 @@
|
|||||||
"format": "unix-time"
|
"format": "unix-time"
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"default": "2025-04-01T17:24:12.665Z"
|
"default": "2025-04-03T18:32:26.199Z"
|
||||||
},
|
},
|
||||||
"description": {
|
"description": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
|
|||||||
@ -3,7 +3,7 @@
|
|||||||
"messages": [
|
"messages": [
|
||||||
{
|
{
|
||||||
"role": "user",
|
"role": "user",
|
||||||
"content": "Create a concise description for SEO meta (around 150-160 characters) from the text below. \n Disregard any links or image references. \n Return only the final meta description, no extra commentary.\n\nText to process:\nThis tutorial demonstrates the process of cutting HDPE sheets using an X-Carve CNC.\n\nFor a complete video in Spanish with subtitles, visit: [YouTube Video](https://www.youtube.com/watch?v=4LrrFz802To)\n\n\nUser Location: Mexico City, Mexico\n\nTo proceed, measure your plastic sheet: height, width, and thickness. Our X-Carve machine operates with the CAM software Easel, which I find to be user-friendly for CNC milling.\n\nEasel allows you to simulate the material, and it includes HDPE in its cutting material list.\n\n## Instructions for Securing a Sheet with CNC Clamps\n\nTo secure the sheet to the table, use the CNC clamps from the X-Carve.\n\nOpen a vector design program like Inkscape to create or download a vector file from [The Noun Project](https://thenounproject.com).\n\nDownload the SVG file and import it into Easel.\n\nWith the file ready, select the desired cutting width and proceed to cut using the wizard:\n- Ensure the sheet is secured.\n- Specify the cutting bit; a 1/8 inch (3.175 mm) flat flute bit is used.\n- Set the machine's 0-0 coordinate, typically the lower left corner.\n- Raise the bit, and start the CNC Router.\n\n### Tutorial Step: Showcasing Your Finished Object\n\nNow, finish post-processing your glasses or object, and share it with others.\n\nYou can attempt this project using various CNC machines, including manual routers or saws, as demonstrated in this [video](https://youtu.be/gxkcffQD3eQ). Sharing your work contributes to community development.\n\nShare your ideas and comments."
|
"content": "Create a concise description for SEO meta (around 150-160 characters) from the text below. \n Disregard any links or image references. \n Return only the final meta description, no extra commentary.\n\nText to process:\nThis guide outlines the process for cutting HDPE sheets using an X-Carve CNC. For a detailed demonstration, refer to the video available in Spanish with subtitles: [Watch Video](https://www.youtube.com/watch?v=4LrrFz802To).\n\n\nUser Location: Mexico City, Mexico\n\nTo proceed, measure the plastic sheet's height, width, and thickness. The X-Carve machine operates with the CAM software Easel, which is user-friendly for CNC milling.\n\nEasel allows simulation of your material, and includes HDPE 2-Colors in its list of cutting materials.\n\nUsing the clamps from the X-Carve, secure the sheet to the table.\n\n### Instructions\n\nProceed by using software like Inkscape to create a vector file, or download one from a source such as [thenounproject.com](https://thenounproject.com).\n\nDownload the SVG file, which is a standard vector format, and import it into Easel.\n\nWith the file ready, choose the desired width for carving or cutting. Proceed with the following steps:\n\n- Ensure the sheet is securely fixed.\n- Specify the cutting bit: use a 1/8-inch (3.175 mm) flat flute bit.\n- Set the coordinate origin at the lower-left corner (0, 0).\n- Raise the bit and activate the CNC router.\n\n### Instructions for Post-Processing\n\nTake your glasses or object, complete the post-processing, and share the results with others.\n\nThis project can be attempted with various CNC machines, including manual routers or saws. The essential aspect is sharing your work to contribute to community growth.\n\nFeel free to share your ideas and comments."
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"role": "user",
|
"role": "user",
|
||||||
|
|||||||
@ -3,7 +3,6 @@ import { sync as read } from "@polymech/fs/read";
|
|||||||
import { sync as exists } from "@polymech/fs/exists";
|
import { sync as exists } from "@polymech/fs/exists";
|
||||||
import { z } from "zod";
|
import { z } from "zod";
|
||||||
import { logger } from "./index.js";
|
import { logger } from "./index.js";
|
||||||
import { resolveVariables } from "@polymech/commons/variables"
|
|
||||||
import { OptionsSchema } from "@polymech/kbot-d"
|
import { OptionsSchema } from "@polymech/kbot-d"
|
||||||
|
|
||||||
const InstructionSchema = z.object({
|
const InstructionSchema = z.object({
|
||||||
|
|||||||
@ -25,9 +25,6 @@ export const filter = async (content: string, tpl: string = 'howto', opts: Props
|
|||||||
if (!templates[tpl]) {
|
if (!templates[tpl]) {
|
||||||
return content;
|
return content;
|
||||||
}
|
}
|
||||||
if(context==='howto'){
|
|
||||||
//debugger
|
|
||||||
}
|
|
||||||
const template = typeof templates[tpl] === 'function' ? templates[tpl]() : templates[tpl];
|
const template = typeof templates[tpl] === 'function' ? templates[tpl]() : templates[tpl];
|
||||||
const options = getFilterOptions(content, template, opts);
|
const options = getFilterOptions(content, template, opts);
|
||||||
const cache_key_obj = {
|
const cache_key_obj = {
|
||||||
|
|||||||
@ -4,7 +4,6 @@ import { resolve, template } from '@polymech/commons'
|
|||||||
import { sync as read } from '@polymech/fs/read'
|
import { sync as read } from '@polymech/fs/read'
|
||||||
import { sanitizeUri } from 'micromark-util-sanitize-uri'
|
import { sanitizeUri } from 'micromark-util-sanitize-uri'
|
||||||
|
|
||||||
|
|
||||||
// LLM
|
// LLM
|
||||||
export const LLM_CACHE = true
|
export const LLM_CACHE = true
|
||||||
|
|
||||||
|
|||||||
@ -105,28 +105,10 @@ const complete = async (item: IUser) => {
|
|||||||
const configPath = path.join(item_path(item), 'config.json')
|
const configPath = path.join(item_path(item), 'config.json')
|
||||||
const config = read(configPath, 'json') as IUser || {}
|
const config = read(configPath, 'json') as IUser || {}
|
||||||
// item = { ...item, ...config }
|
// item = { ...item, ...config }
|
||||||
|
|
||||||
if (!DIRECTORY_ANNOTATIONS) {
|
|
||||||
// return item
|
|
||||||
}
|
|
||||||
|
|
||||||
// commons: language, tone, bullshit filter, and a piece of love, just a bit, at least :)
|
// commons: language, tone, bullshit filter, and a piece of love, just a bit, at least :)
|
||||||
if (DIRECTORY_FILTER_LLM) {
|
if (DIRECTORY_FILTER_LLM) {
|
||||||
item.detail = await commons(item.detail || '')
|
item.detail = await commons(item.detail || '')
|
||||||
}
|
}
|
||||||
|
|
||||||
item.detail = await applyFilters(item.detail || '', [validateLinks])
|
|
||||||
|
|
||||||
// Generate keywords using the keywords template
|
|
||||||
if (DIRECTORY_ADD_RESOURCES) {
|
|
||||||
item.data = await applyFilters(item.data, default_filters_markdown);
|
|
||||||
write(path.join(item_path(item), 'resources.md'), item.data as string)
|
|
||||||
}
|
|
||||||
|
|
||||||
if (DIRECTORY_SEO_LLM) {
|
|
||||||
item.brief = await template_filter(item.detail, 'brief', TemplateContext.DIRECTORY);
|
|
||||||
}
|
|
||||||
|
|
||||||
item.detail = await applyFilters(item.detail || '', [validateLinks])
|
item.detail = await applyFilters(item.detail || '', [validateLinks])
|
||||||
|
|
||||||
return item
|
return item
|
||||||
|
|||||||
2
systems/research/gpt-researcher/.dockerignore
Normal file
@ -0,0 +1,2 @@
|
|||||||
|
.git
|
||||||
|
output/
|
||||||
38
systems/research/gpt-researcher/.github/ISSUE_TEMPLATE/bug_report.md
vendored
Normal file
@ -0,0 +1,38 @@
|
|||||||
|
---
|
||||||
|
name: Bug report
|
||||||
|
about: Create a report to help us improve
|
||||||
|
title: ''
|
||||||
|
labels: ''
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Describe the bug**
|
||||||
|
A clear and concise description of what the bug is.
|
||||||
|
|
||||||
|
**To Reproduce**
|
||||||
|
Steps to reproduce the behavior:
|
||||||
|
1. Go to '...'
|
||||||
|
2. Click on '....'
|
||||||
|
3. Scroll down to '....'
|
||||||
|
4. See error
|
||||||
|
|
||||||
|
**Expected behavior**
|
||||||
|
A clear and concise description of what you expected to happen.
|
||||||
|
|
||||||
|
**Screenshots**
|
||||||
|
If applicable, add screenshots to help explain your problem.
|
||||||
|
|
||||||
|
**Desktop (please complete the following information):**
|
||||||
|
- OS: [e.g. iOS]
|
||||||
|
- Browser [e.g. chrome, safari]
|
||||||
|
- Version [e.g. 22]
|
||||||
|
|
||||||
|
**Smartphone (please complete the following information):**
|
||||||
|
- Device: [e.g. iPhone6]
|
||||||
|
- OS: [e.g. iOS8.1]
|
||||||
|
- Browser [e.g. stock browser, safari]
|
||||||
|
- Version [e.g. 22]
|
||||||
|
|
||||||
|
**Additional context**
|
||||||
|
Add any other context about the problem here.
|
||||||
20
systems/research/gpt-researcher/.github/ISSUE_TEMPLATE/feature_request.md
vendored
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
name: Feature request
|
||||||
|
about: Suggest an idea for this project
|
||||||
|
title: ''
|
||||||
|
labels: ''
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Is your feature request related to a problem? Please describe.**
|
||||||
|
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
||||||
|
|
||||||
|
**Describe the solution you'd like**
|
||||||
|
A clear and concise description of what you want to happen.
|
||||||
|
|
||||||
|
**Describe alternatives you've considered**
|
||||||
|
A clear and concise description of any alternative solutions or features you've considered.
|
||||||
|
|
||||||
|
**Additional context**
|
||||||
|
Add any other context or screenshots about the feature request here.
|
||||||
15
systems/research/gpt-researcher/.github/dependabot.yml
vendored
Normal file
@ -0,0 +1,15 @@
|
|||||||
|
# To get started with Dependabot version updates, you'll need to specify which
|
||||||
|
# package ecosystems to update and where the package manifests are located.
|
||||||
|
# Please see the documentation for all configuration options:
|
||||||
|
# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
|
||||||
|
|
||||||
|
version: 2
|
||||||
|
updates:
|
||||||
|
- package-ecosystem: "pip" # See documentation for possible values
|
||||||
|
directory: "/" # Location of package manifests
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
|
- package-ecosystem: "docker"
|
||||||
|
directory: "/"
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
45
systems/research/gpt-researcher/.github/workflows/docker-build.yml
vendored
Normal file
@ -0,0 +1,45 @@
|
|||||||
|
name: GPTR tests
|
||||||
|
run-name: ${{ github.actor }} ran the GPTR tests flow
|
||||||
|
permissions:
|
||||||
|
contents: read
|
||||||
|
pull-requests: write
|
||||||
|
on:
|
||||||
|
workflow_dispatch: # Add this line to enable manual triggering
|
||||||
|
# pull_request:
|
||||||
|
# types: [opened, synchronize]
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
docker:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
environment: tests # Specify the environment to use for this job
|
||||||
|
env:
|
||||||
|
# Ensure these environment variables are set for the entire job
|
||||||
|
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||||
|
TAVILY_API_KEY: ${{ secrets.TAVILY_API_KEY }}
|
||||||
|
LANGCHAIN_API_KEY: ${{ secrets.LANGCHAIN_API_KEY }}
|
||||||
|
steps:
|
||||||
|
- name: Git checkout
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
|
||||||
|
- name: Set up QEMU
|
||||||
|
uses: docker/setup-qemu-action@v2
|
||||||
|
|
||||||
|
- name: Set up Docker Buildx
|
||||||
|
uses: docker/setup-buildx-action@v2
|
||||||
|
with:
|
||||||
|
driver: docker
|
||||||
|
|
||||||
|
# - name: Build Docker images
|
||||||
|
# uses: docker/build-push-action@v4
|
||||||
|
# with:
|
||||||
|
# push: false
|
||||||
|
# tags: gptresearcher/gpt-researcher:latest
|
||||||
|
# file: Dockerfile
|
||||||
|
|
||||||
|
- name: Set up Docker Compose
|
||||||
|
run: |
|
||||||
|
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
||||||
|
sudo chmod +x /usr/local/bin/docker-compose
|
||||||
|
- name: Run tests with Docker Compose
|
||||||
|
run: |
|
||||||
|
docker-compose --profile test run --rm gpt-researcher-tests
|
||||||
53
systems/research/gpt-researcher/.gitignore
vendored
Normal file
@ -0,0 +1,53 @@
|
|||||||
|
#Ignore env containing secrets
|
||||||
|
.env
|
||||||
|
.venv
|
||||||
|
.envrc
|
||||||
|
|
||||||
|
#Ignore Virtual Env
|
||||||
|
env/
|
||||||
|
venv/
|
||||||
|
.venv/
|
||||||
|
|
||||||
|
# Other Environments
|
||||||
|
ENV/
|
||||||
|
env.bak/
|
||||||
|
venv.bak/
|
||||||
|
|
||||||
|
#Ignore generated outputs
|
||||||
|
outputs/
|
||||||
|
*.lock
|
||||||
|
dist/
|
||||||
|
gpt_researcher.egg-info/
|
||||||
|
|
||||||
|
#Ignore my local docs
|
||||||
|
my-docs/
|
||||||
|
|
||||||
|
#Ignore pycache
|
||||||
|
**/__pycache__/
|
||||||
|
|
||||||
|
#Ignore mypy cache
|
||||||
|
.mypy_cache/
|
||||||
|
node_modules
|
||||||
|
.idea
|
||||||
|
.DS_Store
|
||||||
|
.docusaurus
|
||||||
|
build
|
||||||
|
docs/build
|
||||||
|
|
||||||
|
.vscode/launch.json
|
||||||
|
.langgraph-data/
|
||||||
|
.next/
|
||||||
|
package-lock.json
|
||||||
|
|
||||||
|
#Vim swp files
|
||||||
|
*.swp
|
||||||
|
|
||||||
|
# Log files
|
||||||
|
logs/
|
||||||
|
*.orig
|
||||||
|
*.log
|
||||||
|
server_log.txt
|
||||||
|
|
||||||
|
#Cursor Rules
|
||||||
|
.cursorrules
|
||||||
|
CURSOR_RULES.md
|
||||||
1
systems/research/gpt-researcher/.python-version
Normal file
@ -0,0 +1 @@
|
|||||||
|
3.11
|
||||||
123
systems/research/gpt-researcher/CODE_OF_CONDUCT.md
Normal file
@ -0,0 +1,123 @@
|
|||||||
|
# Contributor Covenant Code of Conduct
|
||||||
|
|
||||||
|
## Our Pledge
|
||||||
|
|
||||||
|
We, as members, contributors, and leaders, pledge to make participation in our
|
||||||
|
community a harassment-free experience for everyone, regardless of age, body
|
||||||
|
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||||
|
identity and expression, level of experience, education, socio-economic status,
|
||||||
|
nationality, personal appearance, race, religion, sexual identity, or
|
||||||
|
orientation.
|
||||||
|
|
||||||
|
We commit to acting and interacting in ways that contribute to an open, welcoming,
|
||||||
|
diverse, inclusive, and healthy community.
|
||||||
|
|
||||||
|
## Our Standards
|
||||||
|
|
||||||
|
Examples of behavior that contributes to a positive environment for our
|
||||||
|
community include:
|
||||||
|
|
||||||
|
- Demonstrating empathy and kindness toward others
|
||||||
|
- Being respectful of differing opinions, viewpoints, and experiences
|
||||||
|
- Giving and gracefully accepting constructive feedback
|
||||||
|
- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
|
||||||
|
- Focusing on what is best not just for us as individuals, but for the
|
||||||
|
overall community
|
||||||
|
|
||||||
|
Examples of unacceptable behavior include:
|
||||||
|
|
||||||
|
- The use of sexualized language or imagery, and sexual attention or
|
||||||
|
advances of any kind
|
||||||
|
- Trolling, insulting or derogatory comments, and personal or political attacks
|
||||||
|
- Public or private harassment
|
||||||
|
- Publishing others' private information, such as a physical or email address, without their explicit permission
|
||||||
|
- Other conduct that could reasonably be considered inappropriate in a professional setting
|
||||||
|
|
||||||
|
## Enforcement Responsibilities
|
||||||
|
|
||||||
|
Community leaders are responsible for clarifying and enforcing our standards of
|
||||||
|
acceptable behavior and will take appropriate and fair corrective action in
|
||||||
|
response to any behavior deemed inappropriate, threatening, offensive,
|
||||||
|
or harmful.
|
||||||
|
|
||||||
|
Community leaders have the right and responsibility to remove, edit, or reject
|
||||||
|
comments, commits, code, wiki edits, issues, and other contributions that do not
|
||||||
|
align with this Code of Conduct, and will communicate reasons for moderation
|
||||||
|
decisions when appropriate.
|
||||||
|
|
||||||
|
## Scope
|
||||||
|
|
||||||
|
This Code of Conduct applies to all community spaces and also applies when
|
||||||
|
an individual is officially representing the community in public spaces.
|
||||||
|
Examples include using an official email address, posting via an official
|
||||||
|
social media account, or acting as an appointed representative at an online or offline event.
|
||||||
|
|
||||||
|
## Enforcement
|
||||||
|
|
||||||
|
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||||
|
reported to the community leaders responsible for enforcement at
|
||||||
|
[Assaf.elovic@gmail.com](mailto:Assaf.elovic@gmail.com).
|
||||||
|
All complaints will be reviewed and investigated promptly and fairly.
|
||||||
|
|
||||||
|
All community leaders are obligated to respect the privacy and security of the
|
||||||
|
reporter of any incident.
|
||||||
|
|
||||||
|
## Enforcement Guidelines
|
||||||
|
|
||||||
|
Community leaders will follow these Community Impact Guidelines in determining
|
||||||
|
the consequences for any action they deem in violation of this Code of Conduct:
|
||||||
|
|
||||||
|
### 1. Correction
|
||||||
|
|
||||||
|
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||||
|
unprofessional or unwelcome in the community.
|
||||||
|
|
||||||
|
**Consequence**: A private, written warning from community leaders, providing
|
||||||
|
clarity around the nature of the violation and an explanation of why the
|
||||||
|
behavior was inappropriate. A public apology may be requested.
|
||||||
|
|
||||||
|
### 2. Warning
|
||||||
|
|
||||||
|
**Community Impact**: A violation through a single incident or series
|
||||||
|
of actions.
|
||||||
|
|
||||||
|
**Consequence**: A warning with consequences for continued behavior. No
|
||||||
|
interaction with the people involved, including unsolicited interaction with
|
||||||
|
those enforcing the Code of Conduct, for a specified period. This includes
|
||||||
|
avoiding interactions in community spaces and external channels like social media.
|
||||||
|
Violating these terms may lead to a temporary or permanent ban.
|
||||||
|
|
||||||
|
### 3. Temporary Ban
|
||||||
|
|
||||||
|
**Community Impact**: A serious violation of community standards, including
|
||||||
|
sustained inappropriate behavior.
|
||||||
|
|
||||||
|
**Consequence**: A temporary ban from any interaction or public
|
||||||
|
communication with the community for a specified period. No public or
|
||||||
|
private interaction with the people involved, including unsolicited interaction
|
||||||
|
with those enforcing the Code of Conduct, is allowed during this period.
|
||||||
|
Violating these terms may lead to a permanent ban.
|
||||||
|
|
||||||
|
### 4. Permanent Ban
|
||||||
|
|
||||||
|
**Community Impact**: Demonstrating a pattern of violation of community
|
||||||
|
standards, including sustained inappropriate behavior, harassment of an
|
||||||
|
individual, or aggression toward or disparagement of groups of individuals.
|
||||||
|
|
||||||
|
**Consequence**: A permanent ban from any public interaction within
|
||||||
|
the community.
|
||||||
|
|
||||||
|
## Attribution
|
||||||
|
|
||||||
|
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||||
|
version 2.0, available at
|
||||||
|
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||||
|
|
||||||
|
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||||
|
enforcement ladder](https://github.com/mozilla/diversity).
|
||||||
|
|
||||||
|
[homepage]: https://www.contributor-covenant.org
|
||||||
|
|
||||||
|
For answers to common questions about this code of conduct, see the FAQ at
|
||||||
|
https://www.contributor-covenant.org/faq. Translations are available at
|
||||||
|
https://www.contributor-covenant.org/translations.
|
||||||
42
systems/research/gpt-researcher/CONTRIBUTING.md
Normal file
@ -0,0 +1,42 @@
|
|||||||
|
# Contributing to GPT Researcher
|
||||||
|
|
||||||
|
First off, we'd like to welcome you and thank you for your interest and effort in contributing to our open-source project ❤️. Contributions of all forms are welcome—from new features and bug fixes to documentation and more.
|
||||||
|
|
||||||
|
We are on a mission to build the #1 AI agent for comprehensive, unbiased, and factual research online, and we need your support to achieve this grand vision.
|
||||||
|
|
||||||
|
Please take a moment to review this document to make the contribution process easy and effective for everyone involved.
|
||||||
|
|
||||||
|
## Reporting Issues
|
||||||
|
|
||||||
|
If you come across any issue or have an idea for an improvement, don't hesitate to create an issue on GitHub. Describe your problem in sufficient detail, providing as much relevant information as possible. This way, we can reproduce the issue before attempting to fix it or respond appropriately.
|
||||||
|
|
||||||
|
## Contributing Code
|
||||||
|
|
||||||
|
1. **Fork the repository and create your branch from `master`.**
|
||||||
|
If it’s not an urgent bug fix, branch from `master` and work on the feature or fix there.
|
||||||
|
|
||||||
|
2. **Make your changes.**
|
||||||
|
Implement your changes following best practices for coding in the project's language.
|
||||||
|
|
||||||
|
3. **Test your changes.**
|
||||||
|
Ensure that your changes pass all tests if any exist. If the project doesn’t have automated tests, test your changes manually to confirm they behave as expected.
|
||||||
|
|
||||||
|
4. **Follow the coding style.**
|
||||||
|
Ensure your code adheres to the coding conventions used throughout the project, including indentation, accurate comments, etc.
|
||||||
|
|
||||||
|
5. **Commit your changes.**
|
||||||
|
Make your Git commits informative and concise. This is very helpful for others when they look at the Git log.
|
||||||
|
|
||||||
|
6. **Push to your fork and submit a pull request.**
|
||||||
|
When your work is ready and passes tests, push your branch to your fork of the repository and submit a pull request from there.
|
||||||
|
|
||||||
|
7. **Pat yourself on the back and wait for review.**
|
||||||
|
Your work is done, congratulations! Now sit tight. The project maintainers will review your submission as soon as possible. They might suggest changes or ask for improvements. Both constructive conversation and patience are key to the collaboration process.
|
||||||
|
|
||||||
|
## Documentation
|
||||||
|
|
||||||
|
If you would like to contribute to the project's documentation, please follow the same steps: fork the repository, make your changes, test them, and submit a pull request.
|
||||||
|
|
||||||
|
Documentation is a vital part of any software. It's not just about having good code; ensuring that users and contributors understand what's going on, how to use the software, or how to contribute is crucial.
|
||||||
|
|
||||||
|
We're grateful for all our contributors, and we look forward to building the world's leading AI research agent hand-in-hand with you. Let's harness the power of open source and AI to change the world together!
|
||||||
54
systems/research/gpt-researcher/Dockerfile
Normal file
@ -0,0 +1,54 @@
|
|||||||
|
# Stage 1: Browser and build tools installation
|
||||||
|
FROM python:3.11.4-slim-bullseye AS install-browser
|
||||||
|
|
||||||
|
# Install Chromium, Chromedriver, Firefox, Geckodriver, and build tools in one layer
|
||||||
|
RUN apt-get update \
|
||||||
|
&& apt-get install -y gnupg wget ca-certificates --no-install-recommends \
|
||||||
|
&& wget -qO - https://dl.google.com/linux/linux_signing_key.pub | apt-key add - \
|
||||||
|
&& echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" > /etc/apt/sources.list.d/google-chrome.list \
|
||||||
|
&& apt-get update \
|
||||||
|
&& apt-get install -y google-chrome-stable chromium-driver \
|
||||||
|
&& google-chrome --version && chromedriver --version \
|
||||||
|
&& apt-get install -y --no-install-recommends firefox-esr build-essential \
|
||||||
|
&& wget https://github.com/mozilla/geckodriver/releases/download/v0.33.0/geckodriver-v0.33.0-linux64.tar.gz \
|
||||||
|
&& tar -xvzf geckodriver-v0.33.0-linux64.tar.gz \
|
||||||
|
&& chmod +x geckodriver \
|
||||||
|
&& mv geckodriver /usr/local/bin/ \
|
||||||
|
&& rm geckodriver-v0.33.0-linux64.tar.gz \
|
||||||
|
&& rm -rf /var/lib/apt/lists/* # Clean up apt lists to reduce image size
|
||||||
|
|
||||||
|
# Stage 2: Python dependencies installation
|
||||||
|
FROM install-browser AS gpt-researcher-install
|
||||||
|
|
||||||
|
ENV PIP_ROOT_USER_ACTION=ignore
|
||||||
|
WORKDIR /usr/src/app
|
||||||
|
|
||||||
|
# Copy and install Python dependencies in a single layer to optimize cache usage
|
||||||
|
COPY ./requirements.txt ./requirements.txt
|
||||||
|
COPY ./multi_agents/requirements.txt ./multi_agents/requirements.txt
|
||||||
|
|
||||||
|
RUN pip install --no-cache-dir -r requirements.txt && \
|
||||||
|
pip install --no-cache-dir -r multi_agents/requirements.txt
|
||||||
|
|
||||||
|
# Stage 3: Final stage with non-root user and app
|
||||||
|
FROM gpt-researcher-install AS gpt-researcher
|
||||||
|
|
||||||
|
# Create a non-root user for security
|
||||||
|
RUN useradd -ms /bin/bash gpt-researcher && \
|
||||||
|
chown -R gpt-researcher:gpt-researcher /usr/src/app && \
|
||||||
|
# Add these lines to create and set permissions for outputs directory
|
||||||
|
mkdir -p /usr/src/app/outputs && \
|
||||||
|
chown -R gpt-researcher:gpt-researcher /usr/src/app/outputs && \
|
||||||
|
chmod 777 /usr/src/app/outputs
|
||||||
|
|
||||||
|
USER gpt-researcher
|
||||||
|
WORKDIR /usr/src/app
|
||||||
|
|
||||||
|
# Copy the rest of the application files with proper ownership
|
||||||
|
COPY --chown=gpt-researcher:gpt-researcher ./ ./
|
||||||
|
|
||||||
|
# Expose the application's port
|
||||||
|
EXPOSE 9000
|
||||||
|
|
||||||
|
# Define the default command to run the application
|
||||||
|
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "9000"]
|
||||||
201
systems/research/gpt-researcher/LICENSE
Normal file
@ -0,0 +1,201 @@
|
|||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright [yyyy] [name of copyright owner]
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
1
systems/research/gpt-researcher/Procfile
Normal file
@ -0,0 +1 @@
|
|||||||
|
web: python -m uvicorn backend.server.server:app --host=0.0.0.0 --port=${PORT}
|
||||||
159
systems/research/gpt-researcher/README-ja_JP.md
Normal file
@ -0,0 +1,159 @@
|
|||||||
|
<div align="center">
|
||||||
|
<!--<h1 style="display: flex; align-items: center; gap: 10px;">
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/a45bac7c-092c-42e5-8eb6-69acbf20dde5" alt="Logo" width="25">
|
||||||
|
GPT Researcher
|
||||||
|
</h1>-->
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/20af8286-b386-44a5-9a83-3be1365139c3" alt="Logo" width="80">
|
||||||
|
|
||||||
|
|
||||||
|
####
|
||||||
|
|
||||||
|
[](https://gptr.dev)
|
||||||
|
[](https://docs.gptr.dev)
|
||||||
|
[](https://discord.gg/QgZXvJAccX)
|
||||||
|
|
||||||
|
[](https://badge.fury.io/py/gpt-researcher)
|
||||||
|

|
||||||
|
[](https://colab.research.google.com/github/assafelovic/gpt-researcher/blob/master/docs/docs/examples/pip-run.ipynb)
|
||||||
|
[](https://hub.docker.com/r/gptresearcher/gpt-researcher)
|
||||||
|
[](https://twitter.com/assaf_elovic)
|
||||||
|
|
||||||
|
[English](README.md) |
|
||||||
|
[中文](README-zh_CN.md) |
|
||||||
|
[日本語](README-ja_JP.md) |
|
||||||
|
[한국어](README-ko_KR.md)
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# 🔎 GPT Researcher
|
||||||
|
|
||||||
|
**GPT Researcher は、さまざまなタスクに対する包括的なオンラインリサーチのために設計された自律エージェントです。**
|
||||||
|
|
||||||
|
このエージェントは、詳細で事実に基づいた偏りのない研究レポートを生成することができ、関連するリソース、アウトライン、およびレッスンに焦点を当てるためのカスタマイズオプションを提供します。最近の [Plan-and-Solve](https://arxiv.org/abs/2305.04091) および [RAG](https://arxiv.org/abs/2005.11401) 論文に触発され、GPT Researcher は速度、決定論、および信頼性の問題に対処し、同期操作ではなく並列化されたエージェント作業を通じてより安定したパフォーマンスと高速化を提供します。
|
||||||
|
|
||||||
|
**私たちの使命は、AIの力を活用して、個人や組織に正確で偏りのない事実に基づいた情報を提供することです。**
|
||||||
|
|
||||||
|
## なぜGPT Researcherなのか?
|
||||||
|
|
||||||
|
- 手動の研究タスクで客観的な結論を形成するには時間がかかることがあり、適切なリソースと情報を見つけるのに数週間かかることもあります。
|
||||||
|
- 現在のLLMは過去の情報に基づいて訓練されており、幻覚のリスクが高く、研究タスクにはほとんど役に立ちません。
|
||||||
|
- 現在のLLMは短いトークン出力に制限されており、長く詳細な研究レポート(2,000語以上)には不十分です。
|
||||||
|
- Web検索を可能にするサービス(ChatGPT + Webプラグインなど)は、限られたリソースとコンテンツのみを考慮し、場合によっては表面的で偏った回答をもたらします。
|
||||||
|
- Webソースの選択のみを使用すると、研究タスクの正しい結論を導く際にバイアスが生じる可能性があります。
|
||||||
|
|
||||||
|
## アーキテクチャ
|
||||||
|
主なアイデアは、「プランナー」と「実行」エージェントを実行することであり、プランナーは研究する質問を生成し、実行エージェントは生成された各研究質問に基づいて最も関連性の高い情報を探します。最後に、プランナーはすべての関連情報をフィルタリングおよび集約し、研究レポートを作成します。<br /> <br />
|
||||||
|
エージェントは、研究タスクを完了するために gpt-4o-mini と gpt-4o(128K コンテキスト)の両方を活用します。必要に応じてそれぞれを使用することでコストを最適化します。**平均的な研究タスクは完了するのに約3分かかり、コストは約0.1ドルです**。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img align="center" height="500" src="https://cowriter-images.s3.amazonaws.com/architecture.png">
|
||||||
|
</div>
|
||||||
|
|
||||||
|
|
||||||
|
詳細説明:
|
||||||
|
* 研究クエリまたはタスクに基づいて特定のドメインエージェントを作成します。
|
||||||
|
* 研究タスクに対する客観的な意見を形成する一連の研究質問を生成します。
|
||||||
|
* 各研究質問に対して、与えられたタスクに関連する情報をオンラインリソースから収集するクローラーエージェントをトリガーします。
|
||||||
|
* 各収集されたリソースについて、関連情報に基づいて要約し、そのソースを追跡します。
|
||||||
|
* 最後に、すべての要約されたソースをフィルタリングおよび集約し、最終的な研究レポートを生成します。
|
||||||
|
|
||||||
|
## デモ
|
||||||
|
https://github.com/assafelovic/gpt-researcher/assets/13554167/a00c89a6-a295-4dd0-b58d-098a31c40fda
|
||||||
|
|
||||||
|
## チュートリアル
|
||||||
|
- [動作原理](https://docs.gptr.dev/blog/building-gpt-researcher)
|
||||||
|
- [インストール方法](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
|
||||||
|
- [ライブデモ](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
|
||||||
|
|
||||||
|
## 特徴
|
||||||
|
- 📝 研究、アウトライン、リソース、レッスンレポートを生成
|
||||||
|
- 🌐 各研究で20以上のWebソースを集約し、客観的で事実に基づいた結論を形成
|
||||||
|
- 🖥️ 使いやすいWebインターフェース(HTML/CSS/JS)を含む
|
||||||
|
- 🔍 JavaScriptサポート付きのWebソースをスクレイピング
|
||||||
|
- 📂 訪問および使用されたWebソースのコンテキストを追跡
|
||||||
|
- 📄 研究レポートをPDF、Wordなどにエクスポート
|
||||||
|
|
||||||
|
## 📖 ドキュメント
|
||||||
|
|
||||||
|
完全なドキュメントについては、[こちら](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started)を参照してください:
|
||||||
|
|
||||||
|
- 入門(インストール、環境設定、簡単な例)
|
||||||
|
- 操作例(デモ、統合、dockerサポート)
|
||||||
|
- 参考資料(API完全ドキュメント)
|
||||||
|
- Tavilyアプリケーションインターフェースの統合(コア概念の高度な説明)
|
||||||
|
|
||||||
|
## クイックスタート
|
||||||
|
> **ステップ 0** - Python 3.11 以降をインストールします。[こちら](https://www.tutorialsteacher.com/python/install-python)を参照して、ステップバイステップのガイドを確認してください。
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **ステップ 1** - プロジェクトをダウンロードします
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ git clone https://github.com/assafelovic/gpt-researcher.git
|
||||||
|
$ cd gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **ステップ2** - 依存関係をインストールします
|
||||||
|
```bash
|
||||||
|
$ pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **ステップ 3** - OpenAI キーと Tavily API キーを使用して .env ファイルを作成するか、直接エクスポートします
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ export OPENAI_API_KEY={Your OpenAI API Key here}
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
$ export TAVILY_API_KEY={Your Tavily API Key here}
|
||||||
|
```
|
||||||
|
|
||||||
|
- **LLMには、[OpenAI GPT](https://platform.openai.com/docs/guides/gpt) を使用することをお勧めします**が、[Langchain Adapter](https://python.langchain.com/docs/guides/adapters/openai) がサポートする他の LLM モデル(オープンソースを含む)を使用することもできます。llm モデルとプロバイダーを config/config.py で変更するだけです。[このガイド](https://python.langchain.com/docs/integrations/llms/) に従って、LLM を Langchain と統合する方法を学んでください。
|
||||||
|
- **検索エンジンには、[Tavily Search API](https://app.tavily.com)(LLM 用に最適化されています)を使用することをお勧めします**が、他の検索エンジンを選択することもできます。config/config.py で検索プロバイダーを「duckduckgo」、「googleAPI」、「googleSerp」、「searchapi」、「searx」に変更するだけです。次に、config.py ファイルに対応する env API キーを追加します。
|
||||||
|
- **最適なパフォーマンスを得るために、[OpenAI GPT](https://platform.openai.com/docs/guides/gpt) モデルと [Tavily Search API](https://app.tavily.com) を使用することを強くお勧めします。**
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **ステップ 4** - FastAPI を使用してエージェントを実行します
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ uvicorn main:app --reload
|
||||||
|
```
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **ステップ 5** - 任意のブラウザで http://localhost:8000 にアクセスして、リサーチを楽しんでください!
|
||||||
|
|
||||||
|
Docker の使い方や機能とサービスの詳細については、[ドキュメント](https://docs.gptr.dev) ページをご覧ください。
|
||||||
|
|
||||||
|
## 🚀 貢献
|
||||||
|
私たちは貢献を大歓迎します!興味がある場合は、[貢献](CONTRIBUTING.md) をご覧ください。
|
||||||
|
|
||||||
|
私たちの[ロードマップ](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap) ページを確認し、私たちの使命に参加することに興味がある場合は、[Discord コミュニティ](https://discord.gg/QgZXvJAccX) を通じてお問い合わせください。
|
||||||
|
|
||||||
|
## ✉️ サポート / お問い合わせ
|
||||||
|
- [コミュニティディスカッション](https://discord.gg/spBgZmm3Xe)
|
||||||
|
- 私たちのメール: support@tavily.com
|
||||||
|
|
||||||
|
## 🛡 免責事項
|
||||||
|
|
||||||
|
このプロジェクト「GPT Researcher」は実験的なアプリケーションであり、明示または黙示のいかなる保証もなく「現状のまま」提供されます。私たちは学術目的のためにMITライセンスの下でコードを共有しています。ここに記載されている内容は学術的なアドバイスではなく、学術論文や研究論文での使用を推奨するものではありません。
|
||||||
|
|
||||||
|
私たちの客観的な研究主張に対する見解:
|
||||||
|
1. 私たちのスクレイピングシステムの主な目的は、不正確な事実を減らすことです。どうやって解決するのか?私たちがスクレイピングするサイトが多ければ多いほど、誤ったデータの可能性は低くなります。各研究で20の情報を収集し、それらがすべて間違っている可能性は非常に低いです。
|
||||||
|
2. 私たちの目標はバイアスを排除することではなく、可能な限りバイアスを減らすことです。**私たちはここでコミュニティとして最も効果的な人間と機械の相互作用を探求しています**。
|
||||||
|
3. 研究プロセスでは、人々も自分が研究しているトピックに対してすでに意見を持っているため、バイアスがかかりやすいです。このツールは多くの意見を収集し、偏った人が決して読まないであろう多様な見解を均等に説明します。
|
||||||
|
|
||||||
|
**GPT-4 言語モデルの使用は、トークンの使用により高額な費用がかかる可能性があることに注意してください**。このプロジェクトを利用することで、トークンの使用状況と関連する費用を監視および管理する責任があることを認めたことになります。OpenAI API の使用状況を定期的に確認し、予期しない料金が発生しないように必要な制限やアラートを設定することを強くお勧めします。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://star-history.com/#assafelovic/gpt-researcher">
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date&theme=dark" />
|
||||||
|
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
</picture>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
242
systems/research/gpt-researcher/README-ko_KR.md
Normal file
@ -0,0 +1,242 @@
|
|||||||
|
<div align="center">
|
||||||
|
<!--<h1 style="display: flex; align-items: center; gap: 10px;">
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/a45bac7c-092c-42e5-8eb6-69acbf20dde5" alt="Logo" width="25">
|
||||||
|
GPT Researcher
|
||||||
|
</h1>-->
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/20af8286-b386-44a5-9a83-3be1365139c3" alt="Logo" width="80">
|
||||||
|
|
||||||
|
|
||||||
|
####
|
||||||
|
|
||||||
|
[](https://gptr.dev)
|
||||||
|
[](https://docs.gptr.dev)
|
||||||
|
[](https://discord.gg/QgZXvJAccX)
|
||||||
|
|
||||||
|
[](https://badge.fury.io/py/gpt-researcher)
|
||||||
|

|
||||||
|
[](https://colab.research.google.com/github/assafelovic/gpt-researcher/blob/master/docs/docs/examples/pip-run.ipynb)
|
||||||
|
[](https://hub.docker.com/r/gptresearcher/gpt-researcher)
|
||||||
|
[](https://twitter.com/assaf_elovic)
|
||||||
|
|
||||||
|
[English](README.md) |
|
||||||
|
[中文](README-zh_CN.md) |
|
||||||
|
[日本語](README-ja_JP.md) |
|
||||||
|
[한국어](README-ko_KR.md)
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# 🔎 GPT Researcher
|
||||||
|
|
||||||
|
**GPT Researcher는 다양한 작업을 대해 포괄적인 온라인 연구를 수행하도록 설계된 자율 에이전트입니다.**
|
||||||
|
|
||||||
|
이 에이전트는 세부적이고 사실에 기반하며 편견 없는 연구 보고서를 생성할 수 있으며, 관련 리소스와 개요에 초점을 맞춘 맞춤형 옵션을 제공합니다. 최근 발표된 [Plan-and-Solve](https://arxiv.org/abs/2305.04091) 및 [RAG](https://arxiv.org/abs/2005.11401) 논문에서 영감을 받아 GPT Researcher는 잘못된 정보, 속도, 결정론적 접근 방식, 신뢰성 문제를 해결하고, 동기화 작업이 아닌 병렬 에이전트 작업을 통해 더 안정적이고 빠른 성능을 제공합니다.
|
||||||
|
|
||||||
|
**우리의 목표는 AI의 힘을 활용하여 개인과 조직에게 정확하고 편향 없는 사실에 기반한 정보를 제공하는 것입니다.**
|
||||||
|
|
||||||
|
## 왜 GPT Researcher인가?
|
||||||
|
|
||||||
|
- 직접 수행하는 연구 과정은 객관적인 결론을 도출하는 데 시간이 오래 걸리며, 적절한 리소스와 정보를 찾는 데 몇 주가 걸릴 수 있습니다.
|
||||||
|
- 현재의 대규모 언어 모델(LLM)은 과거 정보에 기반해 훈련되었으며, 환각 현상이 발생할 위험이 높아 연구 작업에는 적합하지 않습니다.
|
||||||
|
- 현재 LLM은 짧은 토큰 출력으로 제한되며, 2,000단어 이상의 길고 자세한 연구 보고서를 작성하는 데는 충분하지 않습니다.
|
||||||
|
- 웹 검색을 지원하는 서비스(예: ChatGPT 또는 Perplexity)는 제한된 리소스와 콘텐츠만을 고려하여 경우에 따라 피상적이고 편향된 답변을 제공합니다.
|
||||||
|
- 웹 소스만을 사용하면 연구 작업에서 올바른 결론을 도출할 때 편향이 발생할 수 있습니다.
|
||||||
|
|
||||||
|
## 데모
|
||||||
|
https://github.com/user-attachments/assets/092e9e71-7e27-475d-8c4f-9dddd28934a3
|
||||||
|
|
||||||
|
## 아키텍처
|
||||||
|
주요 아이디어는 "플래너"와 "실행" 에이전트를 실행하는 것으로, 플래너는 연구할 질문을 생성하고, 실행 에이전트는 생성된 각 연구 질문에 따라 가장 관련성 높은 정보를 찾습니다. 마지막으로 플래너는 모든 관련 정보를 필터링하고 집계하여 연구 보고서를 작성합니다.
|
||||||
|
<br /> <br />
|
||||||
|
에이전트는 `gpt-4o-mini`와 `gpt-4o`(128K 컨텍스트)를 활용하여 연구 작업을 완료합니다. 필요에 따라 각각을 사용하여 비용을 최적화합니다. **평균 연구 작업은 약 2분이 소요되며, 비용은 약 $0.005입니다.**.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img align="center" height="600" src="https://github.com/assafelovic/gpt-researcher/assets/13554167/4ac896fd-63ab-4b77-9688-ff62aafcc527">
|
||||||
|
</div>
|
||||||
|
|
||||||
|
구체적으로:
|
||||||
|
* 연구 쿼리 또는 작업을 기반으로 도메인별 에이전트를 생성합니다.
|
||||||
|
* 주어진 작업에 대해 객관적인 의견을 형성할 수 있는 일련의 연구 질문을 생성합니다.
|
||||||
|
* 각 연구 질문에 대해 크롤러 에이전트를 실행하여 작업과 관련된 정보를 온라인 리소스에서 수집합니다.
|
||||||
|
* 수집된 각 리소스에서 관련 정보를 요약하고 출처를 기록합니다.
|
||||||
|
* 마지막으로, 요약된 모든 정보를 필터링하고 집계하여 최종 연구 보고서를 생성합니다.
|
||||||
|
|
||||||
|
## 튜토리얼
|
||||||
|
- [동작원리](https://docs.gptr.dev/blog/building-gpt-researcher)
|
||||||
|
- [설치방법](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
|
||||||
|
- [라이브 데모](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
|
||||||
|
|
||||||
|
|
||||||
|
## 기능
|
||||||
|
- 📝 로컬 문서 및 웹 소스를 사용하여 연구, 개요, 리소스 및 학습 보고서 생성
|
||||||
|
- 📜 2,000단어 이상의 길고 상세한 연구 보고서 생성 가능
|
||||||
|
- 🌐 연구당 20개 이상의 웹 소스를 집계하여 객관적이고 사실에 기반한 결론 도출
|
||||||
|
- 🖥️ 경량 HTML/CSS/JS와 프로덕션용 (NextJS + Tailwind) UX/UI 포함
|
||||||
|
- 🔍 자바스크립트 지원 웹 소스 스크래핑 기능
|
||||||
|
- 📂 연구 과정에서 맥락과 메모리 추적 및 유지
|
||||||
|
- 📄 연구 보고서를 PDF, Word 등으로 내보내기 지원
|
||||||
|
|
||||||
|
## 📖 문서
|
||||||
|
|
||||||
|
전체 문서(설치, 환경 설정, 간단한 예시)를 보려면 [여기](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started)를 참조하세요.
|
||||||
|
|
||||||
|
- 시작하기 (설치, 환경 설정, 간단한 예시)
|
||||||
|
- 맞춤 설정 및 구성
|
||||||
|
- 사용 방법 예시 (데모, 통합, 도커 지원)
|
||||||
|
- 참고자료 (전체 API 문서)
|
||||||
|
|
||||||
|
## ⚙️ 시작하기
|
||||||
|
### 설치
|
||||||
|
> **1단계** - Python 3.11 또는 그 이상의 버전을 설치하세요. [여기](https://www.tutorialsteacher.com/python/install-python)를 참조하여 단계별 가이드를 확인하세요.
|
||||||
|
|
||||||
|
> **2단계** - 프로젝트를 다운로드하고 해당 디렉토리로 이동하세요.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/assafelovic/gpt-researcher.git
|
||||||
|
cd gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
> **3단계** - 두 가지 방법으로 API 키를 설정하세요: 직접 export하거나 `.env` 파일에 저장하세요.
|
||||||
|
|
||||||
|
Linux/Windows에서 임시 설정을 하려면 export 방법을 사용하세요:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY={OpenAI API 키 입력}
|
||||||
|
export TAVILY_API_KEY={Tavily API 키 입력}
|
||||||
|
```
|
||||||
|
|
||||||
|
더 영구적인 설정을 원한다면, 현재의 `gpt-researcher` 디렉토리에 `.env` 파일을 생성하고 환경 변수를 입력하세요 (export 없이).
|
||||||
|
|
||||||
|
- 기본 LLM은 [GPT](https://platform.openai.com/docs/guides/gpt)이지만, `claude`, `ollama3`, `gemini`, `mistral` 등 다른 LLM도 사용할 수 있습니다. LLM 제공자를 변경하는 방법은 [LLMs 문서](https://docs.gptr.dev/docs/gpt-researcher/llms/llms)를 참조하세요. 이 프로젝트는 OpenAI GPT 모델에 최적화되어 있습니다.
|
||||||
|
- 기본 검색기는 [Tavily](https://app.tavily.com)이지만, `duckduckgo`, `google`, `bing`, `searchapi`, `serper`, `searx`, `arxiv`, `exa` 등의 검색기를 사용할 수 있습니다. 검색 제공자를 변경하는 방법은 [검색기 문서](https://docs.gptr.dev/docs/gpt-researcher/retrievers)를 참조하세요.
|
||||||
|
|
||||||
|
### 빠른 시작
|
||||||
|
|
||||||
|
> **1단계** - 필요한 종속성 설치
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
> **2단계** - FastAPI로 에이전트 실행
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m uvicorn main:app --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
> **3단계** - 브라우저에서 http://localhost:8000 으로 이동하여 연구를 시작하세요!
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
**[Poetry](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started#poetry) 또는 [가상 환경](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started#virtual-environment)에 대해 배우고 싶다면, [문서](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started)를 참조하세요.**
|
||||||
|
|
||||||
|
### PIP 패키지로 실행하기
|
||||||
|
```bash
|
||||||
|
pip install gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
...
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
query = "왜 Nvidia 주식이 오르고 있나요?"
|
||||||
|
researcher = GPTResearcher(query=query, report_type="research_report")
|
||||||
|
# 주어진 질문에 대한 연구 수행
|
||||||
|
research_result = await researcher.conduct_research()
|
||||||
|
# 보고서 작성
|
||||||
|
report = await researcher.write_report()
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
**더 많은 예제와 구성 옵션은 [PIP 문서](https://docs.gptr.dev/docs/gpt-researcher/gptr/pip-package)를 참조하세요.**
|
||||||
|
|
||||||
|
## Docker로 실행
|
||||||
|
|
||||||
|
> **1단계** - [Docker 설치](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started-with-docker)
|
||||||
|
|
||||||
|
> **2단계** - `.env.example` 파일을 복사하고 API 키를 추가한 후, 파일을 `.env`로 저장하세요.
|
||||||
|
|
||||||
|
> **3단계** - docker-compose 파일에서 실행하고 싶지 않은 서비스를 주석 처리하세요.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker-compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
> **4단계** - docker-compose 파일에서 아무 것도 주석 처리하지 않았다면, 기본적으로 두 가지 프로세스가 시작됩니다:
|
||||||
|
- localhost:8000에서 실행 중인 Python 서버<br>
|
||||||
|
- localhost:3000에서 실행 중인 React 앱<br>
|
||||||
|
|
||||||
|
브라우저에서 localhost:3000으로 이동하여 연구를 시작하세요!
|
||||||
|
|
||||||
|
## 📄 로컬 문서로 연구하기
|
||||||
|
|
||||||
|
GPT Researcher를 사용하여 로컬 문서를 기반으로 연구 작업을 수행할 수 있습니다. 현재 지원되는 파일 형식은 PDF, 일반 텍스트, CSV, Excel, Markdown, PowerPoint, Word 문서입니다.
|
||||||
|
|
||||||
|
1단계: `DOC_PATH` 환경 변수를 설정하여 문서가 있는 폴더를 지정하세요.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export DOC_PATH="./my-docs"
|
||||||
|
```
|
||||||
|
|
||||||
|
2단계:
|
||||||
|
- 프론트엔드 앱을 localhost:8000에서 실행 중이라면, "Report Source" 드롭다운 옵션에서 "My Documents"를 선택하세요.
|
||||||
|
- GPT Researcher를 [PIP 패키지](https://docs.tavily.com/guides/gpt-researcher/gpt-researcher#pip-package)로 실행 중이라면, `report_source` 인수를 "local"로 설정하여 `GPTResearcher` 클래스를 인스턴스화하세요. [코드 예제](https://docs.gptr.dev/docs/gpt-researcher/context/tailored-research)를 참조하세요.
|
||||||
|
|
||||||
|
## 👪 다중 에이전트 어시스턴트
|
||||||
|
|
||||||
|
AI가 프롬프트 엔지니어링 및 RAG에서 다중 에이전트 시스템으로 발전함에 따라, 우리는 [LangGraph](https://python.langchain.com/v0.1/docs/langgraph/)로 구축된 새로운 다중 에이전트 어시스턴트를 소개합니다.
|
||||||
|
|
||||||
|
LangGraph를 사용하면 여러 에이전트의 전문 기술을 활용하여 연구 과정의 깊이와 질을 크게 향상시킬 수 있습니다. 최근 [STORM](https://arxiv.org/abs/2402.14207) 논문에서 영감을 받아, 이 프로젝트는 AI 에이전트 팀이 주제에 대한 연구를 계획에서 출판까지 함께 수행하는 방법을 보여줍니다.
|
||||||
|
|
||||||
|
평균 실행은 5-6 페이지 분량의 연구 보고서를 PDF, Docx, Markdown 형식으로 생성합니다.
|
||||||
|
|
||||||
|
[여기](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents)에서 확인하거나 [문서](https://docs.gptr.dev/docs/gpt-researcher/multi_agents/langgraph)에서 자세한 내용을 참조하세요.
|
||||||
|
|
||||||
|
## 🖥️ 프론트엔드 애플리케이션
|
||||||
|
|
||||||
|
GPT-Researcher는 사용자 경험을 개선하고 연구 프로세스를 간소화하기 위해 향상된 프론트엔드를 제공합니다. 프론트엔드는 다음과 같은 기능을 제공합니다:
|
||||||
|
|
||||||
|
- 연구 쿼리를 입력할 수 있는 직관적인 인터페이스
|
||||||
|
- 연구 작업의 실시간 진행 상황 추적
|
||||||
|
- 연구 결과의 대화형 디스플레이
|
||||||
|
- 맞춤형 연구 경험을 위한 설정 가능
|
||||||
|
|
||||||
|
두 가지 배포 옵션이 있습니다:
|
||||||
|
1. FastAPI로 제공되는 경량 정적 프론트엔드
|
||||||
|
2. 고급 기능을 제공하는 NextJS 애플리케이션
|
||||||
|
|
||||||
|
프론트엔드 기능에 대한 자세한 설치 방법 및 정보를 원하시면 [문서 페이지](https://docs.gptr.dev/docs/gpt-researcher/frontend/introduction)를 참조하세요.
|
||||||
|
|
||||||
|
## 🚀 기여하기
|
||||||
|
우리는 기여를 적극 환영합니다! 관심이 있다면 [기여 가이드](https://github.com/assafelovic/gpt-researcher/blob/master/CONTRIBUTING.md)를 확인해 주세요.
|
||||||
|
|
||||||
|
[로드맵](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap) 페이지를 확인하고, 우리 [Discord 커뮤니티](https://discord.gg/QgZXvJAccX)에 가입하여 우리의 목표에 함께 참여해 주세요.
|
||||||
|
<a href="https://github.com/assafelovic/gpt-researcher/graphs/contributors">
|
||||||
|
<img src="https://contrib.rocks/image?repo=assafelovic/gpt-researcher" />
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## ✉️ 지원 / 문의
|
||||||
|
- [커뮤니티 Discord](https://discord.gg/spBgZmm3Xe)
|
||||||
|
- 저자 이메일: assaf.elovic@gmail.com
|
||||||
|
|
||||||
|
## 🛡️ 면책 조항
|
||||||
|
|
||||||
|
이 프로젝트인 GPT Researcher는 실험적인 응용 프로그램이며, 명시적이거나 묵시적인 보증 없이 "있는 그대로" 제공됩니다. 우리는 이 코드를 학술적 목적으로 Apache 2 라이선스 하에 공유하고 있습니다. 여기에 있는 것은 학술적 조언이 아니며, 학술 또는 연구 논문에 사용하는 것을 권장하지 않습니다.
|
||||||
|
|
||||||
|
편향되지 않은 연구 주장에 대한 우리의 견해:
|
||||||
|
1. GPT Researcher의 주요 목표는 잘못된 정보와 편향된 사실을 줄이는 것입니다. 그 방법은 무엇일까요? 우리는 더 많은 사이트를 스크래핑할수록 잘못된 데이터의 가능성이 줄어든다고 가정합니다. 여러 사이트에서 정보를 스크래핑하고 가장 빈번한 정보를 선택하면, 모든 정보가 틀릴 확률은 매우 낮습니다.
|
||||||
|
2. 우리는 편향을 완전히 제거하려고 하지는 않지만, 가능한 한 줄이는 것을 목표로 합니다. **우리는 인간과 LLM의 가장 효과적인 상호작용을 찾기 위한 커뮤니티입니다.**
|
||||||
|
3. 연구에서 사람들도 이미 자신이 연구하는 주제에 대해 의견을 가지고 있기 때문에 편향되는 경향이 있습니다. 이 도구는 많은 의견을 스크래핑하며, 편향된 사람이라면 결코 읽지 않았을 다양한 견해를 고르게 설명합니다.
|
||||||
|
|
||||||
|
**GPT-4 모델을 사용할 경우, 토큰 사용량 때문에 비용이 많이 들 수 있습니다.** 이 프로젝트를 사용하는 경우, 자신의 토큰 사용량 및 관련 비용을 모니터링하고 관리하는 것은 본인의 책임입니다. OpenAI API 사용량을 정기적으로 확인하고, 예상치 못한 비용을 방지하기 위해 필요한 한도를 설정하거나 알림을 설정하는 것이 좋습니다.
|
||||||
|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://star-history.com/#assafelovic/gpt-researcher">
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date&theme=dark" />
|
||||||
|
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
</picture>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
158
systems/research/gpt-researcher/README-zh_CN.md
Normal file
@ -0,0 +1,158 @@
|
|||||||
|
<div align="center">
|
||||||
|
<!--<h1 style="display: flex; align-items: center; gap: 10px;">
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/a45bac7c-092c-42e5-8eb6-69acbf20dde5" alt="Logo" width="25">
|
||||||
|
GPT Researcher
|
||||||
|
</h1>-->
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/20af8286-b386-44a5-9a83-3be1365139c3" alt="Logo" width="80">
|
||||||
|
|
||||||
|
|
||||||
|
####
|
||||||
|
|
||||||
|
[](https://gptr.dev)
|
||||||
|
[](https://docs.gptr.dev)
|
||||||
|
[](https://discord.gg/QgZXvJAccX)
|
||||||
|
|
||||||
|
[](https://badge.fury.io/py/gpt-researcher)
|
||||||
|

|
||||||
|
[](https://colab.research.google.com/github/assafelovic/gpt-researcher/blob/master/docs/docs/examples/pip-run.ipynb)
|
||||||
|
[](https://hub.docker.com/r/gptresearcher/gpt-researcher)
|
||||||
|
[](https://twitter.com/assaf_elovic)
|
||||||
|
|
||||||
|
[English](README.md) |
|
||||||
|
[中文](README-zh_CN.md) |
|
||||||
|
[日本語](README-ja_JP.md) |
|
||||||
|
[한국어](README-ko_KR.md)
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# 🔎 GPT Researcher
|
||||||
|
|
||||||
|
**GPT Researcher 是一个智能体代理,专为各种任务的综合在线研究而设计。**
|
||||||
|
|
||||||
|
代理可以生成详细、正式且客观的研究报告,并提供自定义选项,专注于相关资源、结构框架和经验报告。受最近发表的[Plan-and-Solve](https://arxiv.org/abs/2305.04091) 和[RAG](https://arxiv.org/abs/2005.11401) 论文的启发,GPT Researcher 解决了速度、确定性和可靠性等问题,通过并行化的代理运行,而不是同步操作,提供了更稳定的性能和更高的速度。
|
||||||
|
|
||||||
|
**我们的使命是利用人工智能的力量,为个人和组织提供准确、客观和事实的信息。**
|
||||||
|
|
||||||
|
## 为什么选择GPT Researcher?
|
||||||
|
|
||||||
|
- 因为人工研究任务形成客观结论可能需要时间和经历,有时甚至需要数周才能找到正确的资源和信息。
|
||||||
|
- 目前的LLM是根据历史和过时的信息进行训练的,存在严重的幻觉风险,因此几乎无法胜任研究任务。
|
||||||
|
- 网络搜索的解决方案(例如 ChatGPT + Web 插件)仅考虑有限的资源和内容,在某些情况下会导致肤浅的结论或不客观的答案。
|
||||||
|
- 只使用部分资源可能会在确定研究问题或任务的正确结论时产生偏差。
|
||||||
|
|
||||||
|
## 架构
|
||||||
|
主要思想是运行“**计划者**”和“**执行**”代理,而**计划者**生成问题进行研究,“**执行**”代理根据每个生成的研究问题寻找最相关的信息。最后,“**计划者**”过滤和聚合所有相关信息并创建研究报告。<br /> <br />
|
||||||
|
代理同时利用 gpt-40-mini 和 gpt-4o(128K 上下文)来完成一项研究任务。我们仅在必要时使用这两种方法对成本进行优化。**研究任务平均耗时约 3 分钟,成本约为 ~0.1 美元**。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img align="center" height="500" src="https://cowriter-images.s3.amazonaws.com/architecture.png">
|
||||||
|
</div>
|
||||||
|
|
||||||
|
|
||||||
|
详细说明:
|
||||||
|
* 根据研究搜索或任务创建特定领域的代理。
|
||||||
|
* 生成一组研究问题,这些问题共同形成答案对任何给定任务的客观意见。
|
||||||
|
* 针对每个研究问题,触发一个爬虫代理,从在线资源中搜索与给定任务相关的信息。
|
||||||
|
* 对于每一个抓取的资源,根据相关信息进行汇总,并跟踪其来源。
|
||||||
|
* 最后,对所有汇总的资料来源进行过滤和汇总,并生成最终研究报告。
|
||||||
|
|
||||||
|
## 演示
|
||||||
|
https://github.com/assafelovic/gpt-researcher/assets/13554167/a00c89a6-a295-4dd0-b58d-098a31c40fda
|
||||||
|
|
||||||
|
## 教程
|
||||||
|
- [运行原理](https://docs.gptr.dev/blog/building-gpt-researcher)
|
||||||
|
- [如何安装](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
|
||||||
|
- [现场演示](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
|
||||||
|
|
||||||
|
## 特性
|
||||||
|
- 📝 生成研究问题、大纲、资源和课题报告
|
||||||
|
- 🌐 每项研究汇总超过20个网络资源,形成客观和真实的结论
|
||||||
|
- 🖥️ 包括易于使用的web界面 (HTML/CSS/JS)
|
||||||
|
- 🔍 支持JavaScript网络资源抓取功能
|
||||||
|
- 📂 追踪访问过和使用过的网络资源和来源
|
||||||
|
- 📄 将研究报告导出为PDF或其他格式...
|
||||||
|
|
||||||
|
## 📖 文档
|
||||||
|
|
||||||
|
请参阅[此处](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started),了解完整文档:
|
||||||
|
|
||||||
|
- 入门(安装、设置环境、简单示例)
|
||||||
|
- 操作示例(演示、集成、docker 支持)
|
||||||
|
- 参考资料(API完整文档)
|
||||||
|
- Tavily 应用程序接口集成(核心概念的高级解释)
|
||||||
|
|
||||||
|
## 快速开始
|
||||||
|
> **步骤 0** - 安装 Python 3.11 或更高版本。[参见此处](https://www.tutorialsteacher.com/python/install-python) 获取详细指南。
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **步骤 1** - 下载项目
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ git clone https://github.com/assafelovic/gpt-researcher.git
|
||||||
|
$ cd gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **步骤2** -安装依赖项
|
||||||
|
```bash
|
||||||
|
$ pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **第 3 步** - 使用 OpenAI 密钥和 Tavily API 密钥创建 .env 文件,或直接导出该文件
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ export OPENAI_API_KEY={Your OpenAI API Key here}
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
$ export TAVILY_API_KEY={Your Tavily API Key here}
|
||||||
|
```
|
||||||
|
|
||||||
|
- **LLM,我们推荐使用 [OpenAI GPT](https://platform.openai.com/docs/guides/gpt)**,但您也可以使用 [Langchain Adapter](https://python.langchain.com/docs/guides/adapters/openai) 支持的任何其他 LLM 模型(包括开源),只需在 config/config.py 中更改 llm 模型和提供者即可。请按照 [这份指南](https://python.langchain.com/docs/integrations/llms/) 学习如何将 LLM 与 Langchain 集成。
|
||||||
|
- **对于搜索引擎,我们推荐使用 [Tavily Search API](https://app.tavily.com)(已针对 LLM 进行优化)**,但您也可以选择其他搜索引擎,只需将 config/config.py 中的搜索提供程序更改为 "duckduckgo"、"googleAPI"、"searchapi"、"googleSerp "或 "searx "即可。然后在 config.py 文件中添加相应的 env API 密钥。
|
||||||
|
- **我们强烈建议使用 [OpenAI GPT](https://platform.openai.com/docs/guides/gpt) 模型和 [Tavily Search API](https://app.tavily.com) 以获得最佳性能。**
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **第 4 步** - 使用 FastAPI 运行代理
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ uvicorn main:app --reload
|
||||||
|
```
|
||||||
|
<br />
|
||||||
|
|
||||||
|
> **第 5 步** - 在任何浏览器上访问 http://localhost:8000,享受研究乐趣!
|
||||||
|
|
||||||
|
要了解如何开始使用 Docker 或了解有关功能和服务的更多信息,请访问 [documentation](https://docs.gptr.dev) 页面。
|
||||||
|
|
||||||
|
## 🚀 贡献
|
||||||
|
我们非常欢迎您的贡献!如果您感兴趣,请查看 [contributing](CONTRIBUTING.md)。
|
||||||
|
|
||||||
|
如果您有兴趣加入我们的任务,请查看我们的 [路线图](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap) 页面,并通过我们的 [Discord 社区](https://discord.gg/QgZXvJAccX) 联系我们。
|
||||||
|
|
||||||
|
## ✉️ 支持 / 联系我们
|
||||||
|
- [社区讨论区](https://discord.gg/spBgZmm3Xe)
|
||||||
|
- 我们的邮箱: support@tavily.com
|
||||||
|
|
||||||
|
## 🛡 免责声明
|
||||||
|
|
||||||
|
本项目 "GPT Researcher "是一个实验性应用程序,按 "现状 "提供,不做任何明示或暗示的保证。我们根据 MIT 许可分享用于学术目的的代码。本文不提供任何学术建议,也不建议在学术或研究论文中使用。
|
||||||
|
|
||||||
|
我们对客观研究主张的看法:
|
||||||
|
1. 我们抓取系统的全部目的是减少不正确的事实。如何解决?我们抓取的网站越多,错误数据的可能性就越小。我们每项研究都会收集20条信息,它们全部错误的可能性极低。
|
||||||
|
2. 我们的目标不是消除偏见,而是尽可能减少偏见。**作为一个社区,我们在这里探索最有效的人机互动**。
|
||||||
|
3. 在研究过程中,人们也容易产生偏见,因为大多数人对自己研究的课题都有自己的看法。这个工具可以搜罗到许多观点,并均匀地解释各种不同的观点,而有偏见的人是绝对读不到这些观点的。
|
||||||
|
|
||||||
|
**请注意,使用 GPT-4 语言模型可能会因使用令牌而产生高昂费用**。使用本项目即表示您承认有责任监控和管理自己的令牌使用情况及相关费用。强烈建议您定期检查 OpenAI API 的使用情况,并设置任何必要的限制或警报,以防止发生意外费用。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://star-history.com/#assafelovic/gpt-researcher">
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date&theme=dark" />
|
||||||
|
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
</picture>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
241
systems/research/gpt-researcher/README.md
Normal file
@ -0,0 +1,241 @@
|
|||||||
|
<div align="center" id="top">
|
||||||
|
|
||||||
|
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/20af8286-b386-44a5-9a83-3be1365139c3" alt="Logo" width="80">
|
||||||
|
|
||||||
|
####
|
||||||
|
|
||||||
|
[](https://gptr.dev)
|
||||||
|
[](https://docs.gptr.dev)
|
||||||
|
[](https://discord.gg/QgZXvJAccX)
|
||||||
|
|
||||||
|
[](https://badge.fury.io/py/gpt-researcher)
|
||||||
|

|
||||||
|
[](https://colab.research.google.com/github/assafelovic/gpt-researcher/blob/master/docs/docs/examples/pip-run.ipynb)
|
||||||
|
[](https://hub.docker.com/r/gptresearcher/gpt-researcher)
|
||||||
|
[](https://twitter.com/assaf_elovic)
|
||||||
|
|
||||||
|
[English](README.md) | [中文](README-zh_CN.md) | [日本語](README-ja_JP.md) | [한국어](README-ko_KR.md)
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# 🔎 GPT Researcher
|
||||||
|
|
||||||
|
**GPT Researcher is an open deep research agent designed for both web and local research on any given task.**
|
||||||
|
|
||||||
|
The agent produces detailed, factual, and unbiased research reports with citations. GPT Researcher provides a full suite of customization options to create tailor made and domain specific research agents. Inspired by the recent [Plan-and-Solve](https://arxiv.org/abs/2305.04091) and [RAG](https://arxiv.org/abs/2005.11401) papers, GPT Researcher addresses misinformation, speed, determinism, and reliability by offering stable performance and increased speed through parallelized agent work.
|
||||||
|
|
||||||
|
**Our mission is to empower individuals and organizations with accurate, unbiased, and factual information through AI.**
|
||||||
|
|
||||||
|
## Why GPT Researcher?
|
||||||
|
|
||||||
|
- Objective conclusions for manual research can take weeks, requiring vast resources and time.
|
||||||
|
- LLMs trained on outdated information can hallucinate, becoming irrelevant for current research tasks.
|
||||||
|
- Current LLMs have token limitations, insufficient for generating long research reports.
|
||||||
|
- Limited web sources in existing services lead to misinformation and shallow results.
|
||||||
|
- Selective web sources can introduce bias into research tasks.
|
||||||
|
|
||||||
|
## Demo
|
||||||
|
https://github.com/user-attachments/assets/2cc38f6a-9f66-4644-9e69-a46c40e296d4
|
||||||
|
|
||||||
|
## Architecture
|
||||||
|
|
||||||
|
The core idea is to utilize 'planner' and 'execution' agents. The planner generates research questions, while the execution agents gather relevant information. The publisher then aggregates all findings into a comprehensive report.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img align="center" height="600" src="https://github.com/assafelovic/gpt-researcher/assets/13554167/4ac896fd-63ab-4b77-9688-ff62aafcc527">
|
||||||
|
</div>
|
||||||
|
|
||||||
|
Steps:
|
||||||
|
* Create a task-specific agent based on a research query.
|
||||||
|
* Generate questions that collectively form an objective opinion on the task.
|
||||||
|
* Use a crawler agent for gathering information for each question.
|
||||||
|
* Summarize and source-track each resource.
|
||||||
|
* Filter and aggregate summaries into a final research report.
|
||||||
|
|
||||||
|
## Tutorials
|
||||||
|
- [How it Works](https://docs.gptr.dev/blog/building-gpt-researcher)
|
||||||
|
- [How to Install](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
|
||||||
|
- [Live Demo](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
|
||||||
|
|
||||||
|
## Features
|
||||||
|
|
||||||
|
- 📝 Generate detailed research reports using web and local documents.
|
||||||
|
- 🖼️ Smart image scraping and filtering for reports.
|
||||||
|
- 📜 Generate detailed reports exceeding 2,000 words.
|
||||||
|
- 🌐 Aggregate over 20 sources for objective conclusions.
|
||||||
|
- 🖥️ Frontend available in lightweight (HTML/CSS/JS) and production-ready (NextJS + Tailwind) versions.
|
||||||
|
- 🔍 JavaScript-enabled web scraping.
|
||||||
|
- 📂 Maintains memory and context throughout research.
|
||||||
|
- 📄 Export reports to PDF, Word, and other formats.
|
||||||
|
|
||||||
|
## ✨ Deep Research
|
||||||
|
|
||||||
|
GPT Researcher now includes Deep Research - an advanced recursive research workflow that explores topics with agentic depth and breadth. This feature employs a tree-like exploration pattern, diving deeper into subtopics while maintaining a comprehensive view of the research subject.
|
||||||
|
|
||||||
|
- 🌳 Tree-like exploration with configurable depth and breadth
|
||||||
|
- ⚡️ Concurrent processing for faster results
|
||||||
|
- 🤝 Smart context management across research branches
|
||||||
|
- ⏱️ Takes ~5 minutes per deep research
|
||||||
|
- 💰 Costs ~$0.4 per research (using `o3-mini` on "high" reasoning effort)
|
||||||
|
|
||||||
|
[Learn more about Deep Research](https://docs.gptr.dev/docs/gpt-researcher/gptr/deep_research) in our documentation.
|
||||||
|
|
||||||
|
## 📖 Documentation
|
||||||
|
|
||||||
|
See the [Documentation](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started) for:
|
||||||
|
- Installation and setup guides
|
||||||
|
- Configuration and customization options
|
||||||
|
- How-To examples
|
||||||
|
- Full API references
|
||||||
|
|
||||||
|
## ⚙️ Getting Started
|
||||||
|
|
||||||
|
### Installation
|
||||||
|
|
||||||
|
1. Install Python 3.11 or later. [Guide](https://www.tutorialsteacher.com/python/install-python).
|
||||||
|
2. Clone the project and navigate to the directory:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/assafelovic/gpt-researcher.git
|
||||||
|
cd gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Set up API keys by exporting them or storing them in a `.env` file.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY={Your OpenAI API Key here}
|
||||||
|
export TAVILY_API_KEY={Your Tavily API Key here}
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Install dependencies and start the server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r requirements.txt
|
||||||
|
python -m uvicorn main:app --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
Visit [http://localhost:8000](http://localhost:8000) to start.
|
||||||
|
|
||||||
|
For other setups (e.g., Poetry or virtual environments), check the [Getting Started page](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started).
|
||||||
|
|
||||||
|
## Run as PIP package
|
||||||
|
```bash
|
||||||
|
pip install gpt-researcher
|
||||||
|
|
||||||
|
```
|
||||||
|
### Example Usage:
|
||||||
|
```python
|
||||||
|
...
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
query = "why is Nvidia stock going up?"
|
||||||
|
researcher = GPTResearcher(query=query, report_type="research_report")
|
||||||
|
# Conduct research on the given query
|
||||||
|
research_result = await researcher.conduct_research()
|
||||||
|
# Write the report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
**For more examples and configurations, please refer to the [PIP documentation](https://docs.gptr.dev/docs/gpt-researcher/gptr/pip-package) page.**
|
||||||
|
|
||||||
|
|
||||||
|
## Run with Docker
|
||||||
|
|
||||||
|
> **Step 1** - [Install Docker](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started-with-docker)
|
||||||
|
|
||||||
|
> **Step 2** - Clone the '.env.example' file, add your API Keys to the cloned file and save the file as '.env'
|
||||||
|
|
||||||
|
> **Step 3** - Within the docker-compose file comment out services that you don't want to run with Docker.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker-compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
If that doesn't work, try running it without the dash:
|
||||||
|
```bash
|
||||||
|
docker compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Step 4** - By default, if you haven't uncommented anything in your docker-compose file, this flow will start 2 processes:
|
||||||
|
- the Python server running on localhost:8000<br>
|
||||||
|
- the React app running on localhost:3000<br>
|
||||||
|
|
||||||
|
Visit localhost:3000 on any browser and enjoy researching!
|
||||||
|
|
||||||
|
|
||||||
|
## 📄 Research on Local Documents
|
||||||
|
|
||||||
|
You can instruct the GPT Researcher to run research tasks based on your local documents. Currently supported file formats are: PDF, plain text, CSV, Excel, Markdown, PowerPoint, and Word documents.
|
||||||
|
|
||||||
|
Step 1: Add the env variable `DOC_PATH` pointing to the folder where your documents are located.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export DOC_PATH="./my-docs"
|
||||||
|
```
|
||||||
|
|
||||||
|
Step 2:
|
||||||
|
- If you're running the frontend app on localhost:8000, simply select "My Documents" from the "Report Source" Dropdown Options.
|
||||||
|
- If you're running GPT Researcher with the [PIP package](https://docs.tavily.com/guides/gpt-researcher/gpt-researcher#pip-package), pass the `report_source` argument as "local" when you instantiate the `GPTResearcher` class [code sample here](https://docs.gptr.dev/docs/gpt-researcher/context/tailored-research).
|
||||||
|
|
||||||
|
|
||||||
|
## 👪 Multi-Agent Assistant
|
||||||
|
As AI evolves from prompt engineering and RAG to multi-agent systems, we're excited to introduce our new multi-agent assistant built with [LangGraph](https://python.langchain.com/v0.1/docs/langgraph/).
|
||||||
|
|
||||||
|
By using LangGraph, the research process can be significantly improved in depth and quality by leveraging multiple agents with specialized skills. Inspired by the recent [STORM](https://arxiv.org/abs/2402.14207) paper, this project showcases how a team of AI agents can work together to conduct research on a given topic, from planning to publication.
|
||||||
|
|
||||||
|
An average run generates a 5-6 page research report in multiple formats such as PDF, Docx and Markdown.
|
||||||
|
|
||||||
|
Check it out [here](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents) or head over to our [documentation](https://docs.gptr.dev/docs/gpt-researcher/multi_agents/langgraph) for more information.
|
||||||
|
|
||||||
|
## 🖥️ Frontend Applications
|
||||||
|
|
||||||
|
GPT-Researcher now features an enhanced frontend to improve the user experience and streamline the research process. The frontend offers:
|
||||||
|
|
||||||
|
- An intuitive interface for inputting research queries
|
||||||
|
- Real-time progress tracking of research tasks
|
||||||
|
- Interactive display of research findings
|
||||||
|
- Customizable settings for tailored research experiences
|
||||||
|
|
||||||
|
Two deployment options are available:
|
||||||
|
1. A lightweight static frontend served by FastAPI
|
||||||
|
2. A feature-rich NextJS application for advanced functionality
|
||||||
|
|
||||||
|
For detailed setup instructions and more information about the frontend features, please visit our [documentation page](https://docs.gptr.dev/docs/gpt-researcher/frontend/introduction).
|
||||||
|
|
||||||
|
## 🚀 Contributing
|
||||||
|
We highly welcome contributions! Please check out [contributing](https://github.com/assafelovic/gpt-researcher/blob/master/CONTRIBUTING.md) if you're interested.
|
||||||
|
|
||||||
|
Please check out our [roadmap](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap) page and reach out to us via our [Discord community](https://discord.gg/QgZXvJAccX) if you're interested in joining our mission.
|
||||||
|
<a href="https://github.com/assafelovic/gpt-researcher/graphs/contributors">
|
||||||
|
<img src="https://contrib.rocks/image?repo=assafelovic/gpt-researcher" />
|
||||||
|
</a>
|
||||||
|
## ✉️ Support / Contact us
|
||||||
|
- [Community Discord](https://discord.gg/spBgZmm3Xe)
|
||||||
|
- Author Email: assaf.elovic@gmail.com
|
||||||
|
|
||||||
|
## 🛡 Disclaimer
|
||||||
|
|
||||||
|
This project, GPT Researcher, is an experimental application and is provided "as-is" without any warranty, express or implied. We are sharing codes for academic purposes under the Apache 2 license. Nothing herein is academic advice, and NOT a recommendation to use in academic or research papers.
|
||||||
|
|
||||||
|
Our view on unbiased research claims:
|
||||||
|
1. The main goal of GPT Researcher is to reduce incorrect and biased facts. How? We assume that the more sites we scrape the less chances of incorrect data. By scraping multiple sites per research, and choosing the most frequent information, the chances that they are all wrong is extremely low.
|
||||||
|
2. We do not aim to eliminate biases; we aim to reduce it as much as possible. **We are here as a community to figure out the most effective human/llm interactions.**
|
||||||
|
3. In research, people also tend towards biases as most have already opinions on the topics they research about. This tool scrapes many opinions and will evenly explain diverse views that a biased person would never have read.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://star-history.com/#assafelovic/gpt-researcher">
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date&theme=dark" />
|
||||||
|
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=assafelovic/gpt-researcher&type=Date" />
|
||||||
|
</picture>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
|
||||||
|
<p align="right">
|
||||||
|
<a href="#top">⬆️ Back to Top</a>
|
||||||
|
</p>
|
||||||
1
systems/research/gpt-researcher/backend/__init__.py
Normal file
@ -0,0 +1 @@
|
|||||||
|
from multi_agents import agents
|
||||||
1
systems/research/gpt-researcher/backend/chat/__init__.py
Normal file
@ -0,0 +1 @@
|
|||||||
|
from .chat import ChatAgentWithMemory
|
||||||
106
systems/research/gpt-researcher/backend/chat/chat.py
Normal file
@ -0,0 +1,106 @@
|
|||||||
|
from fastapi import WebSocket
|
||||||
|
import uuid
|
||||||
|
|
||||||
|
from gpt_researcher.utils.llm import get_llm
|
||||||
|
from gpt_researcher.memory import Memory
|
||||||
|
from gpt_researcher.config.config import Config
|
||||||
|
|
||||||
|
from langgraph.prebuilt import create_react_agent
|
||||||
|
from langgraph.checkpoint.memory import MemorySaver
|
||||||
|
|
||||||
|
from langchain_community.vectorstores import InMemoryVectorStore
|
||||||
|
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||||
|
from langchain.tools import Tool, tool
|
||||||
|
|
||||||
|
class ChatAgentWithMemory:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
report: str,
|
||||||
|
config_path,
|
||||||
|
headers,
|
||||||
|
vector_store = None
|
||||||
|
):
|
||||||
|
self.report = report
|
||||||
|
self.headers = headers
|
||||||
|
self.config = Config(config_path)
|
||||||
|
self.vector_store = vector_store
|
||||||
|
self.graph = self.create_agent()
|
||||||
|
|
||||||
|
def create_agent(self):
|
||||||
|
"""Create React Agent Graph"""
|
||||||
|
cfg = Config()
|
||||||
|
|
||||||
|
# Retrieve LLM using get_llm with settings from config
|
||||||
|
provider = get_llm(
|
||||||
|
llm_provider=cfg.smart_llm_provider,
|
||||||
|
model=cfg.smart_llm_model,
|
||||||
|
temperature=0.35,
|
||||||
|
max_tokens=cfg.smart_token_limit,
|
||||||
|
**self.config.llm_kwargs
|
||||||
|
).llm
|
||||||
|
|
||||||
|
# If vector_store is not initialized, process documents and add to vector_store
|
||||||
|
if not self.vector_store:
|
||||||
|
documents = self._process_document(self.report)
|
||||||
|
self.chat_config = {"configurable": {"thread_id": str(uuid.uuid4())}}
|
||||||
|
self.embedding = Memory(
|
||||||
|
cfg.embedding_provider,
|
||||||
|
cfg.embedding_model,
|
||||||
|
**cfg.embedding_kwargs
|
||||||
|
).get_embeddings()
|
||||||
|
self.vector_store = InMemoryVectorStore(self.embedding)
|
||||||
|
self.vector_store.add_texts(documents)
|
||||||
|
|
||||||
|
# Create the React Agent Graph with the configured provider
|
||||||
|
graph = create_react_agent(
|
||||||
|
provider,
|
||||||
|
tools=[self.vector_store_tool(self.vector_store)],
|
||||||
|
checkpointer=MemorySaver()
|
||||||
|
)
|
||||||
|
|
||||||
|
return graph
|
||||||
|
|
||||||
|
def vector_store_tool(self, vector_store) -> Tool:
|
||||||
|
"""Create Vector Store Tool"""
|
||||||
|
@tool
|
||||||
|
def retrieve_info(query):
|
||||||
|
"""
|
||||||
|
Consult the report for relevant contexts whenever you don't know something
|
||||||
|
"""
|
||||||
|
retriever = vector_store.as_retriever(k = 4)
|
||||||
|
return retriever.invoke(query)
|
||||||
|
return retrieve_info
|
||||||
|
|
||||||
|
def _process_document(self, report):
|
||||||
|
"""Split Report into Chunks"""
|
||||||
|
text_splitter = RecursiveCharacterTextSplitter(
|
||||||
|
chunk_size=1024,
|
||||||
|
chunk_overlap=20,
|
||||||
|
length_function=len,
|
||||||
|
is_separator_regex=False,
|
||||||
|
)
|
||||||
|
documents = text_splitter.split_text(report)
|
||||||
|
return documents
|
||||||
|
|
||||||
|
async def chat(self, message, websocket):
|
||||||
|
"""Chat with React Agent"""
|
||||||
|
message = f"""
|
||||||
|
You are GPT Researcher, a autonomous research agent created by an open source community at https://github.com/assafelovic/gpt-researcher, homepage: https://gptr.dev.
|
||||||
|
To learn more about GPT Researcher you can suggest to check out: https://docs.gptr.dev.
|
||||||
|
|
||||||
|
This is a chat message between the user and you: GPT Researcher.
|
||||||
|
The chat is about a research reports that you created. Answer based on the given context and report.
|
||||||
|
You must include citations to your answer based on the report.
|
||||||
|
|
||||||
|
Report: {self.report}
|
||||||
|
User Message: {message}
|
||||||
|
"""
|
||||||
|
inputs = {"messages": [("user", message)]}
|
||||||
|
response = await self.graph.ainvoke(inputs, config=self.chat_config)
|
||||||
|
ai_message = response["messages"][-1].content
|
||||||
|
if websocket is not None:
|
||||||
|
await websocket.send_json({"type": "chat", "content": ai_message})
|
||||||
|
|
||||||
|
def get_context(self):
|
||||||
|
"""return the current context of the chat"""
|
||||||
|
return self.report
|
||||||
10
systems/research/gpt-researcher/backend/memory/draft.py
Normal file
@ -0,0 +1,10 @@
|
|||||||
|
from typing import TypedDict, List, Annotated
|
||||||
|
import operator
|
||||||
|
|
||||||
|
|
||||||
|
class DraftState(TypedDict):
|
||||||
|
task: dict
|
||||||
|
topic: str
|
||||||
|
draft: dict
|
||||||
|
review: str
|
||||||
|
revision_notes: str
|
||||||
20
systems/research/gpt-researcher/backend/memory/research.py
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
from typing import TypedDict, List, Annotated
|
||||||
|
import operator
|
||||||
|
|
||||||
|
|
||||||
|
class ResearchState(TypedDict):
|
||||||
|
task: dict
|
||||||
|
initial_research: str
|
||||||
|
sections: List[str]
|
||||||
|
research_data: List[dict]
|
||||||
|
# Report layout
|
||||||
|
title: str
|
||||||
|
headers: dict
|
||||||
|
date: str
|
||||||
|
table_of_contents: str
|
||||||
|
introduction: str
|
||||||
|
conclusion: str
|
||||||
|
sources: List[str]
|
||||||
|
report: str
|
||||||
|
|
||||||
|
|
||||||
@ -0,0 +1,7 @@
|
|||||||
|
from .basic_report.basic_report import BasicReport
|
||||||
|
from .detailed_report.detailed_report import DetailedReport
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"BasicReport",
|
||||||
|
"DetailedReport"
|
||||||
|
]
|
||||||
@ -0,0 +1,52 @@
|
|||||||
|
from fastapi import WebSocket
|
||||||
|
from typing import Any
|
||||||
|
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
|
||||||
|
class BasicReport:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
query: str,
|
||||||
|
query_domains: list,
|
||||||
|
report_type: str,
|
||||||
|
report_source: str,
|
||||||
|
source_urls,
|
||||||
|
document_urls,
|
||||||
|
tone: Any,
|
||||||
|
config_path: str,
|
||||||
|
websocket: WebSocket,
|
||||||
|
headers=None,
|
||||||
|
language:str = "english"
|
||||||
|
):
|
||||||
|
self.query = query
|
||||||
|
self.query_domains = query_domains
|
||||||
|
self.report_type = report_type
|
||||||
|
self.report_source = report_source
|
||||||
|
self.source_urls = source_urls
|
||||||
|
self.document_urls = document_urls
|
||||||
|
self.tone = tone
|
||||||
|
self.config_path = config_path
|
||||||
|
self.websocket = websocket
|
||||||
|
self.headers = headers or {}
|
||||||
|
self.language = language
|
||||||
|
|
||||||
|
# Initialize researcher
|
||||||
|
self.gpt_researcher = GPTResearcher(
|
||||||
|
query=self.query,
|
||||||
|
query_domains=self.query_domains,
|
||||||
|
report_type=self.report_type,
|
||||||
|
report_source=self.report_source,
|
||||||
|
source_urls=self.source_urls,
|
||||||
|
document_urls=self.document_urls,
|
||||||
|
tone=self.tone,
|
||||||
|
config_path=self.config_path,
|
||||||
|
websocket=self.websocket,
|
||||||
|
headers=self.headers,
|
||||||
|
language=self.language
|
||||||
|
)
|
||||||
|
|
||||||
|
async def run(self):
|
||||||
|
await self.gpt_researcher.conduct_research()
|
||||||
|
report = await self.gpt_researcher.write_report()
|
||||||
|
return report
|
||||||
@ -0,0 +1,129 @@
|
|||||||
|
# Deep Research ✨ NEW ✨
|
||||||
|
|
||||||
|
With the latest "Deep Research" trend in the AI community, we're excited to implement our own Open source deep research capability! Introducing GPT Researcher's Deep Research - an advanced recursive research system that explores topics with unprecedented depth and breadth.
|
||||||
|
|
||||||
|
## How It Works
|
||||||
|
|
||||||
|
Deep Research employs a fascinating tree-like exploration pattern:
|
||||||
|
|
||||||
|
1. **Breadth**: At each level, it generates multiple search queries to explore different aspects of your topic
|
||||||
|
2. **Depth**: For each branch, it recursively dives deeper, following leads and uncovering connections
|
||||||
|
3. **Concurrent Processing**: Utilizes async/await patterns to run multiple research paths simultaneously
|
||||||
|
4. **Smart Context Management**: Automatically aggregates and synthesizes findings across all branches
|
||||||
|
5. **Progress Tracking**: Real-time updates on research progress across both breadth and depth dimensions
|
||||||
|
|
||||||
|
Think of it as deploying a team of AI researchers, each following their own research path while collaborating to build a comprehensive understanding of your topic.
|
||||||
|
|
||||||
|
## Process Flow
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
## Quick Start
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from gpt_researcher.utils.enum import ReportType, Tone
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def main():
|
||||||
|
# Initialize researcher with deep research type
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query="What are the latest developments in quantum computing?",
|
||||||
|
report_type="deep", # This triggers deep research modd
|
||||||
|
)
|
||||||
|
|
||||||
|
# Run research
|
||||||
|
research_data = await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Generate report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
print(report)
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
asyncio.run(main())
|
||||||
|
```
|
||||||
|
|
||||||
|
## Configuration
|
||||||
|
|
||||||
|
Deep Research behavior can be customized through several parameters:
|
||||||
|
|
||||||
|
- `deep_research_breadth`: Number of parallel research paths at each level (default: 4)
|
||||||
|
- `deep_research_depth`: How many levels deep to explore (default: 2)
|
||||||
|
- `deep_research_concurrency`: Maximum number of concurrent research operations (default: 2)
|
||||||
|
|
||||||
|
You can configure these in your config file, pass as environment variables or pass them directly:
|
||||||
|
|
||||||
|
```python
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query="your query",
|
||||||
|
report_type="deep",
|
||||||
|
config_path="path/to/config.yaml" # Configure deep research parameters here
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Progress Tracking
|
||||||
|
|
||||||
|
The `on_progress` callback provides real-time insights into the research process:
|
||||||
|
|
||||||
|
```python
|
||||||
|
class ResearchProgress:
|
||||||
|
current_depth: int # Current depth level
|
||||||
|
total_depth: int # Maximum depth to explore
|
||||||
|
current_breadth: int # Current number of parallel paths
|
||||||
|
total_breadth: int # Maximum breadth at each level
|
||||||
|
current_query: str # Currently processing query
|
||||||
|
completed_queries: int # Number of completed queries
|
||||||
|
total_queries: int # Total queries to process
|
||||||
|
```
|
||||||
|
|
||||||
|
## Advanced Usage
|
||||||
|
|
||||||
|
### Custom Research Flow
|
||||||
|
|
||||||
|
```python
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query="your query",
|
||||||
|
report_type="deep",
|
||||||
|
tone=Tone.Objective,
|
||||||
|
headers={"User-Agent": "your-agent"}, # Custom headers for web requests
|
||||||
|
verbose=True # Enable detailed logging
|
||||||
|
)
|
||||||
|
|
||||||
|
# Get raw research context
|
||||||
|
context = await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Access research sources
|
||||||
|
sources = researcher.get_research_sources()
|
||||||
|
|
||||||
|
# Get visited URLs
|
||||||
|
urls = researcher.get_source_urls()
|
||||||
|
|
||||||
|
# Generate formatted report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Error Handling
|
||||||
|
|
||||||
|
The deep research system is designed to be resilient:
|
||||||
|
|
||||||
|
- Failed queries are automatically skipped
|
||||||
|
- Research continues even if some branches fail
|
||||||
|
- Progress tracking helps identify any issues
|
||||||
|
|
||||||
|
## Best Practices
|
||||||
|
|
||||||
|
1. **Start Broad**: Begin with a general query and let the system explore specifics
|
||||||
|
2. **Monitor Progress**: Use the progress callback to understand the research flow
|
||||||
|
3. **Adjust Parameters**: Tune breadth and depth based on your needs:
|
||||||
|
- More breadth = wider coverage
|
||||||
|
- More depth = deeper insights
|
||||||
|
4. **Resource Management**: Consider concurrency limits based on your system capabilities
|
||||||
|
|
||||||
|
## Limitations
|
||||||
|
|
||||||
|
- Usage of reasoning LLM models such as `o3-mini`. This means that permissions for reasoning are required and the overall run will be significantly slower.
|
||||||
|
- Deep research may take longer than standard research
|
||||||
|
- Higher API usage and costs due to multiple concurrent queries
|
||||||
|
- May require more system resources for parallel processing
|
||||||
|
|
||||||
|
Happy researching! 🎉
|
||||||
@ -0,0 +1,324 @@
|
|||||||
|
from typing import List, Dict, Any, Optional, Set
|
||||||
|
from fastapi import WebSocket
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from gpt_researcher.llm_provider.generic.base import ReasoningEfforts
|
||||||
|
from gpt_researcher.utils.llm import create_chat_completion
|
||||||
|
from gpt_researcher.utils.enum import ReportType, ReportSource, Tone
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# Constants for models
|
||||||
|
GPT4_MODEL = "gpt-4o" # For standard tasks
|
||||||
|
O3_MINI_MODEL = "o3-mini" # For reasoning tasks
|
||||||
|
LLM_PROVIDER = "openai"
|
||||||
|
|
||||||
|
class ResearchProgress:
|
||||||
|
def __init__(self, total_depth: int, total_breadth: int):
|
||||||
|
self.current_depth = total_depth
|
||||||
|
self.total_depth = total_depth
|
||||||
|
self.current_breadth = total_breadth
|
||||||
|
self.total_breadth = total_breadth
|
||||||
|
self.current_query: Optional[str] = None
|
||||||
|
self.total_queries = 0
|
||||||
|
self.completed_queries = 0
|
||||||
|
|
||||||
|
class DeepResearch:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
query: str,
|
||||||
|
breadth: int = 4,
|
||||||
|
depth: int = 2,
|
||||||
|
websocket: Optional[WebSocket] = None,
|
||||||
|
tone: Tone = Tone.Objective,
|
||||||
|
config_path: Optional[str] = None,
|
||||||
|
headers: Optional[Dict] = None,
|
||||||
|
concurrency_limit: int = 2 # Match TypeScript version
|
||||||
|
):
|
||||||
|
self.query = query
|
||||||
|
self.breadth = breadth
|
||||||
|
self.depth = depth
|
||||||
|
self.websocket = websocket
|
||||||
|
self.tone = tone
|
||||||
|
self.config_path = config_path
|
||||||
|
self.headers = headers or {}
|
||||||
|
self.visited_urls: Set[str] = set()
|
||||||
|
self.learnings: List[str] = []
|
||||||
|
self.concurrency_limit = concurrency_limit
|
||||||
|
|
||||||
|
async def generate_feedback(self, query: str, num_questions: int = 3) -> List[str]:
|
||||||
|
"""Generate follow-up questions to clarify research direction"""
|
||||||
|
messages = [
|
||||||
|
{"role": "system", "content": "You are an expert researcher helping to clarify research directions."},
|
||||||
|
{"role": "user", "content": f"Given the following query from the user, ask some follow up questions to clarify the research direction. Return a maximum of {num_questions} questions, but feel free to return less if the original query is clear. Format each question on a new line starting with 'Question: ': {query}"}
|
||||||
|
]
|
||||||
|
|
||||||
|
response = await create_chat_completion(
|
||||||
|
messages=messages,
|
||||||
|
llm_provider=LLM_PROVIDER,
|
||||||
|
model=O3_MINI_MODEL, # Using reasoning model for better question generation
|
||||||
|
temperature=0.7,
|
||||||
|
max_tokens=500,
|
||||||
|
reasoning_effort=ReasoningEfforts.High.value
|
||||||
|
)
|
||||||
|
|
||||||
|
# Parse questions from response
|
||||||
|
questions = [q.replace('Question:', '').strip()
|
||||||
|
for q in response.split('\n')
|
||||||
|
if q.strip().startswith('Question:')]
|
||||||
|
return questions[:num_questions]
|
||||||
|
|
||||||
|
async def generate_serp_queries(self, query: str, num_queries: int = 3) -> List[Dict[str, str]]:
|
||||||
|
"""Generate SERP queries for research"""
|
||||||
|
messages = [
|
||||||
|
{"role": "system", "content": "You are an expert researcher generating search queries."},
|
||||||
|
{"role": "user", "content": f"Given the following prompt, generate {num_queries} unique search queries to research the topic thoroughly. For each query, provide a research goal. Format as 'Query: <query>' followed by 'Goal: <goal>' for each pair: {query}"}
|
||||||
|
]
|
||||||
|
|
||||||
|
response = await create_chat_completion(
|
||||||
|
messages=messages,
|
||||||
|
llm_provider=LLM_PROVIDER,
|
||||||
|
model=GPT4_MODEL, # Using GPT-4 for general task
|
||||||
|
temperature=0.7,
|
||||||
|
max_tokens=1000
|
||||||
|
)
|
||||||
|
|
||||||
|
# Parse queries and goals from response
|
||||||
|
lines = response.split('\n')
|
||||||
|
queries = []
|
||||||
|
current_query = {}
|
||||||
|
|
||||||
|
for line in lines:
|
||||||
|
line = line.strip()
|
||||||
|
if line.startswith('Query:'):
|
||||||
|
if current_query:
|
||||||
|
queries.append(current_query)
|
||||||
|
current_query = {'query': line.replace('Query:', '').strip()}
|
||||||
|
elif line.startswith('Goal:') and current_query:
|
||||||
|
current_query['researchGoal'] = line.replace('Goal:', '').strip()
|
||||||
|
|
||||||
|
if current_query:
|
||||||
|
queries.append(current_query)
|
||||||
|
|
||||||
|
return queries[:num_queries]
|
||||||
|
|
||||||
|
async def process_serp_result(self, query: str, context: str, num_learnings: int = 3) -> Dict[str, List[str]]:
|
||||||
|
"""Process research results to extract learnings and follow-up questions"""
|
||||||
|
messages = [
|
||||||
|
{"role": "system", "content": "You are an expert researcher analyzing search results."},
|
||||||
|
{"role": "user", "content": f"Given the following research results for the query '{query}', extract key learnings and suggest follow-up questions. For each learning, include a citation to the source URL if available. Format each learning as 'Learning [source_url]: <insight>' and each question as 'Question: <question>':\n\n{context}"}
|
||||||
|
]
|
||||||
|
|
||||||
|
response = await create_chat_completion(
|
||||||
|
messages=messages,
|
||||||
|
llm_provider=LLM_PROVIDER,
|
||||||
|
model=O3_MINI_MODEL, # Using reasoning model for analysis
|
||||||
|
temperature=0.7,
|
||||||
|
max_tokens=1000,
|
||||||
|
reasoning_effort=ReasoningEfforts.High.value
|
||||||
|
)
|
||||||
|
|
||||||
|
# Parse learnings and questions with citations
|
||||||
|
lines = response.split('\n')
|
||||||
|
learnings = []
|
||||||
|
questions = []
|
||||||
|
citations = {}
|
||||||
|
|
||||||
|
for line in lines:
|
||||||
|
line = line.strip()
|
||||||
|
if line.startswith('Learning'):
|
||||||
|
# Extract URL if present in square brackets
|
||||||
|
import re
|
||||||
|
url_match = re.search(r'\[(.*?)\]:', line)
|
||||||
|
if url_match:
|
||||||
|
url = url_match.group(1)
|
||||||
|
learning = line.split(':', 1)[1].strip()
|
||||||
|
learnings.append(learning)
|
||||||
|
citations[learning] = url
|
||||||
|
else:
|
||||||
|
learnings.append(line.replace('Learning:', '').strip())
|
||||||
|
elif line.startswith('Question:'):
|
||||||
|
questions.append(line.replace('Question:', '').strip())
|
||||||
|
|
||||||
|
return {
|
||||||
|
'learnings': learnings[:num_learnings],
|
||||||
|
'followUpQuestions': questions[:num_learnings],
|
||||||
|
'citations': citations
|
||||||
|
}
|
||||||
|
|
||||||
|
async def deep_research(
|
||||||
|
self,
|
||||||
|
query: str,
|
||||||
|
breadth: int,
|
||||||
|
depth: int,
|
||||||
|
learnings: List[str] = None,
|
||||||
|
citations: Dict[str, str] = None,
|
||||||
|
visited_urls: Set[str] = None,
|
||||||
|
on_progress = None
|
||||||
|
) -> Dict[str, Any]:
|
||||||
|
"""Conduct deep iterative research"""
|
||||||
|
if learnings is None:
|
||||||
|
learnings = []
|
||||||
|
if citations is None:
|
||||||
|
citations = {}
|
||||||
|
if visited_urls is None:
|
||||||
|
visited_urls = set()
|
||||||
|
|
||||||
|
progress = ResearchProgress(depth, breadth)
|
||||||
|
|
||||||
|
if on_progress:
|
||||||
|
on_progress(progress)
|
||||||
|
|
||||||
|
# Generate search queries
|
||||||
|
serp_queries = await self.generate_serp_queries(query, num_queries=breadth)
|
||||||
|
progress.total_queries = len(serp_queries)
|
||||||
|
|
||||||
|
all_learnings = learnings.copy()
|
||||||
|
all_citations = citations.copy()
|
||||||
|
all_visited_urls = visited_urls.copy()
|
||||||
|
|
||||||
|
# Process queries with concurrency limit
|
||||||
|
semaphore = asyncio.Semaphore(self.concurrency_limit)
|
||||||
|
|
||||||
|
async def process_query(serp_query: Dict[str, str]) -> Optional[Dict[str, Any]]:
|
||||||
|
async with semaphore:
|
||||||
|
try:
|
||||||
|
progress.current_query = serp_query['query']
|
||||||
|
if on_progress:
|
||||||
|
on_progress(progress)
|
||||||
|
|
||||||
|
# Initialize researcher for this query
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=serp_query['query'],
|
||||||
|
report_type=ReportType.ResearchReport.value,
|
||||||
|
report_source=ReportSource.Web.value,
|
||||||
|
tone=self.tone,
|
||||||
|
websocket=self.websocket,
|
||||||
|
config_path=self.config_path,
|
||||||
|
headers=self.headers
|
||||||
|
)
|
||||||
|
|
||||||
|
# Conduct research
|
||||||
|
await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Get results
|
||||||
|
context = researcher.context
|
||||||
|
visited = set(researcher.visited_urls)
|
||||||
|
|
||||||
|
# Process results
|
||||||
|
results = await self.process_serp_result(
|
||||||
|
query=serp_query['query'],
|
||||||
|
context=context
|
||||||
|
)
|
||||||
|
|
||||||
|
# Update progress
|
||||||
|
progress.completed_queries += 1
|
||||||
|
if on_progress:
|
||||||
|
on_progress(progress)
|
||||||
|
|
||||||
|
return {
|
||||||
|
'learnings': results['learnings'],
|
||||||
|
'visited_urls': visited,
|
||||||
|
'followUpQuestions': results['followUpQuestions'],
|
||||||
|
'researchGoal': serp_query['researchGoal'],
|
||||||
|
'citations': results['citations']
|
||||||
|
}
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Error processing query '{serp_query['query']}': {str(e)}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
# Process queries concurrently with limit
|
||||||
|
tasks = [process_query(query) for query in serp_queries]
|
||||||
|
results = await asyncio.gather(*tasks)
|
||||||
|
results = [r for r in results if r is not None] # Filter out failed queries
|
||||||
|
|
||||||
|
# Collect all results
|
||||||
|
for result in results:
|
||||||
|
all_learnings.extend(result['learnings'])
|
||||||
|
all_visited_urls.update(set(result['visited_urls']))
|
||||||
|
all_citations.update(result['citations'])
|
||||||
|
|
||||||
|
# Continue deeper if needed
|
||||||
|
if depth > 1:
|
||||||
|
new_breadth = max(2, breadth // 2)
|
||||||
|
new_depth = depth - 1
|
||||||
|
|
||||||
|
# Create next query from research goal and follow-up questions
|
||||||
|
next_query = f"""
|
||||||
|
Previous research goal: {result['researchGoal']}
|
||||||
|
Follow-up questions: {' '.join(result['followUpQuestions'])}
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Recursive research
|
||||||
|
deeper_results = await self.deep_research(
|
||||||
|
query=next_query,
|
||||||
|
breadth=new_breadth,
|
||||||
|
depth=new_depth,
|
||||||
|
learnings=all_learnings,
|
||||||
|
citations=all_citations,
|
||||||
|
visited_urls=all_visited_urls,
|
||||||
|
on_progress=on_progress
|
||||||
|
)
|
||||||
|
|
||||||
|
all_learnings = deeper_results['learnings']
|
||||||
|
all_visited_urls = set(deeper_results['visited_urls'])
|
||||||
|
all_citations.update(deeper_results['citations'])
|
||||||
|
|
||||||
|
return {
|
||||||
|
'learnings': list(set(all_learnings)),
|
||||||
|
'visited_urls': list(all_visited_urls),
|
||||||
|
'citations': all_citations
|
||||||
|
}
|
||||||
|
|
||||||
|
async def run(self, on_progress=None) -> str:
|
||||||
|
"""Run the deep research process and generate final report"""
|
||||||
|
# Get initial feedback
|
||||||
|
follow_up_questions = await self.generate_feedback(self.query)
|
||||||
|
|
||||||
|
# Collect answers (this would normally come from user interaction)
|
||||||
|
answers = ["Automatically proceeding with research"] * len(follow_up_questions)
|
||||||
|
|
||||||
|
# Combine query and Q&A
|
||||||
|
combined_query = f"""
|
||||||
|
Initial Query: {self.query}
|
||||||
|
Follow-up Questions and Answers:
|
||||||
|
{' '.join([f'Q: {q}\nA: {a}' for q, a in zip(follow_up_questions, answers)])}
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Run deep research
|
||||||
|
results = await self.deep_research(
|
||||||
|
query=combined_query,
|
||||||
|
breadth=self.breadth,
|
||||||
|
depth=self.depth,
|
||||||
|
on_progress=on_progress
|
||||||
|
)
|
||||||
|
|
||||||
|
# Generate final report
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=self.query,
|
||||||
|
report_type=ReportType.DetailedReport.value,
|
||||||
|
report_source=ReportSource.Web.value,
|
||||||
|
tone=self.tone,
|
||||||
|
websocket=self.websocket,
|
||||||
|
config_path=self.config_path,
|
||||||
|
headers=self.headers
|
||||||
|
)
|
||||||
|
|
||||||
|
# Prepare context with citations
|
||||||
|
context_with_citations = []
|
||||||
|
for learning in results['learnings']:
|
||||||
|
citation = results['citations'].get(learning, '')
|
||||||
|
if citation:
|
||||||
|
context_with_citations.append(f"{learning} [Source: {citation}]")
|
||||||
|
else:
|
||||||
|
context_with_citations.append(learning)
|
||||||
|
|
||||||
|
# Set enhanced context for final report
|
||||||
|
researcher.context = "\n".join(context_with_citations)
|
||||||
|
researcher.visited_urls = set(results['visited_urls'])
|
||||||
|
|
||||||
|
# Generate report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from backend.utils import write_md_to_pdf
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
|
||||||
|
async def main(task: str):
|
||||||
|
# Progress callback
|
||||||
|
def on_progress(progress):
|
||||||
|
print(f"Depth: {progress.current_depth}/{progress.total_depth}")
|
||||||
|
print(f"Breadth: {progress.current_breadth}/{progress.total_breadth}")
|
||||||
|
print(f"Queries: {progress.completed_queries}/{progress.total_queries}")
|
||||||
|
if progress.current_query:
|
||||||
|
print(f"Current query: {progress.current_query}")
|
||||||
|
|
||||||
|
# Initialize researcher with deep research type
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=task,
|
||||||
|
report_type="deep", # This will trigger deep research
|
||||||
|
)
|
||||||
|
|
||||||
|
# Run research with progress tracking
|
||||||
|
print("Starting deep research...")
|
||||||
|
context = await researcher.conduct_research(on_progress=on_progress)
|
||||||
|
print("\nResearch completed. Generating report...")
|
||||||
|
|
||||||
|
# Generate the final report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
await write_md_to_pdf(report, "deep_research_report")
|
||||||
|
print(f"\nFinal Report: {report}")
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "What are the most effective ways for beginners to start investing?"
|
||||||
|
asyncio.run(main(query))
|
||||||
@ -0,0 +1,12 @@
|
|||||||
|
## Detailed Reports
|
||||||
|
|
||||||
|
Introducing long and detailed reports, with a completely new architecture inspired by the latest [STORM](https://arxiv.org/abs/2402.14207) paper.
|
||||||
|
|
||||||
|
In this method we do the following:
|
||||||
|
|
||||||
|
1. Trigger Initial GPT Researcher report based on task
|
||||||
|
2. Generate subtopics from research summary
|
||||||
|
3. For each subtopic the headers of the subtopic report are extracted and accumulated
|
||||||
|
4. For each subtopic a report is generated making sure that any information about the headers accumulated until now are not re-generated.
|
||||||
|
5. An additional introduction section is written along with a table of contents constructed from the entire report.
|
||||||
|
6. The final report is constructed by appending these : Intro + Table of contents + Subsection reports
|
||||||
@ -0,0 +1,151 @@
|
|||||||
|
import asyncio
|
||||||
|
from typing import List, Dict, Set, Optional, Any
|
||||||
|
from fastapi import WebSocket
|
||||||
|
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
|
||||||
|
class DetailedReport:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
query: str,
|
||||||
|
report_type: str,
|
||||||
|
report_source: str,
|
||||||
|
source_urls: List[str] = [],
|
||||||
|
document_urls: List[str] = [],
|
||||||
|
query_domains: List[str] = [],
|
||||||
|
config_path: str = None,
|
||||||
|
tone: Any = "",
|
||||||
|
websocket: WebSocket = None,
|
||||||
|
subtopics: List[Dict] = [],
|
||||||
|
headers: Optional[Dict] = None,
|
||||||
|
complement_source_urls: bool = False,
|
||||||
|
language: str = "english",
|
||||||
|
):
|
||||||
|
self.query = query
|
||||||
|
self.report_type = report_type
|
||||||
|
self.report_source = report_source
|
||||||
|
self.source_urls = source_urls
|
||||||
|
self.document_urls = document_urls
|
||||||
|
self.query_domains = query_domains
|
||||||
|
self.config_path = config_path
|
||||||
|
self.tone = tone
|
||||||
|
self.websocket = websocket
|
||||||
|
self.subtopics = subtopics
|
||||||
|
self.headers = headers or {}
|
||||||
|
self.complement_source_urls = complement_source_urls
|
||||||
|
self.language = language
|
||||||
|
self.gpt_researcher = GPTResearcher(
|
||||||
|
query=self.query,
|
||||||
|
query_domains=self.query_domains,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source=self.report_source,
|
||||||
|
source_urls=self.source_urls,
|
||||||
|
document_urls=self.document_urls,
|
||||||
|
config_path=self.config_path,
|
||||||
|
tone=self.tone,
|
||||||
|
websocket=self.websocket,
|
||||||
|
headers=self.headers,
|
||||||
|
complement_source_urls=self.complement_source_urls,
|
||||||
|
language=self.language
|
||||||
|
)
|
||||||
|
self.existing_headers: List[Dict] = []
|
||||||
|
self.global_context: List[str] = []
|
||||||
|
self.global_written_sections: List[str] = []
|
||||||
|
self.global_urls: Set[str] = set(
|
||||||
|
self.source_urls) if self.source_urls else set()
|
||||||
|
|
||||||
|
async def run(self) -> str:
|
||||||
|
await self._initial_research()
|
||||||
|
subtopics = await self._get_all_subtopics()
|
||||||
|
report_introduction = await self.gpt_researcher.write_introduction()
|
||||||
|
_, report_body = await self._generate_subtopic_reports(subtopics)
|
||||||
|
self.gpt_researcher.visited_urls.update(self.global_urls)
|
||||||
|
report = await self._construct_detailed_report(report_introduction, report_body)
|
||||||
|
return report
|
||||||
|
|
||||||
|
async def _initial_research(self) -> None:
|
||||||
|
await self.gpt_researcher.conduct_research()
|
||||||
|
self.global_context = self.gpt_researcher.context
|
||||||
|
self.global_urls = self.gpt_researcher.visited_urls
|
||||||
|
|
||||||
|
async def _get_all_subtopics(self) -> List[Dict]:
|
||||||
|
subtopics_data = await self.gpt_researcher.get_subtopics()
|
||||||
|
|
||||||
|
all_subtopics = []
|
||||||
|
if subtopics_data and subtopics_data.subtopics:
|
||||||
|
for subtopic in subtopics_data.subtopics:
|
||||||
|
all_subtopics.append({"task": subtopic.task})
|
||||||
|
else:
|
||||||
|
print(f"Unexpected subtopics data format: {subtopics_data}")
|
||||||
|
|
||||||
|
return all_subtopics
|
||||||
|
|
||||||
|
async def _generate_subtopic_reports(self, subtopics: List[Dict]) -> tuple:
|
||||||
|
subtopic_reports = []
|
||||||
|
subtopics_report_body = ""
|
||||||
|
|
||||||
|
for subtopic in subtopics:
|
||||||
|
result = await self._get_subtopic_report(subtopic)
|
||||||
|
if result["report"]:
|
||||||
|
subtopic_reports.append(result)
|
||||||
|
subtopics_report_body += f"\n\n\n{result['report']}"
|
||||||
|
|
||||||
|
return subtopic_reports, subtopics_report_body
|
||||||
|
|
||||||
|
async def _get_subtopic_report(self, subtopic: Dict) -> Dict[str, str]:
|
||||||
|
current_subtopic_task = subtopic.get("task")
|
||||||
|
subtopic_assistant = GPTResearcher(
|
||||||
|
query=current_subtopic_task,
|
||||||
|
query_domains=self.query_domains,
|
||||||
|
report_type="subtopic_report",
|
||||||
|
report_source=self.report_source,
|
||||||
|
websocket=self.websocket,
|
||||||
|
headers=self.headers,
|
||||||
|
parent_query=self.query,
|
||||||
|
subtopics=self.subtopics,
|
||||||
|
visited_urls=self.global_urls,
|
||||||
|
agent=self.gpt_researcher.agent,
|
||||||
|
role=self.gpt_researcher.role,
|
||||||
|
tone=self.tone,
|
||||||
|
complement_source_urls=self.complement_source_urls,
|
||||||
|
source_urls=self.source_urls,
|
||||||
|
language=self.language
|
||||||
|
)
|
||||||
|
|
||||||
|
subtopic_assistant.context = list(set(self.global_context))
|
||||||
|
await subtopic_assistant.conduct_research()
|
||||||
|
|
||||||
|
draft_section_titles = await subtopic_assistant.get_draft_section_titles(current_subtopic_task)
|
||||||
|
|
||||||
|
if not isinstance(draft_section_titles, str):
|
||||||
|
draft_section_titles = str(draft_section_titles)
|
||||||
|
|
||||||
|
parse_draft_section_titles = self.gpt_researcher.extract_headers(draft_section_titles)
|
||||||
|
parse_draft_section_titles_text = [header.get(
|
||||||
|
"text", "") for header in parse_draft_section_titles]
|
||||||
|
|
||||||
|
relevant_contents = await subtopic_assistant.get_similar_written_contents_by_draft_section_titles(
|
||||||
|
current_subtopic_task, parse_draft_section_titles_text, self.global_written_sections
|
||||||
|
)
|
||||||
|
|
||||||
|
subtopic_report = await subtopic_assistant.write_report(self.existing_headers, relevant_contents)
|
||||||
|
|
||||||
|
self.global_written_sections.extend(self.gpt_researcher.extract_sections(subtopic_report))
|
||||||
|
self.global_context = list(set(subtopic_assistant.context))
|
||||||
|
self.global_urls.update(subtopic_assistant.visited_urls)
|
||||||
|
|
||||||
|
self.existing_headers.append({
|
||||||
|
"subtopic task": current_subtopic_task,
|
||||||
|
"headers": self.gpt_researcher.extract_headers(subtopic_report),
|
||||||
|
})
|
||||||
|
|
||||||
|
return {"topic": subtopic, "report": subtopic_report}
|
||||||
|
|
||||||
|
async def _construct_detailed_report(self, introduction: str, report_body: str) -> str:
|
||||||
|
toc = self.gpt_researcher.table_of_contents(report_body)
|
||||||
|
conclusion = await self.gpt_researcher.write_report_conclusion(report_body)
|
||||||
|
conclusion_with_references = self.gpt_researcher.add_references(
|
||||||
|
conclusion, self.gpt_researcher.visited_urls)
|
||||||
|
report = f"{introduction}\n\n{toc}\n\n{report_body}\n\n{conclusion_with_references}"
|
||||||
|
return report
|
||||||
16
systems/research/gpt-researcher/backend/server/app.py
Normal file
@ -0,0 +1,16 @@
|
|||||||
|
from fastapi import FastAPI
|
||||||
|
from fastapi.middleware.cors import CORSMiddleware
|
||||||
|
import logging
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
app = FastAPI()
|
||||||
|
|
||||||
|
# Add CORS middleware
|
||||||
|
app.add_middleware(
|
||||||
|
CORSMiddleware,
|
||||||
|
allow_origins=["*"], # In production, replace with your frontend domain
|
||||||
|
allow_credentials=True,
|
||||||
|
allow_methods=["*"],
|
||||||
|
allow_headers=["*"],
|
||||||
|
)
|
||||||
@ -0,0 +1,83 @@
|
|||||||
|
import logging
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
from datetime import datetime
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
class JSONResearchHandler:
|
||||||
|
def __init__(self, json_file):
|
||||||
|
self.json_file = json_file
|
||||||
|
self.research_data = {
|
||||||
|
"timestamp": datetime.now().isoformat(),
|
||||||
|
"events": [],
|
||||||
|
"content": {
|
||||||
|
"query": "",
|
||||||
|
"sources": [],
|
||||||
|
"context": [],
|
||||||
|
"report": "",
|
||||||
|
"costs": 0.0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
def log_event(self, event_type: str, data: dict):
|
||||||
|
self.research_data["events"].append({
|
||||||
|
"timestamp": datetime.now().isoformat(),
|
||||||
|
"type": event_type,
|
||||||
|
"data": data
|
||||||
|
})
|
||||||
|
self._save_json()
|
||||||
|
|
||||||
|
def update_content(self, key: str, value):
|
||||||
|
self.research_data["content"][key] = value
|
||||||
|
self._save_json()
|
||||||
|
|
||||||
|
def _save_json(self):
|
||||||
|
with open(self.json_file, 'w') as f:
|
||||||
|
json.dump(self.research_data, f, indent=2)
|
||||||
|
|
||||||
|
def setup_research_logging():
|
||||||
|
# Create logs directory if it doesn't exist
|
||||||
|
logs_dir = Path("logs")
|
||||||
|
logs_dir.mkdir(exist_ok=True)
|
||||||
|
|
||||||
|
# Generate timestamp for log files
|
||||||
|
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||||
|
|
||||||
|
# Create log file paths
|
||||||
|
log_file = logs_dir / f"research_{timestamp}.log"
|
||||||
|
json_file = logs_dir / f"research_{timestamp}.json"
|
||||||
|
|
||||||
|
# Configure file handler for research logs
|
||||||
|
file_handler = logging.FileHandler(log_file)
|
||||||
|
file_handler.setLevel(logging.INFO)
|
||||||
|
file_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
|
||||||
|
|
||||||
|
# Get research logger and configure it
|
||||||
|
research_logger = logging.getLogger('research')
|
||||||
|
research_logger.setLevel(logging.INFO)
|
||||||
|
|
||||||
|
# Remove any existing handlers to avoid duplicates
|
||||||
|
research_logger.handlers.clear()
|
||||||
|
|
||||||
|
# Add file handler
|
||||||
|
research_logger.addHandler(file_handler)
|
||||||
|
|
||||||
|
# Add stream handler for console output
|
||||||
|
console_handler = logging.StreamHandler()
|
||||||
|
console_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
|
||||||
|
research_logger.addHandler(console_handler)
|
||||||
|
|
||||||
|
# Prevent propagation to root logger to avoid duplicate logs
|
||||||
|
research_logger.propagate = False
|
||||||
|
|
||||||
|
# Create JSON handler
|
||||||
|
json_handler = JSONResearchHandler(json_file)
|
||||||
|
|
||||||
|
return str(log_file), str(json_file), research_logger, json_handler
|
||||||
|
|
||||||
|
# Create a function to get the logger and JSON handler
|
||||||
|
def get_research_logger():
|
||||||
|
return logging.getLogger('research')
|
||||||
|
|
||||||
|
def get_json_handler():
|
||||||
|
return getattr(logging.getLogger('research'), 'json_handler', None)
|
||||||
204
systems/research/gpt-researcher/backend/server/server.py
Normal file
@ -0,0 +1,204 @@
|
|||||||
|
import json
|
||||||
|
import os
|
||||||
|
from typing import Dict, List
|
||||||
|
import time
|
||||||
|
|
||||||
|
from fastapi import FastAPI, Request, WebSocket, WebSocketDisconnect, File, UploadFile, BackgroundTasks
|
||||||
|
from fastapi.middleware.cors import CORSMiddleware
|
||||||
|
from fastapi.staticfiles import StaticFiles
|
||||||
|
from fastapi.templating import Jinja2Templates
|
||||||
|
from fastapi.responses import FileResponse
|
||||||
|
from pydantic import BaseModel
|
||||||
|
|
||||||
|
from backend.server.websocket_manager import WebSocketManager
|
||||||
|
from backend.server.server_utils import (
|
||||||
|
get_config_dict, sanitize_filename,
|
||||||
|
update_environment_variables, handle_file_upload, handle_file_deletion,
|
||||||
|
execute_multi_agents, handle_websocket_communication
|
||||||
|
)
|
||||||
|
|
||||||
|
from backend.server.websocket_manager import run_agent
|
||||||
|
from backend.utils import write_md_to_word, write_md_to_pdf
|
||||||
|
from gpt_researcher.utils.logging_config import setup_research_logging
|
||||||
|
from gpt_researcher.utils.enum import Tone
|
||||||
|
|
||||||
|
import logging
|
||||||
|
|
||||||
|
# Get logger instance
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
# Don't override parent logger settings
|
||||||
|
logger.propagate = True
|
||||||
|
|
||||||
|
logging.basicConfig(
|
||||||
|
level=logging.INFO,
|
||||||
|
format="%(asctime)s - %(levelname)s - %(message)s",
|
||||||
|
handlers=[
|
||||||
|
logging.StreamHandler() # Only log to console
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
# Models
|
||||||
|
|
||||||
|
|
||||||
|
class ResearchRequest(BaseModel):
|
||||||
|
task: str
|
||||||
|
report_type: str
|
||||||
|
report_source: str
|
||||||
|
tone: str
|
||||||
|
headers: dict | None = None
|
||||||
|
repo_name: str
|
||||||
|
branch_name: str
|
||||||
|
generate_in_background: bool = True
|
||||||
|
|
||||||
|
|
||||||
|
class ConfigRequest(BaseModel):
|
||||||
|
ANTHROPIC_API_KEY: str
|
||||||
|
TAVILY_API_KEY: str
|
||||||
|
LANGCHAIN_TRACING_V2: str
|
||||||
|
LANGCHAIN_API_KEY: str
|
||||||
|
OPENAI_API_KEY: str
|
||||||
|
DOC_PATH: str
|
||||||
|
RETRIEVER: str
|
||||||
|
GOOGLE_API_KEY: str = ''
|
||||||
|
GOOGLE_CX_KEY: str = ''
|
||||||
|
BING_API_KEY: str = ''
|
||||||
|
SEARCHAPI_API_KEY: str = ''
|
||||||
|
SERPAPI_API_KEY: str = ''
|
||||||
|
SERPER_API_KEY: str = ''
|
||||||
|
SEARX_URL: str = ''
|
||||||
|
XAI_API_KEY: str
|
||||||
|
DEEPSEEK_API_KEY: str
|
||||||
|
|
||||||
|
|
||||||
|
# App initialization
|
||||||
|
app = FastAPI()
|
||||||
|
|
||||||
|
# Static files and templates
|
||||||
|
app.mount("/site", StaticFiles(directory="./frontend"), name="site")
|
||||||
|
app.mount("/static", StaticFiles(directory="./frontend/static"), name="static")
|
||||||
|
templates = Jinja2Templates(directory="./frontend")
|
||||||
|
|
||||||
|
# WebSocket manager
|
||||||
|
manager = WebSocketManager()
|
||||||
|
|
||||||
|
# Middleware
|
||||||
|
app.add_middleware(
|
||||||
|
CORSMiddleware,
|
||||||
|
allow_origins=["http://localhost:3000"],
|
||||||
|
allow_credentials=True,
|
||||||
|
allow_methods=["*"],
|
||||||
|
allow_headers=["*"],
|
||||||
|
)
|
||||||
|
|
||||||
|
# Constants
|
||||||
|
DOC_PATH = os.getenv("DOC_PATH", "./my-docs")
|
||||||
|
|
||||||
|
# Startup event
|
||||||
|
|
||||||
|
|
||||||
|
@app.on_event("startup")
|
||||||
|
def startup_event():
|
||||||
|
os.makedirs("outputs", exist_ok=True)
|
||||||
|
app.mount("/outputs", StaticFiles(directory="outputs"), name="outputs")
|
||||||
|
# os.makedirs(DOC_PATH, exist_ok=True) # Commented out to avoid creating the folder if not needed
|
||||||
|
|
||||||
|
|
||||||
|
# Routes
|
||||||
|
|
||||||
|
|
||||||
|
@app.get("/")
|
||||||
|
async def read_root(request: Request):
|
||||||
|
return templates.TemplateResponse("index.html", {"request": request, "report": None})
|
||||||
|
|
||||||
|
|
||||||
|
@app.get("/report/{research_id}")
|
||||||
|
async def read_report(request: Request, research_id: str):
|
||||||
|
docx_path = os.path.join('outputs', f"{research_id}.docx")
|
||||||
|
if not os.path.exists(docx_path):
|
||||||
|
return {"message": "Report not found."}
|
||||||
|
return FileResponse(docx_path)
|
||||||
|
|
||||||
|
|
||||||
|
async def write_report(research_request: ResearchRequest, research_id: str = None):
|
||||||
|
report_information = await run_agent(
|
||||||
|
task=research_request.task,
|
||||||
|
report_type=research_request.report_type,
|
||||||
|
report_source=research_request.report_source,
|
||||||
|
source_urls=[],
|
||||||
|
document_urls=[],
|
||||||
|
tone=Tone[research_request.tone],
|
||||||
|
websocket=None,
|
||||||
|
stream_output=None,
|
||||||
|
headers=research_request.headers,
|
||||||
|
query_domains=[],
|
||||||
|
config_path="",
|
||||||
|
return_researcher=True
|
||||||
|
)
|
||||||
|
|
||||||
|
docx_path = await write_md_to_word(report_information[0], research_id)
|
||||||
|
pdf_path = await write_md_to_pdf(report_information[0], research_id)
|
||||||
|
if research_request.report_type != "multi_agents":
|
||||||
|
report, researcher = report_information
|
||||||
|
response = {
|
||||||
|
"research_id": research_id,
|
||||||
|
"research_information": {
|
||||||
|
"source_urls": researcher.get_source_urls(),
|
||||||
|
"research_costs": researcher.get_costs(),
|
||||||
|
"visited_urls": list(researcher.visited_urls),
|
||||||
|
"research_images": researcher.get_research_images(),
|
||||||
|
# "research_sources": researcher.get_research_sources(), # Raw content of sources may be very large
|
||||||
|
},
|
||||||
|
"report": report,
|
||||||
|
"docx_path": docx_path,
|
||||||
|
"pdf_path": pdf_path
|
||||||
|
}
|
||||||
|
else:
|
||||||
|
response = { "research_id": research_id, "report": "", "docx_path": docx_path, "pdf_path": pdf_path }
|
||||||
|
|
||||||
|
return response
|
||||||
|
|
||||||
|
@app.post("/report/")
|
||||||
|
async def generate_report(research_request: ResearchRequest, background_tasks: BackgroundTasks):
|
||||||
|
research_id = sanitize_filename(f"task_{int(time.time())}_{research_request.task}")
|
||||||
|
|
||||||
|
if research_request.generate_in_background:
|
||||||
|
background_tasks.add_task(write_report, research_request=research_request, research_id=research_id)
|
||||||
|
return {"message": "Your report is being generated in the background. Please check back later.",
|
||||||
|
"research_id": research_id}
|
||||||
|
else:
|
||||||
|
response = await write_report(research_request, research_id)
|
||||||
|
return response
|
||||||
|
|
||||||
|
|
||||||
|
@app.get("/files/")
|
||||||
|
async def list_files():
|
||||||
|
if not os.path.exists(DOC_PATH):
|
||||||
|
os.makedirs(DOC_PATH, exist_ok=True)
|
||||||
|
files = os.listdir(DOC_PATH)
|
||||||
|
print(f"Files in {DOC_PATH}: {files}")
|
||||||
|
return {"files": files}
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/api/multi_agents")
|
||||||
|
async def run_multi_agents():
|
||||||
|
return await execute_multi_agents(manager)
|
||||||
|
|
||||||
|
|
||||||
|
@app.post("/upload/")
|
||||||
|
async def upload_file(file: UploadFile = File(...)):
|
||||||
|
return await handle_file_upload(file, DOC_PATH)
|
||||||
|
|
||||||
|
|
||||||
|
@app.delete("/files/{filename}")
|
||||||
|
async def delete_file(filename: str):
|
||||||
|
return await handle_file_deletion(filename, DOC_PATH)
|
||||||
|
|
||||||
|
|
||||||
|
@app.websocket("/ws")
|
||||||
|
async def websocket_endpoint(websocket: WebSocket):
|
||||||
|
await manager.connect(websocket)
|
||||||
|
try:
|
||||||
|
await handle_websocket_communication(websocket, manager)
|
||||||
|
except WebSocketDisconnect:
|
||||||
|
await manager.disconnect(websocket)
|
||||||
320
systems/research/gpt-researcher/backend/server/server_utils.py
Normal file
@ -0,0 +1,320 @@
|
|||||||
|
import asyncio
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
import shutil
|
||||||
|
import traceback
|
||||||
|
from typing import Awaitable, Dict, List, Any
|
||||||
|
from fastapi.responses import JSONResponse, FileResponse
|
||||||
|
from gpt_researcher.document.document import DocumentLoader
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from backend.utils import write_md_to_pdf, write_md_to_word, write_text_to_md
|
||||||
|
from pathlib import Path
|
||||||
|
from datetime import datetime
|
||||||
|
from fastapi import HTTPException
|
||||||
|
import logging
|
||||||
|
|
||||||
|
logging.basicConfig(level=logging.DEBUG)
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
class CustomLogsHandler:
|
||||||
|
"""Custom handler to capture streaming logs from the research process"""
|
||||||
|
def __init__(self, websocket, task: str):
|
||||||
|
self.logs = []
|
||||||
|
self.websocket = websocket
|
||||||
|
sanitized_filename = sanitize_filename(f"task_{int(time.time())}_{task}")
|
||||||
|
self.log_file = os.path.join("outputs", f"{sanitized_filename}.json")
|
||||||
|
self.timestamp = datetime.now().isoformat()
|
||||||
|
# Initialize log file with metadata
|
||||||
|
os.makedirs("outputs", exist_ok=True)
|
||||||
|
with open(self.log_file, 'w') as f:
|
||||||
|
json.dump({
|
||||||
|
"timestamp": self.timestamp,
|
||||||
|
"events": [],
|
||||||
|
"content": {
|
||||||
|
"query": "",
|
||||||
|
"sources": [],
|
||||||
|
"context": [],
|
||||||
|
"report": "",
|
||||||
|
"costs": 0.0
|
||||||
|
}
|
||||||
|
}, f, indent=2)
|
||||||
|
|
||||||
|
async def send_json(self, data: Dict[str, Any]) -> None:
|
||||||
|
"""Store log data and send to websocket"""
|
||||||
|
# Send to websocket for real-time display
|
||||||
|
if self.websocket:
|
||||||
|
await self.websocket.send_json(data)
|
||||||
|
|
||||||
|
# Read current log file
|
||||||
|
with open(self.log_file, 'r') as f:
|
||||||
|
log_data = json.load(f)
|
||||||
|
|
||||||
|
# Update appropriate section based on data type
|
||||||
|
if data.get('type') == 'logs':
|
||||||
|
log_data['events'].append({
|
||||||
|
"timestamp": datetime.now().isoformat(),
|
||||||
|
"type": "event",
|
||||||
|
"data": data
|
||||||
|
})
|
||||||
|
else:
|
||||||
|
# Update content section for other types of data
|
||||||
|
log_data['content'].update(data)
|
||||||
|
|
||||||
|
# Save updated log file
|
||||||
|
with open(self.log_file, 'w') as f:
|
||||||
|
json.dump(log_data, f, indent=2)
|
||||||
|
logger.debug(f"Log entry written to: {self.log_file}")
|
||||||
|
|
||||||
|
|
||||||
|
class Researcher:
|
||||||
|
def __init__(self, query: str, report_type: str = "research_report"):
|
||||||
|
self.query = query
|
||||||
|
self.report_type = report_type
|
||||||
|
# Generate unique ID for this research task
|
||||||
|
self.research_id = f"{datetime.now().strftime('%Y%m%d_%H%M%S')}_{hash(query)}"
|
||||||
|
# Initialize logs handler with research ID
|
||||||
|
self.logs_handler = CustomLogsHandler(None, self.research_id)
|
||||||
|
self.researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type=report_type,
|
||||||
|
websocket=self.logs_handler
|
||||||
|
)
|
||||||
|
|
||||||
|
async def research(self) -> dict:
|
||||||
|
"""Conduct research and return paths to generated files"""
|
||||||
|
await self.researcher.conduct_research()
|
||||||
|
report = await self.researcher.write_report()
|
||||||
|
|
||||||
|
# Generate the files
|
||||||
|
sanitized_filename = sanitize_filename(f"task_{int(time.time())}_{self.query}")
|
||||||
|
file_paths = await generate_report_files(report, sanitized_filename)
|
||||||
|
|
||||||
|
# Get the JSON log path that was created by CustomLogsHandler
|
||||||
|
json_relative_path = os.path.relpath(self.logs_handler.log_file)
|
||||||
|
|
||||||
|
return {
|
||||||
|
"output": {
|
||||||
|
**file_paths, # Include PDF, DOCX, and MD paths
|
||||||
|
"json": json_relative_path
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
def sanitize_filename(filename: str) -> str:
|
||||||
|
# Split into components
|
||||||
|
prefix, timestamp, *task_parts = filename.split('_')
|
||||||
|
task = '_'.join(task_parts)
|
||||||
|
|
||||||
|
# Calculate max length for task portion
|
||||||
|
# 255 - len(os.getcwd()) - len("\\gpt-researcher\\outputs\\") - len("task_") - len(timestamp) - len("_.json") - safety_margin
|
||||||
|
max_task_length = 255 - len(os.getcwd()) - 24 - 5 - 10 - 6 - 5 # ~189 chars for task
|
||||||
|
|
||||||
|
# Truncate task if needed
|
||||||
|
truncated_task = task[:max_task_length] if len(task) > max_task_length else task
|
||||||
|
|
||||||
|
# Reassemble and clean the filename
|
||||||
|
sanitized = f"{prefix}_{timestamp}_{truncated_task}"
|
||||||
|
return re.sub(r"[^\w\s-]", "", sanitized).strip()
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_start_command(websocket, data: str, manager):
|
||||||
|
json_data = json.loads(data[6:])
|
||||||
|
(
|
||||||
|
task,
|
||||||
|
report_type,
|
||||||
|
source_urls,
|
||||||
|
document_urls,
|
||||||
|
tone,
|
||||||
|
headers,
|
||||||
|
report_source,
|
||||||
|
query_domains,
|
||||||
|
language,
|
||||||
|
) = extract_command_data(json_data)
|
||||||
|
|
||||||
|
if not task or not report_type:
|
||||||
|
print("Error: Missing task or report_type")
|
||||||
|
return
|
||||||
|
|
||||||
|
# Create logs handler with websocket and task
|
||||||
|
logs_handler = CustomLogsHandler(websocket, task)
|
||||||
|
# Initialize log content with query
|
||||||
|
await logs_handler.send_json({
|
||||||
|
"query": task,
|
||||||
|
"sources": [],
|
||||||
|
"context": [],
|
||||||
|
"report": ""
|
||||||
|
})
|
||||||
|
|
||||||
|
sanitized_filename = sanitize_filename(f"task_{int(time.time())}_{task}")
|
||||||
|
|
||||||
|
report = await manager.start_streaming(
|
||||||
|
task,
|
||||||
|
report_type,
|
||||||
|
report_source,
|
||||||
|
source_urls,
|
||||||
|
document_urls,
|
||||||
|
tone,
|
||||||
|
websocket,
|
||||||
|
headers,
|
||||||
|
query_domains,
|
||||||
|
language,
|
||||||
|
)
|
||||||
|
report = str(report)
|
||||||
|
file_paths = await generate_report_files(report, sanitized_filename)
|
||||||
|
# Add JSON log path to file_paths
|
||||||
|
file_paths["json"] = os.path.relpath(logs_handler.log_file)
|
||||||
|
await send_file_paths(websocket, file_paths)
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_human_feedback(data: str):
|
||||||
|
feedback_data = json.loads(data[14:]) # Remove "human_feedback" prefix
|
||||||
|
print(f"Received human feedback: {feedback_data}")
|
||||||
|
# TODO: Add logic to forward the feedback to the appropriate agent or update the research state
|
||||||
|
|
||||||
|
async def handle_chat(websocket, data: str, manager):
|
||||||
|
json_data = json.loads(data[4:])
|
||||||
|
print(f"Received chat message: {json_data.get('message')}")
|
||||||
|
await manager.chat(json_data.get("message"), websocket)
|
||||||
|
|
||||||
|
async def generate_report_files(report: str, filename: str) -> Dict[str, str]:
|
||||||
|
pdf_path = await write_md_to_pdf(report, filename)
|
||||||
|
docx_path = await write_md_to_word(report, filename)
|
||||||
|
md_path = await write_text_to_md(report, filename)
|
||||||
|
return {"pdf": pdf_path, "docx": docx_path, "md": md_path}
|
||||||
|
|
||||||
|
|
||||||
|
async def send_file_paths(websocket, file_paths: Dict[str, str]):
|
||||||
|
await websocket.send_json({"type": "path", "output": file_paths})
|
||||||
|
|
||||||
|
|
||||||
|
def get_config_dict(
|
||||||
|
langchain_api_key: str, openai_api_key: str, tavily_api_key: str,
|
||||||
|
google_api_key: str, google_cx_key: str, bing_api_key: str,
|
||||||
|
searchapi_api_key: str, serpapi_api_key: str, serper_api_key: str, searx_url: str
|
||||||
|
) -> Dict[str, str]:
|
||||||
|
return {
|
||||||
|
"LANGCHAIN_API_KEY": langchain_api_key or os.getenv("LANGCHAIN_API_KEY", ""),
|
||||||
|
"OPENAI_API_KEY": openai_api_key or os.getenv("OPENAI_API_KEY", ""),
|
||||||
|
"TAVILY_API_KEY": tavily_api_key or os.getenv("TAVILY_API_KEY", ""),
|
||||||
|
"GOOGLE_API_KEY": google_api_key or os.getenv("GOOGLE_API_KEY", ""),
|
||||||
|
"GOOGLE_CX_KEY": google_cx_key or os.getenv("GOOGLE_CX_KEY", ""),
|
||||||
|
"BING_API_KEY": bing_api_key or os.getenv("BING_API_KEY", ""),
|
||||||
|
"SEARCHAPI_API_KEY": searchapi_api_key or os.getenv("SEARCHAPI_API_KEY", ""),
|
||||||
|
"SERPAPI_API_KEY": serpapi_api_key or os.getenv("SERPAPI_API_KEY", ""),
|
||||||
|
"SERPER_API_KEY": serper_api_key or os.getenv("SERPER_API_KEY", ""),
|
||||||
|
"SEARX_URL": searx_url or os.getenv("SEARX_URL", ""),
|
||||||
|
"LANGCHAIN_TRACING_V2": os.getenv("LANGCHAIN_TRACING_V2", "true"),
|
||||||
|
"DOC_PATH": os.getenv("DOC_PATH", "./my-docs"),
|
||||||
|
"RETRIEVER": os.getenv("RETRIEVER", ""),
|
||||||
|
"EMBEDDING_MODEL": os.getenv("OPENAI_EMBEDDING_MODEL", "")
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def update_environment_variables(config: Dict[str, str]):
|
||||||
|
for key, value in config.items():
|
||||||
|
os.environ[key] = value
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_file_upload(file, DOC_PATH: str) -> Dict[str, str]:
|
||||||
|
file_path = os.path.join(DOC_PATH, os.path.basename(file.filename))
|
||||||
|
with open(file_path, "wb") as buffer:
|
||||||
|
shutil.copyfileobj(file.file, buffer)
|
||||||
|
print(f"File uploaded to {file_path}")
|
||||||
|
|
||||||
|
document_loader = DocumentLoader(DOC_PATH)
|
||||||
|
await document_loader.load()
|
||||||
|
|
||||||
|
return {"filename": file.filename, "path": file_path}
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_file_deletion(filename: str, DOC_PATH: str) -> JSONResponse:
|
||||||
|
file_path = os.path.join(DOC_PATH, os.path.basename(filename))
|
||||||
|
if os.path.exists(file_path):
|
||||||
|
os.remove(file_path)
|
||||||
|
print(f"File deleted: {file_path}")
|
||||||
|
return JSONResponse(content={"message": "File deleted successfully"})
|
||||||
|
else:
|
||||||
|
print(f"File not found: {file_path}")
|
||||||
|
return JSONResponse(status_code=404, content={"message": "File not found"})
|
||||||
|
|
||||||
|
|
||||||
|
async def execute_multi_agents(manager) -> Any:
|
||||||
|
websocket = manager.active_connections[0] if manager.active_connections else None
|
||||||
|
if websocket:
|
||||||
|
report = await run_research_task("Is AI in a hype cycle?", websocket, stream_output)
|
||||||
|
return {"report": report}
|
||||||
|
else:
|
||||||
|
return JSONResponse(status_code=400, content={"message": "No active WebSocket connection"})
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_websocket_communication(websocket, manager):
|
||||||
|
running_task: asyncio.Task | None = None
|
||||||
|
|
||||||
|
def run_long_running_task(awaitable: Awaitable) -> asyncio.Task:
|
||||||
|
async def safe_run():
|
||||||
|
try:
|
||||||
|
await awaitable
|
||||||
|
except asyncio.CancelledError:
|
||||||
|
logger.info("Task cancelled.")
|
||||||
|
raise
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Error running task: {e}\n{traceback.format_exc()}")
|
||||||
|
await websocket.send_json(
|
||||||
|
{
|
||||||
|
"type": "logs",
|
||||||
|
"content": "error",
|
||||||
|
"output": f"Error: {e}",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
return asyncio.create_task(safe_run())
|
||||||
|
|
||||||
|
try:
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
data = await websocket.receive_text()
|
||||||
|
if data == "ping":
|
||||||
|
await websocket.send_text("pong")
|
||||||
|
elif running_task and not running_task.done():
|
||||||
|
# discard any new request if a task is already running
|
||||||
|
logger.warning(
|
||||||
|
f"Received request while task is already running. Request data preview: {data[: min(20, len(data))]}..."
|
||||||
|
)
|
||||||
|
websocket.send_json(
|
||||||
|
{
|
||||||
|
"types": "logs",
|
||||||
|
"output": "Task already running. Please wait.",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
elif data.startswith("start"):
|
||||||
|
running_task = run_long_running_task(
|
||||||
|
handle_start_command(websocket, data, manager)
|
||||||
|
)
|
||||||
|
elif data.startswith("human_feedback"):
|
||||||
|
running_task = run_long_running_task(handle_human_feedback(data))
|
||||||
|
elif data.startswith("chat"):
|
||||||
|
running_task = run_long_running_task(
|
||||||
|
handle_chat(websocket, data, manager)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
print("Error: Unknown command or not enough parameters provided.")
|
||||||
|
except Exception as e:
|
||||||
|
print(f"WebSocket error: {e}")
|
||||||
|
break
|
||||||
|
finally:
|
||||||
|
if running_task and not running_task.done():
|
||||||
|
running_task.cancel()
|
||||||
|
|
||||||
|
def extract_command_data(json_data: Dict) -> tuple:
|
||||||
|
return (
|
||||||
|
json_data.get("task"),
|
||||||
|
json_data.get("report_type"),
|
||||||
|
json_data.get("source_urls"),
|
||||||
|
json_data.get("document_urls"),
|
||||||
|
json_data.get("tone"),
|
||||||
|
json_data.get("headers", {}),
|
||||||
|
json_data.get("report_source"),
|
||||||
|
json_data.get("query_domains", []),
|
||||||
|
json_data.get("language")
|
||||||
|
)
|
||||||
@ -0,0 +1,145 @@
|
|||||||
|
import asyncio
|
||||||
|
import datetime
|
||||||
|
from typing import Dict, List
|
||||||
|
|
||||||
|
from fastapi import WebSocket
|
||||||
|
|
||||||
|
from backend.report_type import BasicReport, DetailedReport
|
||||||
|
from backend.chat import ChatAgentWithMemory
|
||||||
|
|
||||||
|
from gpt_researcher.utils.enum import ReportType, Tone
|
||||||
|
from multi_agents.main import run_research_task
|
||||||
|
from gpt_researcher.actions import stream_output # Import stream_output
|
||||||
|
from backend.server.server_utils import CustomLogsHandler
|
||||||
|
|
||||||
|
|
||||||
|
class WebSocketManager:
|
||||||
|
"""Manage websockets"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
"""Initialize the WebSocketManager class."""
|
||||||
|
self.active_connections: List[WebSocket] = []
|
||||||
|
self.sender_tasks: Dict[WebSocket, asyncio.Task] = {}
|
||||||
|
self.message_queues: Dict[WebSocket, asyncio.Queue] = {}
|
||||||
|
self.chat_agent = None
|
||||||
|
|
||||||
|
async def start_sender(self, websocket: WebSocket):
|
||||||
|
"""Start the sender task."""
|
||||||
|
queue = self.message_queues.get(websocket)
|
||||||
|
if not queue:
|
||||||
|
return
|
||||||
|
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
message = await queue.get()
|
||||||
|
if message is None: # Shutdown signal
|
||||||
|
break
|
||||||
|
|
||||||
|
if websocket in self.active_connections:
|
||||||
|
if message == "ping":
|
||||||
|
await websocket.send_text("pong")
|
||||||
|
else:
|
||||||
|
await websocket.send_text(message)
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error in sender task: {e}")
|
||||||
|
break
|
||||||
|
|
||||||
|
async def connect(self, websocket: WebSocket):
|
||||||
|
"""Connect a websocket."""
|
||||||
|
try:
|
||||||
|
await websocket.accept()
|
||||||
|
self.active_connections.append(websocket)
|
||||||
|
self.message_queues[websocket] = asyncio.Queue()
|
||||||
|
self.sender_tasks[websocket] = asyncio.create_task(
|
||||||
|
self.start_sender(websocket))
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error connecting websocket: {e}")
|
||||||
|
if websocket in self.active_connections:
|
||||||
|
await self.disconnect(websocket)
|
||||||
|
|
||||||
|
async def disconnect(self, websocket: WebSocket):
|
||||||
|
"""Disconnect a websocket."""
|
||||||
|
if websocket in self.active_connections:
|
||||||
|
self.active_connections.remove(websocket)
|
||||||
|
if websocket in self.sender_tasks:
|
||||||
|
self.sender_tasks[websocket].cancel()
|
||||||
|
await self.message_queues[websocket].put(None)
|
||||||
|
del self.sender_tasks[websocket]
|
||||||
|
if websocket in self.message_queues:
|
||||||
|
del self.message_queues[websocket]
|
||||||
|
try:
|
||||||
|
await websocket.close()
|
||||||
|
except:
|
||||||
|
pass # Connection might already be closed
|
||||||
|
|
||||||
|
async def start_streaming(self, task, report_type, report_source, source_urls, document_urls, tone, websocket, headers=None, query_domains=[], language="english"):
|
||||||
|
"""Start streaming the output."""
|
||||||
|
tone = Tone[tone]
|
||||||
|
# add customized JSON config file path here
|
||||||
|
config_path = "default"
|
||||||
|
report = await run_agent(task, report_type, report_source, source_urls, document_urls, tone, websocket, headers=headers, query_domains=query_domains, config_path=config_path, language=language)
|
||||||
|
# Create new Chat Agent whenever a new report is written
|
||||||
|
self.chat_agent = ChatAgentWithMemory(report, config_path, headers)
|
||||||
|
return report
|
||||||
|
|
||||||
|
async def chat(self, message, websocket):
|
||||||
|
"""Chat with the agent based message diff"""
|
||||||
|
if self.chat_agent:
|
||||||
|
await self.chat_agent.chat(message, websocket)
|
||||||
|
else:
|
||||||
|
await websocket.send_json({"type": "chat", "content": "Knowledge empty, please run the research first to obtain knowledge"})
|
||||||
|
|
||||||
|
async def run_agent(task, report_type, report_source, source_urls, document_urls, tone: Tone, websocket, stream_output=stream_output, headers=None, query_domains=[], config_path="", return_researcher=False,language="english"):
|
||||||
|
"""Run the agent."""
|
||||||
|
# Create logs handler for this research task
|
||||||
|
logs_handler = CustomLogsHandler(websocket, task)
|
||||||
|
|
||||||
|
# Initialize researcher based on report type
|
||||||
|
if report_type == "multi_agents":
|
||||||
|
report = await run_research_task(
|
||||||
|
query=task,
|
||||||
|
websocket=logs_handler, # Use logs_handler instead of raw websocket
|
||||||
|
stream_output=stream_output,
|
||||||
|
tone=tone,
|
||||||
|
headers=headers
|
||||||
|
)
|
||||||
|
report = report.get("report", "")
|
||||||
|
|
||||||
|
elif report_type == ReportType.DetailedReport.value:
|
||||||
|
researcher = DetailedReport(
|
||||||
|
query=task,
|
||||||
|
query_domains=query_domains,
|
||||||
|
report_type=report_type,
|
||||||
|
report_source=report_source,
|
||||||
|
source_urls=source_urls,
|
||||||
|
document_urls=document_urls,
|
||||||
|
tone=tone,
|
||||||
|
config_path=config_path,
|
||||||
|
websocket=logs_handler, # Use logs_handler instead of raw websocket
|
||||||
|
headers=headers,
|
||||||
|
language=language
|
||||||
|
)
|
||||||
|
report = await researcher.run()
|
||||||
|
|
||||||
|
else:
|
||||||
|
researcher = BasicReport(
|
||||||
|
query=task,
|
||||||
|
query_domains=query_domains,
|
||||||
|
report_type=report_type,
|
||||||
|
report_source=report_source,
|
||||||
|
source_urls=source_urls,
|
||||||
|
document_urls=document_urls,
|
||||||
|
tone=tone,
|
||||||
|
config_path=config_path,
|
||||||
|
websocket=logs_handler, # Use logs_handler instead of raw websocket
|
||||||
|
headers=headers,
|
||||||
|
language=language
|
||||||
|
)
|
||||||
|
report = await researcher.run()
|
||||||
|
|
||||||
|
if report_type != "multi_agents" and return_researcher:
|
||||||
|
return report, researcher.gpt_researcher
|
||||||
|
else:
|
||||||
|
return report
|
||||||
92
systems/research/gpt-researcher/backend/utils.py
Normal file
@ -0,0 +1,92 @@
|
|||||||
|
import aiofiles
|
||||||
|
import urllib
|
||||||
|
import mistune
|
||||||
|
|
||||||
|
async def write_to_file(filename: str, text: str) -> None:
|
||||||
|
"""Asynchronously write text to a file in UTF-8 encoding.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
filename (str): The filename to write to.
|
||||||
|
text (str): The text to write.
|
||||||
|
"""
|
||||||
|
# Ensure text is a string
|
||||||
|
if not isinstance(text, str):
|
||||||
|
text = str(text)
|
||||||
|
|
||||||
|
# Convert text to UTF-8, replacing any problematic characters
|
||||||
|
text_utf8 = text.encode('utf-8', errors='replace').decode('utf-8')
|
||||||
|
|
||||||
|
async with aiofiles.open(filename, "w", encoding='utf-8') as file:
|
||||||
|
await file.write(text_utf8)
|
||||||
|
|
||||||
|
async def write_text_to_md(text: str, filename: str = "") -> str:
|
||||||
|
"""Writes text to a Markdown file and returns the file path.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text (str): Text to write to the Markdown file.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: The file path of the generated Markdown file.
|
||||||
|
"""
|
||||||
|
file_path = f"outputs/{filename[:60]}.md"
|
||||||
|
await write_to_file(file_path, text)
|
||||||
|
return urllib.parse.quote(file_path)
|
||||||
|
|
||||||
|
async def write_md_to_pdf(text: str, filename: str = "") -> str:
|
||||||
|
"""Converts Markdown text to a PDF file and returns the file path.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text (str): Markdown text to convert.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: The encoded file path of the generated PDF.
|
||||||
|
"""
|
||||||
|
file_path = f"outputs/{filename[:60]}.pdf"
|
||||||
|
|
||||||
|
try:
|
||||||
|
from md2pdf.core import md2pdf
|
||||||
|
md2pdf(file_path,
|
||||||
|
md_content=text,
|
||||||
|
# md_file_path=f"{file_path}.md",
|
||||||
|
css_file_path="./frontend/pdf_styles.css",
|
||||||
|
base_url=None)
|
||||||
|
print(f"Report written to {file_path}")
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error in converting Markdown to PDF: {e}")
|
||||||
|
return ""
|
||||||
|
|
||||||
|
encoded_file_path = urllib.parse.quote(file_path)
|
||||||
|
return encoded_file_path
|
||||||
|
|
||||||
|
async def write_md_to_word(text: str, filename: str = "") -> str:
|
||||||
|
"""Converts Markdown text to a DOCX file and returns the file path.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text (str): Markdown text to convert.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: The encoded file path of the generated DOCX.
|
||||||
|
"""
|
||||||
|
file_path = f"outputs/{filename[:60]}.docx"
|
||||||
|
|
||||||
|
try:
|
||||||
|
from docx import Document
|
||||||
|
from htmldocx import HtmlToDocx
|
||||||
|
# Convert report markdown to HTML
|
||||||
|
html = mistune.html(text)
|
||||||
|
# Create a document object
|
||||||
|
doc = Document()
|
||||||
|
# Convert the html generated from the report to document format
|
||||||
|
HtmlToDocx().add_html_to_document(html, doc)
|
||||||
|
|
||||||
|
# Saving the docx document to file_path
|
||||||
|
doc.save(file_path)
|
||||||
|
|
||||||
|
print(f"Report written to {file_path}")
|
||||||
|
|
||||||
|
encoded_file_path = urllib.parse.quote(file_path)
|
||||||
|
return encoded_file_path
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error in converting Markdown to DOCX: {e}")
|
||||||
|
return ""
|
||||||
10
systems/research/gpt-researcher/citation.cff
Normal file
@ -0,0 +1,10 @@
|
|||||||
|
cff-version: 1.0.0
|
||||||
|
message: "If you use this software, please cite it as below."
|
||||||
|
authors:
|
||||||
|
- family-names: Elovic
|
||||||
|
given-names: Assaf
|
||||||
|
title: gpt-researcher
|
||||||
|
version: 0.5.4
|
||||||
|
date-released: 2023-07-23
|
||||||
|
repository-code: https://github.com/assafelovic/gpt-researcher
|
||||||
|
url: https://gptr.dev
|
||||||
155
systems/research/gpt-researcher/cli.py
Normal file
@ -0,0 +1,155 @@
|
|||||||
|
"""
|
||||||
|
Provides a command line interface for the GPTResearcher class.
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python cli.py "<query>" --report_type <report_type> --tone <tone> --query_domains <foo.com,bar.com>
|
||||||
|
```
|
||||||
|
|
||||||
|
"""
|
||||||
|
import asyncio
|
||||||
|
import argparse
|
||||||
|
from argparse import RawTextHelpFormatter
|
||||||
|
from uuid import uuid4
|
||||||
|
import os
|
||||||
|
|
||||||
|
from dotenv import load_dotenv
|
||||||
|
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from gpt_researcher.utils.enum import ReportType, Tone
|
||||||
|
from backend.report_type import DetailedReport
|
||||||
|
|
||||||
|
# =============================================================================
|
||||||
|
# CLI
|
||||||
|
# =============================================================================
|
||||||
|
|
||||||
|
cli = argparse.ArgumentParser(
|
||||||
|
description="Generate a research report.",
|
||||||
|
# Enables the use of newlines in the help message
|
||||||
|
formatter_class=RawTextHelpFormatter)
|
||||||
|
|
||||||
|
# =====================================
|
||||||
|
# Arg: Query
|
||||||
|
# =====================================
|
||||||
|
|
||||||
|
cli.add_argument(
|
||||||
|
# Position 0 argument
|
||||||
|
"query",
|
||||||
|
type=str,
|
||||||
|
help="The query to conduct research on.")
|
||||||
|
|
||||||
|
# =====================================
|
||||||
|
# Arg: Report Type
|
||||||
|
# =====================================
|
||||||
|
|
||||||
|
choices = [report_type.value for report_type in ReportType]
|
||||||
|
|
||||||
|
report_type_descriptions = {
|
||||||
|
ReportType.ResearchReport.value: "Summary - Short and fast (~2 min)",
|
||||||
|
ReportType.DetailedReport.value: "Detailed - In depth and longer (~5 min)",
|
||||||
|
ReportType.ResourceReport.value: "",
|
||||||
|
ReportType.OutlineReport.value: "",
|
||||||
|
ReportType.CustomReport.value: "",
|
||||||
|
ReportType.SubtopicReport.value: "",
|
||||||
|
ReportType.DeepResearch.value: "Deep Research"
|
||||||
|
}
|
||||||
|
|
||||||
|
cli.add_argument(
|
||||||
|
"--report_type",
|
||||||
|
type=str,
|
||||||
|
help="The type of report to generate. Options:\n" + "\n".join(
|
||||||
|
f" {choice}: {report_type_descriptions[choice]}" for choice in choices
|
||||||
|
),
|
||||||
|
# Deserialize ReportType as a List of strings:
|
||||||
|
choices=choices,
|
||||||
|
required=True)
|
||||||
|
|
||||||
|
# =====================================
|
||||||
|
# Arg: Tone
|
||||||
|
# =====================================
|
||||||
|
|
||||||
|
cli.add_argument(
|
||||||
|
"--tone",
|
||||||
|
type=str,
|
||||||
|
help="The tone of the report (optional).",
|
||||||
|
choices=["objective", "formal", "analytical", "persuasive", "informative",
|
||||||
|
"explanatory", "descriptive", "critical", "comparative", "speculative",
|
||||||
|
"reflective", "narrative", "humorous", "optimistic", "pessimistic"],
|
||||||
|
default="objective"
|
||||||
|
)
|
||||||
|
|
||||||
|
# =====================================
|
||||||
|
# Arg: Query Domains
|
||||||
|
# =====================================
|
||||||
|
|
||||||
|
cli.add_argument(
|
||||||
|
"--query_domains",
|
||||||
|
type=str,
|
||||||
|
help="A comma-separated list of domains to search for the query.",
|
||||||
|
default=""
|
||||||
|
)
|
||||||
|
|
||||||
|
# =============================================================================
|
||||||
|
# Main
|
||||||
|
# =============================================================================
|
||||||
|
|
||||||
|
async def main(args):
|
||||||
|
"""
|
||||||
|
Conduct research on the given query, generate the report, and write
|
||||||
|
it as a markdown file to the output directory.
|
||||||
|
"""
|
||||||
|
query_domains = args.query_domains.split(",") if args.query_domains else []
|
||||||
|
|
||||||
|
if args.report_type == 'detailed_report':
|
||||||
|
detailed_report = DetailedReport(
|
||||||
|
query=args.query,
|
||||||
|
query_domains=query_domains,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="web_search",
|
||||||
|
)
|
||||||
|
|
||||||
|
report = await detailed_report.run()
|
||||||
|
else:
|
||||||
|
# Convert the simple keyword to the full Tone enum value
|
||||||
|
tone_map = {
|
||||||
|
"objective": Tone.Objective,
|
||||||
|
"formal": Tone.Formal,
|
||||||
|
"analytical": Tone.Analytical,
|
||||||
|
"persuasive": Tone.Persuasive,
|
||||||
|
"informative": Tone.Informative,
|
||||||
|
"explanatory": Tone.Explanatory,
|
||||||
|
"descriptive": Tone.Descriptive,
|
||||||
|
"critical": Tone.Critical,
|
||||||
|
"comparative": Tone.Comparative,
|
||||||
|
"speculative": Tone.Speculative,
|
||||||
|
"reflective": Tone.Reflective,
|
||||||
|
"narrative": Tone.Narrative,
|
||||||
|
"humorous": Tone.Humorous,
|
||||||
|
"optimistic": Tone.Optimistic,
|
||||||
|
"pessimistic": Tone.Pessimistic
|
||||||
|
}
|
||||||
|
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=args.query,
|
||||||
|
query_domains=query_domains,
|
||||||
|
report_type=args.report_type,
|
||||||
|
tone=tone_map[args.tone]
|
||||||
|
)
|
||||||
|
|
||||||
|
await researcher.conduct_research()
|
||||||
|
|
||||||
|
report = await researcher.write_report()
|
||||||
|
|
||||||
|
# Write the report to a file
|
||||||
|
artifact_filepath = f"outputs/{uuid4()}.md"
|
||||||
|
os.makedirs("outputs", exist_ok=True)
|
||||||
|
with open(artifact_filepath, "w") as f:
|
||||||
|
f.write(report)
|
||||||
|
|
||||||
|
print(f"Report written to '{artifact_filepath}'")
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
load_dotenv()
|
||||||
|
args = cli.parse_args()
|
||||||
|
asyncio.run(main(args))
|
||||||
70
systems/research/gpt-researcher/docker-compose.yml
Normal file
@ -0,0 +1,70 @@
|
|||||||
|
services:
|
||||||
|
gpt-researcher:
|
||||||
|
pull_policy: build
|
||||||
|
image: gptresearcher/gpt-researcher
|
||||||
|
build: ./
|
||||||
|
environment:
|
||||||
|
OPENAI_API_KEY: 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
|
||||||
|
TAVILY_API_KEY: ${TAVILY_API_KEY}
|
||||||
|
LANGCHAIN_API_KEY: ${LANGCHAIN_API_KEY}
|
||||||
|
LOGGING_LEVEL: INFO
|
||||||
|
volumes:
|
||||||
|
- ${PWD}/my-docs:/usr/src/app/my-docs:rw
|
||||||
|
- ${PWD}/outputs:/usr/src/app/outputs:rw
|
||||||
|
- ${PWD}/logs:/usr/src/app/logs:rw
|
||||||
|
user: root
|
||||||
|
restart: always
|
||||||
|
ports:
|
||||||
|
- 9000:9000
|
||||||
|
|
||||||
|
gptr-nextjs:
|
||||||
|
pull_policy: build
|
||||||
|
image: gptresearcher/gptr-nextjs
|
||||||
|
stdin_open: true
|
||||||
|
environment:
|
||||||
|
CHOKIDAR_USEPOLLING: "true"
|
||||||
|
LOGGING_LEVEL: INFO
|
||||||
|
NEXT_PUBLIC_GA_MEASUREMENT_ID: ${NEXT_PUBLIC_GA_MEASUREMENT_ID}
|
||||||
|
NEXT_PUBLIC_GPTR_API_URL: ${NEXT_PUBLIC_GPTR_API_URL}
|
||||||
|
build:
|
||||||
|
dockerfile: Dockerfile.dev
|
||||||
|
context: frontend/nextjs
|
||||||
|
volumes:
|
||||||
|
- /app/node_modules
|
||||||
|
- ./frontend/nextjs:/app
|
||||||
|
- ./frontend/nextjs/.next:/app/.next
|
||||||
|
- ./outputs:/app/outputs
|
||||||
|
restart: always
|
||||||
|
ports:
|
||||||
|
- 3000:3000
|
||||||
|
|
||||||
|
gpt-researcher-tests:
|
||||||
|
image: gptresearcher/gpt-researcher-tests
|
||||||
|
build: ./
|
||||||
|
environment:
|
||||||
|
OPENAI_API_KEY: ${OPENAI_API_KEY}
|
||||||
|
TAVILY_API_KEY: ${TAVILY_API_KEY}
|
||||||
|
LANGCHAIN_API_KEY: ${LANGCHAIN_API_KEY}
|
||||||
|
LOGGING_LEVEL: INFO
|
||||||
|
profiles: ["test"]
|
||||||
|
command: >
|
||||||
|
/bin/sh -c "
|
||||||
|
pip install pytest pytest-asyncio faiss-cpu &&
|
||||||
|
python -m pytest tests/report-types.py &&
|
||||||
|
python -m pytest tests/vector-store.py
|
||||||
|
"
|
||||||
|
|
||||||
|
discord-bot:
|
||||||
|
build:
|
||||||
|
context: ./docs/discord-bot
|
||||||
|
dockerfile: Dockerfile.dev
|
||||||
|
environment:
|
||||||
|
- DISCORD_BOT_TOKEN=${DISCORD_BOT_TOKEN}
|
||||||
|
- DISCORD_CLIENT_ID=${DISCORD_CLIENT_ID}
|
||||||
|
volumes:
|
||||||
|
- ./docs/discord-bot:/app
|
||||||
|
- /app/node_modules
|
||||||
|
ports:
|
||||||
|
- 3001:3000
|
||||||
|
profiles: ["discord"]
|
||||||
|
restart: always
|
||||||
1
systems/research/gpt-researcher/docs/CNAME
Normal file
@ -0,0 +1 @@
|
|||||||
|
docs.gptr.dev
|
||||||
31
systems/research/gpt-researcher/docs/README.md
Normal file
@ -0,0 +1,31 @@
|
|||||||
|
# Website
|
||||||
|
|
||||||
|
This website is built using [Docusaurus 2](https://docusaurus.io/), a modern static website generator.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
To build and test documentation locally, begin by downloading and installing [Node.js](https://nodejs.org/en/download/), and then installing [Yarn](https://classic.yarnpkg.com/en/).
|
||||||
|
On Windows, you can install via the npm package manager (npm) which comes bundled with Node.js:
|
||||||
|
|
||||||
|
```console
|
||||||
|
npm install --global yarn
|
||||||
|
```
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
|
||||||
|
```console
|
||||||
|
pip install pydoc-markdown
|
||||||
|
cd website
|
||||||
|
yarn install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Local Development
|
||||||
|
|
||||||
|
Navigate to the website folder and run:
|
||||||
|
|
||||||
|
```console
|
||||||
|
pydoc-markdown
|
||||||
|
yarn start
|
||||||
|
```
|
||||||
|
|
||||||
|
This command starts a local development server and opens up a browser window. Most changes are reflected live without having to restart the server.
|
||||||
3
systems/research/gpt-researcher/docs/babel.config.js
Normal file
@ -0,0 +1,3 @@
|
|||||||
|
module.exports = {
|
||||||
|
presets: [require.resolve('@docusaurus/core/lib/babel/preset')],
|
||||||
|
};
|
||||||
{kind=link}
|
After Width: | Height: | Size: 140 KiB |
@ -0,0 +1,88 @@
|
|||||||
|
---
|
||||||
|
slug: building-gpt-researcher
|
||||||
|
title: How we built GPT Researcher
|
||||||
|
authors: [assafe]
|
||||||
|
tags: [gpt-researcher, autonomous-agent, opensource, github]
|
||||||
|
---
|
||||||
|
|
||||||
|
After [AutoGPT](https://github.com/Significant-Gravitas/AutoGPT) was published, we immediately took it for a spin. The first use case that came to mind was autonomous online research. Forming objective conclusions for manual research tasks can take time, sometimes weeks, to find the right resources and information. Seeing how well AutoGPT created tasks and executed them got me thinking about the great potential of using AI to conduct comprehensive research and what it meant for the future of online research.
|
||||||
|
|
||||||
|
But the problem with AutoGPT was that it usually ran into never-ending loops, required human interference for almost every step, constantly lost track of its progress, and almost never actually completed the task.
|
||||||
|
|
||||||
|
Nonetheless, the information and context gathered during the research task were lost (such as keeping track of sources), and sometimes hallucinated.
|
||||||
|
|
||||||
|
The passion for leveraging AI for online research and the limitations I found put me on a mission to try and solve it while sharing my work with the world. This is when I created [GPT Researcher](https://github.com/assafelovic/gpt-researcher) — an open source autonomous agent for online comprehensive research.
|
||||||
|
|
||||||
|
In this article, we will share the steps that guided me toward the proposed solution.
|
||||||
|
|
||||||
|
### Moving from infinite loops to deterministic results
|
||||||
|
The first step in solving these issues was to seek a more deterministic solution that could ultimately guarantee completing any research task within a fixed time frame, without human interference.
|
||||||
|
|
||||||
|
This is when we stumbled upon the recent paper [Plan and Solve](https://arxiv.org/abs/2305.04091). The paper aims to provide a better solution for the challenges stated above. The idea is quite simple and consists of two components: first, devising a plan to divide the entire task into smaller subtasks and then carrying out the subtasks according to the plan.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As it relates to research, first create an outline of questions to research related to the task, and then deterministically execute an agent for every outline item. This approach eliminates the uncertainty in task completion by breaking the agent steps into a deterministic finite set of tasks. Once all tasks are completed, the agent concludes the research.
|
||||||
|
|
||||||
|
Following this strategy has improved the reliability of completing research tasks to 100%. Now the challenge is, how to improve quality and speed?
|
||||||
|
|
||||||
|
### Aiming for objective and unbiased results
|
||||||
|
The biggest challenge with LLMs is the lack of factuality and unbiased responses caused by hallucinations and out-of-date training sets (GPT is currently trained on datasets from 2021). But the irony is that for research tasks, it is crucial to optimize for these exact two criteria: factuality and bias.
|
||||||
|
|
||||||
|
To tackle this challenges, we assumed the following:
|
||||||
|
|
||||||
|
- Law of large numbers — More content will lead to less biased results. Especially if gathered properly.
|
||||||
|
- Leveraging LLMs for the summarization of factual information can significantly improve the overall better factuality of results.
|
||||||
|
|
||||||
|
After experimenting with LLMs for quite some time, we can say that the areas where foundation models excel are in the summarization and rewriting of given content. So, in theory, if LLMs only review given content and summarize and rewrite it, potentially it would reduce hallucinations significantly.
|
||||||
|
|
||||||
|
In addition, assuming the given content is unbiased, or at least holds opinions and information from all sides of a topic, the rewritten result would also be unbiased. So how can content be unbiased? The [law of large numbers](https://en.wikipedia.org/wiki/Law_of_large_numbers). In other words, if enough sites that hold relevant information are scraped, the possibility of biased information reduces greatly. So the idea would be to scrape just enough sites together to form an objective opinion on any topic.
|
||||||
|
|
||||||
|
Great! Sounds like, for now, we have an idea for how to create both deterministic, factual, and unbiased results. But what about the speed problem?
|
||||||
|
|
||||||
|
### Speeding up the research process
|
||||||
|
Another issue with AutoGPT is that it works synchronously. The main idea of it is to create a list of tasks and then execute them one by one. So if, let’s say, a research task requires visiting 20 sites, and each site takes around one minute to scrape and summarize, the overall research task would take a minimum of +20 minutes. That’s assuming it ever stops. But what if we could parallelize agent work?
|
||||||
|
|
||||||
|
By levering Python libraries such as asyncio, the agent tasks have been optimized to work in parallel, thus significantly reducing the time to research.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Create a list to hold the coroutine agent tasks
|
||||||
|
tasks = [async_browse(url, query, self.websocket) for url in await new_search_urls]
|
||||||
|
|
||||||
|
# Gather the results as they become available
|
||||||
|
responses = await asyncio.gather(*tasks, return_exceptions=True)
|
||||||
|
```
|
||||||
|
|
||||||
|
In the example above, we trigger scraping for all URLs in parallel, and only once all is done, continue with the task. Based on many tests, an average research task takes around three minutes (!!). That’s 85% faster than AutoGPT.
|
||||||
|
|
||||||
|
### Finalizing the research report
|
||||||
|
Finally, after aggregating as much information as possible about a given research task, the challenge is to write a comprehensive report about it.
|
||||||
|
|
||||||
|
After experimenting with several OpenAI models and even open source, I’ve concluded that the best results are currently achieved with GPT-4. The task is straightforward — provide GPT-4 as context with all the aggregated information, and ask it to write a detailed report about it given the original research task.
|
||||||
|
|
||||||
|
The prompt is as follows:
|
||||||
|
```commandline
|
||||||
|
"{research_summary}" Using the above information, answer the following question or topic: "{question}" in a detailed report — The report should focus on the answer to the question, should be well structured, informative, in depth, with facts and numbers if available, a minimum of 1,200 words and with markdown syntax and apa format. Write all source urls at the end of the report in apa format. You should write your report only based on the given information and nothing else.
|
||||||
|
```
|
||||||
|
|
||||||
|
The results are quite impressive, with some minor hallucinations in very few samples, but it’s fair to assume that as GPT improves over time, results will only get better.
|
||||||
|
|
||||||
|
### The final architecture
|
||||||
|
Now that we’ve reviewed the necessary steps of GPT Researcher, let’s break down the final architecture, as shown below:
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img align="center" height="500" src="https://cowriter-images.s3.amazonaws.com/architecture.png"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
More specifically:
|
||||||
|
- Generate an outline of research questions that form an objective opinion on any given task.
|
||||||
|
- For each research question, trigger a crawler agent that scrapes online resources for information relevant to the given task.
|
||||||
|
- For each scraped resource, keep track, filter, and summarize only if it includes relevant information.
|
||||||
|
- Finally, aggregate all summarized sources and generate a final research report.
|
||||||
|
|
||||||
|
### Going forward
|
||||||
|
The future of online research automation is heading toward a major disruption. As AI continues to improve, it is only a matter of time before AI agents can perform comprehensive research tasks for any of our day-to-day needs. AI research can disrupt areas of finance, legal, academia, health, and retail, reducing our time for each research by 95% while optimizing for factual and unbiased reports within an influx and overload of ever-growing online information.
|
||||||
|
|
||||||
|
Imagine if an AI can eventually understand and analyze any form of online content — videos, images, graphs, tables, reviews, text, audio. And imagine if it could support and analyze hundreds of thousands of words of aggregated information within a single prompt. Even imagine that AI can eventually improve in reasoning and analysis, making it much more suitable for reaching new and innovative research conclusions. And that it can do all that in minutes, if not seconds.
|
||||||
|
|
||||||
|
It’s all a matter of time and what [GPT Researcher](https://github.com/assafelovic/gpt-researcher) is all about.
|
||||||
{kind=link}
|
After Width: | Height: | Size: 132 KiB |
{kind=link}
|
After Width: | Height: | Size: 21 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
@ -0,0 +1,259 @@
|
|||||||
|
---
|
||||||
|
slug: building-openai-assistant
|
||||||
|
title: How to build an OpenAI Assistant with Internet access
|
||||||
|
authors: [assafe]
|
||||||
|
tags: [tavily, search-api, openai, assistant-api]
|
||||||
|
---
|
||||||
|
|
||||||
|
OpenAI has done it again with a [groundbreaking DevDay](https://openai.com/blog/new-models-and-developer-products-announced-at-devday) showcasing some of the latest improvements to the OpenAI suite of tools, products and services. One major release was the new [Assistants API](https://platform.openai.com/docs/assistants/overview) that makes it easier for developers to build their own assistive AI apps that have goals and can call models and tools.
|
||||||
|
|
||||||
|
The new Assistants API currently supports three types of tools: Code Interpreter, Retrieval, and Function calling. Although you might expect the Retrieval tool to support online information retrieval (such as search APIs or as ChatGPT plugins), it only supports raw data for now such as text or CSV files.
|
||||||
|
|
||||||
|
This blog will demonstrate how to leverage the latest Assistants API with online information using the function calling tool.
|
||||||
|
|
||||||
|
To skip the tutorial below, feel free to check out the full [Github Gist here](https://gist.github.com/assafelovic/579822cd42d52d80db1e1c1ff82ffffd).
|
||||||
|
|
||||||
|
At a high level, a typical integration of the Assistants API has the following steps:
|
||||||
|
|
||||||
|
- Create an [Assistant](https://platform.openai.com/docs/api-reference/assistants/createAssistant) in the API by defining its custom instructions and picking a model. If helpful, enable tools like Code Interpreter, Retrieval, and Function calling.
|
||||||
|
- Create a [Thread](https://platform.openai.com/docs/api-reference/threads) when a user starts a conversation.
|
||||||
|
- Add [Messages](https://platform.openai.com/docs/api-reference/messages) to the Thread as the user ask questions.
|
||||||
|
- [Run](https://platform.openai.com/docs/api-reference/runs) the Assistant on the Thread to trigger responses. This automatically calls the relevant tools.
|
||||||
|
|
||||||
|
As you can see below, an Assistant object includes Threads for storing and handling conversation sessions between the assistant and users, and Run for invocation of an Assistant on a Thread.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Let’s go ahead and implement these steps one by one! For the example, we will build a finance GPT that can provide insights about financial questions. We will use the [OpenAI Python SDK v1.2](https://github.com/openai/openai-python/tree/main#installation) and [Tavily Search API](https://tavily.com).
|
||||||
|
|
||||||
|
First things first, let’s define the assistant’s instructions:
|
||||||
|
|
||||||
|
```python
|
||||||
|
assistant_prompt_instruction = """You are a finance expert.
|
||||||
|
Your goal is to provide answers based on information from the internet.
|
||||||
|
You must use the provided Tavily search API function to find relevant online information.
|
||||||
|
You should never use your own knowledge to answer questions.
|
||||||
|
Please include relevant url sources in the end of your answers.
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
Next, let’s finalize step 1 and create an assistant using the latest [GPT-4 Turbo model](https://github.com/openai/openai-python/tree/main#installation) (128K context), and the call function using the [Tavily web search API](https://tavily.com/):
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Create an assistant
|
||||||
|
assistant = client.beta.assistants.create(
|
||||||
|
instructions=assistant_prompt_instruction,
|
||||||
|
model="gpt-4-1106-preview",
|
||||||
|
tools=[{
|
||||||
|
"type": "function",
|
||||||
|
"function": {
|
||||||
|
"name": "tavily_search",
|
||||||
|
"description": "Get information on recent events from the web.",
|
||||||
|
"parameters": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"query": {"type": "string", "description": "The search query to use. For example: 'Latest news on Nvidia stock performance'"},
|
||||||
|
},
|
||||||
|
"required": ["query"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}]
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
Step 2+3 are quite straight forward, we’ll initiate a new thread and update it with a user message:
|
||||||
|
|
||||||
|
```python
|
||||||
|
thread = client.beta.threads.create()
|
||||||
|
user_input = input("You: ")
|
||||||
|
message = client.beta.threads.messages.create(
|
||||||
|
thread_id=thread.id,
|
||||||
|
role="user",
|
||||||
|
content=user_input,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
Finally, we’ll run the assistant on the thread to trigger the function call and get the response:
|
||||||
|
|
||||||
|
```python
|
||||||
|
run = client.beta.threads.runs.create(
|
||||||
|
thread_id=thread.id,
|
||||||
|
assistant_id=assistant_id,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
So far so good! But this is where it gets a bit messy. Unlike with the regular GPT APIs, the Assistants API doesn’t return a synchronous response, but returns a status. This allows for asynchronous operations across assistants, but requires more overhead for fetching statuses and dealing with each manually.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To manage this status lifecycle, let’s build a function that can be reused and handles waiting for various statuses (such as ‘requires_action’):
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Function to wait for a run to complete
|
||||||
|
def wait_for_run_completion(thread_id, run_id):
|
||||||
|
while True:
|
||||||
|
time.sleep(1)
|
||||||
|
run = client.beta.threads.runs.retrieve(thread_id=thread_id, run_id=run_id)
|
||||||
|
print(f"Current run status: {run.status}")
|
||||||
|
if run.status in ['completed', 'failed', 'requires_action']:
|
||||||
|
return run
|
||||||
|
```
|
||||||
|
|
||||||
|
This function will sleep as long as the run has not been finalized such as in cases where it’s completed or requires an action from a function call.
|
||||||
|
|
||||||
|
We’re almost there! Lastly, let’s take care of when the assistant wants to call the web search API:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Function to handle tool output submission
|
||||||
|
def submit_tool_outputs(thread_id, run_id, tools_to_call):
|
||||||
|
tool_output_array = []
|
||||||
|
for tool in tools_to_call:
|
||||||
|
output = None
|
||||||
|
tool_call_id = tool.id
|
||||||
|
function_name = tool.function.name
|
||||||
|
function_args = tool.function.arguments
|
||||||
|
|
||||||
|
if function_name == "tavily_search":
|
||||||
|
output = tavily_search(query=json.loads(function_args)["query"])
|
||||||
|
|
||||||
|
if output:
|
||||||
|
tool_output_array.append({"tool_call_id": tool_call_id, "output": output})
|
||||||
|
|
||||||
|
return client.beta.threads.runs.submit_tool_outputs(
|
||||||
|
thread_id=thread_id,
|
||||||
|
run_id=run_id,
|
||||||
|
tool_outputs=tool_output_array
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
As seen above, if the assistant has reasoned that a function call should trigger, we extract the given required function params and pass back to the runnable thread. We catch this status and call our functions as seen below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
if run.status == 'requires_action':
|
||||||
|
run = submit_tool_outputs(thread.id, run.id, run.required_action.submit_tool_outputs.tool_calls)
|
||||||
|
run = wait_for_run_completion(thread.id, run.id)
|
||||||
|
```
|
||||||
|
|
||||||
|
That’s it! We now have a working OpenAI Assistant that can be used to answer financial questions using real time online information. Below is the full runnable code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
import json
|
||||||
|
import time
|
||||||
|
from openai import OpenAI
|
||||||
|
from tavily import TavilyClient
|
||||||
|
|
||||||
|
# Initialize clients with API keys
|
||||||
|
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
|
||||||
|
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
|
||||||
|
|
||||||
|
assistant_prompt_instruction = """You are a finance expert.
|
||||||
|
Your goal is to provide answers based on information from the internet.
|
||||||
|
You must use the provided Tavily search API function to find relevant online information.
|
||||||
|
You should never use your own knowledge to answer questions.
|
||||||
|
Please include relevant url sources in the end of your answers.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Function to perform a Tavily search
|
||||||
|
def tavily_search(query):
|
||||||
|
search_result = tavily_client.get_search_context(query, search_depth="advanced", max_tokens=8000)
|
||||||
|
return search_result
|
||||||
|
|
||||||
|
# Function to wait for a run to complete
|
||||||
|
def wait_for_run_completion(thread_id, run_id):
|
||||||
|
while True:
|
||||||
|
time.sleep(1)
|
||||||
|
run = client.beta.threads.runs.retrieve(thread_id=thread_id, run_id=run_id)
|
||||||
|
print(f"Current run status: {run.status}")
|
||||||
|
if run.status in ['completed', 'failed', 'requires_action']:
|
||||||
|
return run
|
||||||
|
|
||||||
|
# Function to handle tool output submission
|
||||||
|
def submit_tool_outputs(thread_id, run_id, tools_to_call):
|
||||||
|
tool_output_array = []
|
||||||
|
for tool in tools_to_call:
|
||||||
|
output = None
|
||||||
|
tool_call_id = tool.id
|
||||||
|
function_name = tool.function.name
|
||||||
|
function_args = tool.function.arguments
|
||||||
|
|
||||||
|
if function_name == "tavily_search":
|
||||||
|
output = tavily_search(query=json.loads(function_args)["query"])
|
||||||
|
|
||||||
|
if output:
|
||||||
|
tool_output_array.append({"tool_call_id": tool_call_id, "output": output})
|
||||||
|
|
||||||
|
return client.beta.threads.runs.submit_tool_outputs(
|
||||||
|
thread_id=thread_id,
|
||||||
|
run_id=run_id,
|
||||||
|
tool_outputs=tool_output_array
|
||||||
|
)
|
||||||
|
|
||||||
|
# Function to print messages from a thread
|
||||||
|
def print_messages_from_thread(thread_id):
|
||||||
|
messages = client.beta.threads.messages.list(thread_id=thread_id)
|
||||||
|
for msg in messages:
|
||||||
|
print(f"{msg.role}: {msg.content[0].text.value}")
|
||||||
|
|
||||||
|
# Create an assistant
|
||||||
|
assistant = client.beta.assistants.create(
|
||||||
|
instructions=assistant_prompt_instruction,
|
||||||
|
model="gpt-4-1106-preview",
|
||||||
|
tools=[{
|
||||||
|
"type": "function",
|
||||||
|
"function": {
|
||||||
|
"name": "tavily_search",
|
||||||
|
"description": "Get information on recent events from the web.",
|
||||||
|
"parameters": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"query": {"type": "string", "description": "The search query to use. For example: 'Latest news on Nvidia stock performance'"},
|
||||||
|
},
|
||||||
|
"required": ["query"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}]
|
||||||
|
)
|
||||||
|
assistant_id = assistant.id
|
||||||
|
print(f"Assistant ID: {assistant_id}")
|
||||||
|
|
||||||
|
# Create a thread
|
||||||
|
thread = client.beta.threads.create()
|
||||||
|
print(f"Thread: {thread}")
|
||||||
|
|
||||||
|
# Ongoing conversation loop
|
||||||
|
while True:
|
||||||
|
user_input = input("You: ")
|
||||||
|
if user_input.lower() == 'exit':
|
||||||
|
break
|
||||||
|
|
||||||
|
# Create a message
|
||||||
|
message = client.beta.threads.messages.create(
|
||||||
|
thread_id=thread.id,
|
||||||
|
role="user",
|
||||||
|
content=user_input,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Create a run
|
||||||
|
run = client.beta.threads.runs.create(
|
||||||
|
thread_id=thread.id,
|
||||||
|
assistant_id=assistant_id,
|
||||||
|
)
|
||||||
|
print(f"Run ID: {run.id}")
|
||||||
|
|
||||||
|
# Wait for run to complete
|
||||||
|
run = wait_for_run_completion(thread.id, run.id)
|
||||||
|
|
||||||
|
if run.status == 'failed':
|
||||||
|
print(run.error)
|
||||||
|
continue
|
||||||
|
elif run.status == 'requires_action':
|
||||||
|
run = submit_tool_outputs(thread.id, run.id, run.required_action.submit_tool_outputs.tool_calls)
|
||||||
|
run = wait_for_run_completion(thread.id, run.id)
|
||||||
|
|
||||||
|
# Print messages from the thread
|
||||||
|
print_messages_from_thread(thread.id)
|
||||||
|
```
|
||||||
|
|
||||||
|
The assistant can be further customized and improved using additional retrieval information, OpenAI’s coding interpreter and more. Also, you can go ahead and add more function tools to make the assistant even smarter.
|
||||||
|
|
||||||
|
Feel free to drop a comment below if you have any further questions!
|
||||||
{kind=link}
|
After Width: | Height: | Size: 91 KiB |
{kind=link}
|
After Width: | Height: | Size: 383 KiB |
@ -0,0 +1,223 @@
|
|||||||
|
---
|
||||||
|
slug: gptr-langgraph
|
||||||
|
title: How to Build the Ultimate Research Multi-Agent Assistant
|
||||||
|
authors: [assafe]
|
||||||
|
tags: [multi-skills, gpt-researcher, langchain, langgraph]
|
||||||
|
---
|
||||||
|

|
||||||
|
# Introducing the GPT Researcher Multi-Agent Assistant
|
||||||
|
### Learn how to build an autonomous research assistant using LangGraph with a team of specialized AI agents
|
||||||
|
|
||||||
|
It has only been a year since the initial release of GPT Researcher, but methods for building, testing, and deploying AI agents have already evolved significantly. That’s just the nature and speed of the current AI progress. What started as simple zero-shot or few-shot prompting, has quickly evolved to agent function calling, RAG and now finally agentic workflows (aka “flow engineering”).
|
||||||
|
|
||||||
|
Andrew Ng has [recently stated](https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/), “I think AI agent workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models. This is an important trend, and I urge everyone who works in AI to pay attention to it.”
|
||||||
|
|
||||||
|
In this article you will learn why multi-agent workflows are the current best standard and how to build the optimal autonomous research multi-agent assistant using LangGraph.
|
||||||
|
|
||||||
|
To skip this tutorial, feel free to check out the Github repo of [GPT Researcher x LangGraph](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents).
|
||||||
|
|
||||||
|
## Introducing LangGraph
|
||||||
|
LangGraph is an extension of LangChain aimed at creating agent and multi-agent flows. It adds in the ability to create cyclical flows and comes with memory built in — both important attributes for creating agents.
|
||||||
|
|
||||||
|
LangGraph provides developers with a high degree of controllability and is important for creating custom agents and flows. Nearly all agents in production are customized towards the specific use case they are trying solve. LangGraph gives you the flexibility to create arbitrary customized agents, while providing an intuitive developer experience for doing so.
|
||||||
|
|
||||||
|
Enough with the smalltalk, let’s start building!
|
||||||
|
|
||||||
|
## Building the Ultimate Autonomous Research Agent
|
||||||
|
By leveraging LangGraph, the research process can be significantly improved in depth and quality by leveraging multiple agents with specialized skills. Having every agent focus and specialize only a specific skill, allows for better separation of concerns, customizability, and further development at scale as the project grows.
|
||||||
|
|
||||||
|
Inspired by the recent STORM paper, this example showcases how a team of AI agents can work together to conduct research on a given topic, from planning to publication. This example will also leverage the leading autonomous research agent GPT Researcher.
|
||||||
|
|
||||||
|
### The Research Agent Team
|
||||||
|
The research team consists of seven LLM agents:
|
||||||
|
|
||||||
|
* **Chief Editor** — Oversees the research process and manages the team. This is the “master” agent that coordinates the other agents using LangGraph. This agent acts as the main LangGraph interface.
|
||||||
|
* **GPT Researcher** — A specialized autonomous agent that conducts in depth research on a given topic.
|
||||||
|
* **Editor** — Responsible for planning the research outline and structure.
|
||||||
|
* **Reviewer** — Validates the correctness of the research results given a set of criteria.
|
||||||
|
* **Reviser** — Revises the research results based on the feedback from the reviewer.
|
||||||
|
* **Writer** — Responsible for compiling and writing the final report.
|
||||||
|
* **Publisher** — Responsible for publishing the final report in various formats.
|
||||||
|
|
||||||
|
### Architecture
|
||||||
|
As seen below, the automation process is based on the following stages: Planning the research, data collection and analysis, review and revision, writing the report and finally publication:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
More specifically the process is as follows:
|
||||||
|
|
||||||
|
* **Browser (gpt-researcher)** — Browses the internet for initial research based on the given research task. This step is crucial for LLMs to plan the research process based on up to date and relevant information, and not rely solely on pre-trained data for a given task or topic.
|
||||||
|
* **Editor** — Plans the report outline and structure based on the initial research. The Editor is also responsible for triggering the parallel research tasks based on the planned outline.
|
||||||
|
* For each outline topic (in parallel):
|
||||||
|
* **Researcher (gpt-researcher)** — Runs an in depth research on the subtopics and writes a draft. This agent leverages the GPT Researcher Python package under the hood, for optimized, in depth and factual research report.
|
||||||
|
* **Reviewer** — Validates the correctness of the draft given a set of guidelines and provides feedback to the reviser (if any).
|
||||||
|
* **Reviser** — Revises the draft until it is satisfactory based on the reviewer feedback.
|
||||||
|
* **Writer** — Compiles and writes the final report including an introduction, conclusion and references section from the given research findings.
|
||||||
|
* **Publisher** — Publishes the final report to multi formats such as PDF, Docx, Markdown, etc.
|
||||||
|
|
||||||
|
* We will not dive into all the code since there’s a lot of it, but focus mostly on the interesting parts I’ve found valuable to share.
|
||||||
|
|
||||||
|
## Define the Graph State
|
||||||
|
One of my favorite features with LangGraph is state management. States in LangGraph are facilitated through a structured approach where developers define a GraphState that encapsulates the entire state of the application. Each node in the graph can modify this state, allowing for dynamic responses based on the evolving context of the interaction.
|
||||||
|
|
||||||
|
Like in every start of a technical design, considering the data schema throughout the application is key. In this case we’ll define a ResearchState like so:
|
||||||
|
|
||||||
|
```python
|
||||||
|
class ResearchState(TypedDict):
|
||||||
|
task: dict
|
||||||
|
initial_research: str
|
||||||
|
sections: List[str]
|
||||||
|
research_data: List[dict]
|
||||||
|
# Report layout
|
||||||
|
title: str
|
||||||
|
headers: dict
|
||||||
|
date: str
|
||||||
|
table_of_contents: str
|
||||||
|
introduction: str
|
||||||
|
conclusion: str
|
||||||
|
sources: List[str]
|
||||||
|
report: str
|
||||||
|
```
|
||||||
|
|
||||||
|
As seen above, the state is divided into two main areas: the research task and the report layout content. As data circulates through the graph agents, each agent will, in turn, generate new data based on the existing state and update it for subsequent processing further down the graph with other agents.
|
||||||
|
|
||||||
|
We can then initialize the graph with the following:
|
||||||
|
|
||||||
|
|
||||||
|
```python
|
||||||
|
from langgraph.graph import StateGraph
|
||||||
|
workflow = StateGraph(ResearchState)
|
||||||
|
```
|
||||||
|
|
||||||
|
Initializing the graph with LangGraph
|
||||||
|
As stated above, one of the great things about multi-agent development is building each agent to have specialized and scoped skills. Let’s take an example of the Researcher agent using GPT Researcher python package:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
class ResearchAgent:
|
||||||
|
def __init__(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
async def research(self, query: str):
|
||||||
|
# Initialize the researcher
|
||||||
|
researcher = GPTResearcher(parent_query=parent_query, query=query, report_type=research_report, config_path=None)
|
||||||
|
# Conduct research on the given query
|
||||||
|
await researcher.conduct_research()
|
||||||
|
# Write the report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
|
||||||
|
return report
|
||||||
|
```
|
||||||
|
|
||||||
|
As you can see above, we’ve created an instance of the Research agent. Now let’s assume we’ve done the same for each of the team’s agent. After creating all of the agents, we’d initialize the graph with LangGraph:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def init_research_team(self):
|
||||||
|
# Initialize skills
|
||||||
|
editor_agent = EditorAgent(self.task)
|
||||||
|
research_agent = ResearchAgent()
|
||||||
|
writer_agent = WriterAgent()
|
||||||
|
publisher_agent = PublisherAgent(self.output_dir)
|
||||||
|
|
||||||
|
# Define a Langchain StateGraph with the ResearchState
|
||||||
|
workflow = StateGraph(ResearchState)
|
||||||
|
|
||||||
|
# Add nodes for each agent
|
||||||
|
workflow.add_node("browser", research_agent.run_initial_research)
|
||||||
|
workflow.add_node("planner", editor_agent.plan_research)
|
||||||
|
workflow.add_node("researcher", editor_agent.run_parallel_research)
|
||||||
|
workflow.add_node("writer", writer_agent.run)
|
||||||
|
workflow.add_node("publisher", publisher_agent.run)
|
||||||
|
|
||||||
|
workflow.add_edge('browser', 'planner')
|
||||||
|
workflow.add_edge('planner', 'researcher')
|
||||||
|
workflow.add_edge('researcher', 'writer')
|
||||||
|
workflow.add_edge('writer', 'publisher')
|
||||||
|
|
||||||
|
# set up start and end nodes
|
||||||
|
workflow.set_entry_point("browser")
|
||||||
|
workflow.add_edge('publisher', END)
|
||||||
|
|
||||||
|
return workflow
|
||||||
|
```
|
||||||
|
|
||||||
|
As seen above, creating the LangGraph graph is very straight forward and consists of three main functions: add_node, add_edge and set_entry_point. With these main functions you can first add the nodes to the graph, connect the edges and finally set the starting point.
|
||||||
|
|
||||||
|
Focus check: If you’ve been following the code and architecture properly, you’ll notice that the Reviewer and Reviser agents are missing in the initialization above. Let’s dive into it!
|
||||||
|
|
||||||
|
## A Graph within a Graph to support stateful Parallelization
|
||||||
|
This was the most exciting part of my experience working with LangGraph! One exciting feature of this autonomous assistant is having a parallel run for each research task, that would be reviewed and revised based on a set of predefined guidelines.
|
||||||
|
|
||||||
|
Knowing how to leverage parallel work within a process is key for optimizing speed. But how would you trigger parallel agent work if all agents report to the same state? This can cause race conditions and inconsistencies in the final data report. To solve this, you can create a sub graph, that would be triggered from the main LangGraph instance. This sub graph would hold its own state for each parallel run, and that would solve the issues that were raised.
|
||||||
|
|
||||||
|
As we’ve done before, let’s define the LangGraph state and its agents. Since this sub graph basically reviews and revises a research draft, we’ll define the state with draft information:
|
||||||
|
|
||||||
|
```python
|
||||||
|
class DraftState(TypedDict):
|
||||||
|
task: dict
|
||||||
|
topic: str
|
||||||
|
draft: dict
|
||||||
|
review: str
|
||||||
|
revision_notes: str
|
||||||
|
```
|
||||||
|
|
||||||
|
As seen in the DraftState, we mostly care about the topic discussed, and the reviewer and revision notes as they communicate between each other to finalize the subtopic research report. To create the circular condition we’ll take advantage of the last important piece of LangGraph which is conditional edges:
|
||||||
|
|
||||||
|
```python
|
||||||
|
async def run_parallel_research(self, research_state: dict):
|
||||||
|
workflow = StateGraph(DraftState)
|
||||||
|
|
||||||
|
workflow.add_node("researcher", research_agent.run_depth_research)
|
||||||
|
workflow.add_node("reviewer", reviewer_agent.run)
|
||||||
|
workflow.add_node("reviser", reviser_agent.run)
|
||||||
|
|
||||||
|
# set up edges researcher->reviewer->reviser->reviewer...
|
||||||
|
workflow.set_entry_point("researcher")
|
||||||
|
workflow.add_edge('researcher', 'reviewer')
|
||||||
|
workflow.add_edge('reviser', 'reviewer')
|
||||||
|
workflow.add_conditional_edges('reviewer',
|
||||||
|
(lambda draft: "accept" if draft['review'] is None else "revise"),
|
||||||
|
{"accept": END, "revise": "reviser"})
|
||||||
|
```
|
||||||
|
|
||||||
|
By defining the conditional edges, the graph would direct to reviser if there exists review notes by the reviewer, or the cycle would end with the final draft. If you go back to the main graph we’ve built, you’ll see that this parallel work is under a node named “researcher” called by ChiefEditor agent.
|
||||||
|
|
||||||
|
Running the Research Assistant
|
||||||
|
After finalizing the agents, states and graphs, it’s time to run our research assistant! To make it easier to customize, the assistant runs with a given task.json file:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"query": "Is AI in a hype cycle?",
|
||||||
|
"max_sections": 3,
|
||||||
|
"publish_formats": {
|
||||||
|
"markdown": true,
|
||||||
|
"pdf": true,
|
||||||
|
"docx": true
|
||||||
|
},
|
||||||
|
"follow_guidelines": false,
|
||||||
|
"model": "gpt-4-turbo",
|
||||||
|
"guidelines": [
|
||||||
|
"The report MUST be written in APA format",
|
||||||
|
"Each sub section MUST include supporting sources using hyperlinks. If none exist, erase the sub section or rewrite it to be a part of the previous section",
|
||||||
|
"The report MUST be written in spanish"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
The task object is pretty self explanatory, however please notice that follow_guidelines if false would cause the graph to ignore the revision step and defined guidelines. Also, the max_sections field defines how many subheaders to research for. Having less will generate a shorter report.
|
||||||
|
|
||||||
|
Running the assistant will result in a final research report in formats such as Markdown, PDF and Docx.
|
||||||
|
|
||||||
|
To download and run the example check out the GPT Researcher x LangGraph [open source page](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents).
|
||||||
|
|
||||||
|
## What’s Next?
|
||||||
|
Going forward, there are super exciting things to think about. Human in the loop is key for optimized AI experiences. Having a human help the assistant revise and focus on just the right research plan, topics and outline, would enhance the overall quality and experience. Also generally, aiming for relying on human intervention throughout the AI flow ensures correctness, sense of control and deterministic results. Happy to see that LangGraph already supports this out of the box as seen here.
|
||||||
|
|
||||||
|
In addition, having support for research about both web and local data would be key for many types of business and personal use cases.
|
||||||
|
|
||||||
|
Lastly, more efforts can be done to improve the quality of retrieved sources and making sure the final report is built in the optimal storyline.
|
||||||
|
|
||||||
|
A step forward in LangGraph and multi-agent collaboration in a whole would be where assistants can plan and generate graphs dynamically based on given tasks. This vision would allow assistants to choose only a subset of agents for a given task and plan their strategy based on the graph fundamentals as presented in this article and open a whole new world of possibilities. Given the pace of innovation in the AI space, it won’t be long before a new disruptive version of GPT Researcher is launched. Looking forward to what the future brings!
|
||||||
|
|
||||||
|
To keep track of this project’s ongoing progress and updates please join our Discord community. And as always, if you have any feedback or further questions, please comment below!
|
||||||
{kind=link}
|
After Width: | Height: | Size: 190 KiB |
@ -0,0 +1,182 @@
|
|||||||
|
---
|
||||||
|
slug: gptr-hybrid
|
||||||
|
title: The Future of Research is Hybrid
|
||||||
|
authors: [assafe]
|
||||||
|
tags: [hybrid-research, gpt-researcher, langchain, langgraph, tavily]
|
||||||
|
image: https://miro.medium.com/v2/resize:fit:1400/1*NgVIlZVSePqrK5EkB1wu4Q.png
|
||||||
|
---
|
||||||
|

|
||||||
|
|
||||||
|
Over the past few years, we've seen an explosion of new AI tools designed to disrupt research. Some, like [ChatPDF](https://www.chatpdf.com/) and [Consensus](https://consensus.app), focus on extracting insights from documents. Others, such as [Perplexity](https://www.perplexity.ai/), excel at scouring the web for information. But here's the thing: none of these tools combine both web and local document search within a single contextual research pipeline.
|
||||||
|
|
||||||
|
This is why I'm excited to introduce the latest advancements of **[GPT Researcher](https://gptr.dev)** — now able to conduct hybrid research on any given task and documents.
|
||||||
|
|
||||||
|
Web driven research often lacks specific context, risks information overload, and may include outdated or unreliable data. On the flip side, local driven research is limited to historical data and existing knowledge, potentially creating organizational echo chambers and missing out on crucial market trends or competitor moves. Both approaches, when used in isolation, can lead to incomplete or biased insights, hampering your ability to make fully informed decisions.
|
||||||
|
|
||||||
|
Today, we're going to change the game. By the end of this guide, you'll learn how to conduct hybrid research that combines the best of both worlds — web and local — enabling you to conduct more thorough, relevant, and insightful research.
|
||||||
|
|
||||||
|
## Why Hybrid Research Works Better
|
||||||
|
|
||||||
|
By combining web and local sources, hybrid research addresses these limitations and offers several key advantages:
|
||||||
|
|
||||||
|
1. **Grounded context**: Local documents provide a foundation of verified, organization specific information. This grounds the research in established knowledge, reducing the risk of straying from core concepts or misinterpreting industry specific terminology.
|
||||||
|
|
||||||
|
*Example*: A pharmaceutical company researching a new drug development opportunity can use its internal research papers and clinical trial data as a base, then supplement this with the latest published studies and regulatory updates from the web.
|
||||||
|
|
||||||
|
2. **Enhanced accuracy**: Web sources offer up-to-date information, while local documents provide historical context. This combination allows for more accurate trend analysis and decision-making.
|
||||||
|
|
||||||
|
*Example*: A financial services firm analyzing market trends can combine their historical trading data with real-time market news and social media sentiment analysis to make more informed investment decisions.
|
||||||
|
|
||||||
|
3. **Reduced bias**: By drawing from both web and local sources, we mitigate the risk of bias that might be present in either source alone.
|
||||||
|
|
||||||
|
*Example*: A tech company evaluating its product roadmap can balance internal feature requests and usage data with external customer reviews and competitor analysis, ensuring a well-rounded perspective.
|
||||||
|
|
||||||
|
4. **Improved planning and reasoning**: LLMs can leverage the context from local documents to better plan their web research strategies and reason about the information they find online.
|
||||||
|
|
||||||
|
*Example*: An AI-powered market research tool can use a company's past campaign data to guide its web search for current marketing trends, resulting in more relevant and actionable insights.
|
||||||
|
|
||||||
|
5. **Customized insights**: Hybrid research allows for the integration of proprietary information with public data, leading to unique, organization-specific insights.
|
||||||
|
|
||||||
|
*Example*: A retail chain can combine its sales data with web-scraped competitor pricing and economic indicators to optimize its pricing strategy in different regions.
|
||||||
|
|
||||||
|
These are just a few examples for business use cases that can leverage hybrid research, but enough with the small talk — let's build!
|
||||||
|
|
||||||
|
## Building the Hybrid Research Assistant
|
||||||
|
|
||||||
|
Before we dive into the details, it's worth noting that GPT Researcher has the capability to conduct hybrid research out of the box! However, to truly appreciate how this works and to give you a deeper understanding of the process, we're going to take a look under the hood.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
GPT Researcher conducts web research based on an auto-generated plan from local documents, as seen in the architecture above. It then retrieves relevant information from both local and web data for the final research report.
|
||||||
|
|
||||||
|
We'll explore how local documents are processed using LangChain, which is a key component of GPT Researcher's document handling. Then, we'll show you how to leverage GPT Researcher to conduct hybrid research, combining the advantages of web search with your local document knowledge base.
|
||||||
|
|
||||||
|
### Processing Local Documents with Langchain
|
||||||
|
|
||||||
|
LangChain provides a variety of document loaders that allow us to process different file types. This flexibility is crucial when dealing with diverse local documents. Here's how to set it up:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from langchain_community.document_loaders import (
|
||||||
|
PyMuPDFLoader,
|
||||||
|
TextLoader,
|
||||||
|
UnstructuredCSVLoader,
|
||||||
|
UnstructuredExcelLoader,
|
||||||
|
UnstructuredMarkdownLoader,
|
||||||
|
UnstructuredPowerPointLoader,
|
||||||
|
UnstructuredWordDocumentLoader
|
||||||
|
)
|
||||||
|
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||||
|
from langchain.embeddings import OpenAIEmbeddings
|
||||||
|
from langchain.vectorstores import Chroma
|
||||||
|
|
||||||
|
def load_local_documents(file_paths):
|
||||||
|
documents = []
|
||||||
|
for file_path in file_paths:
|
||||||
|
if file_path.endswith('.pdf'):
|
||||||
|
loader = PyMuPDFLoader(file_path)
|
||||||
|
elif file_path.endswith('.txt'):
|
||||||
|
loader = TextLoader(file_path)
|
||||||
|
elif file_path.endswith('.csv'):
|
||||||
|
loader = UnstructuredCSVLoader(file_path)
|
||||||
|
elif file_path.endswith('.xlsx'):
|
||||||
|
loader = UnstructuredExcelLoader(file_path)
|
||||||
|
elif file_path.endswith('.md'):
|
||||||
|
loader = UnstructuredMarkdownLoader(file_path)
|
||||||
|
elif file_path.endswith('.pptx'):
|
||||||
|
loader = UnstructuredPowerPointLoader(file_path)
|
||||||
|
elif file_path.endswith('.docx'):
|
||||||
|
loader = UnstructuredWordDocumentLoader(file_path)
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unsupported file type: {file_path}")
|
||||||
|
|
||||||
|
documents.extend(loader.load())
|
||||||
|
|
||||||
|
return documents
|
||||||
|
|
||||||
|
# Use the function to load your local documents
|
||||||
|
local_docs = load_local_documents(['company_report.pdf', 'meeting_notes.docx', 'data.csv'])
|
||||||
|
|
||||||
|
# Split the documents into smaller chunks for more efficient processing
|
||||||
|
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
|
||||||
|
splits = text_splitter.split_documents(local_docs)
|
||||||
|
|
||||||
|
# Create embeddings and store them in a vector database for quick retrieval
|
||||||
|
embeddings = OpenAIEmbeddings()
|
||||||
|
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
|
||||||
|
|
||||||
|
# Example of how to perform a similarity search
|
||||||
|
query = "What were the key points from our last strategy meeting?"
|
||||||
|
relevant_docs = vectorstore.similarity_search(query, k=3)
|
||||||
|
|
||||||
|
for doc in relevant_docs:
|
||||||
|
print(doc.page_content)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Conducting Web Research with GPT Researcher
|
||||||
|
|
||||||
|
Now that we've learned how to work with local documents, let's take a quick look at how GPT Researcher works under the hood:
|
||||||
|
|
||||||
|
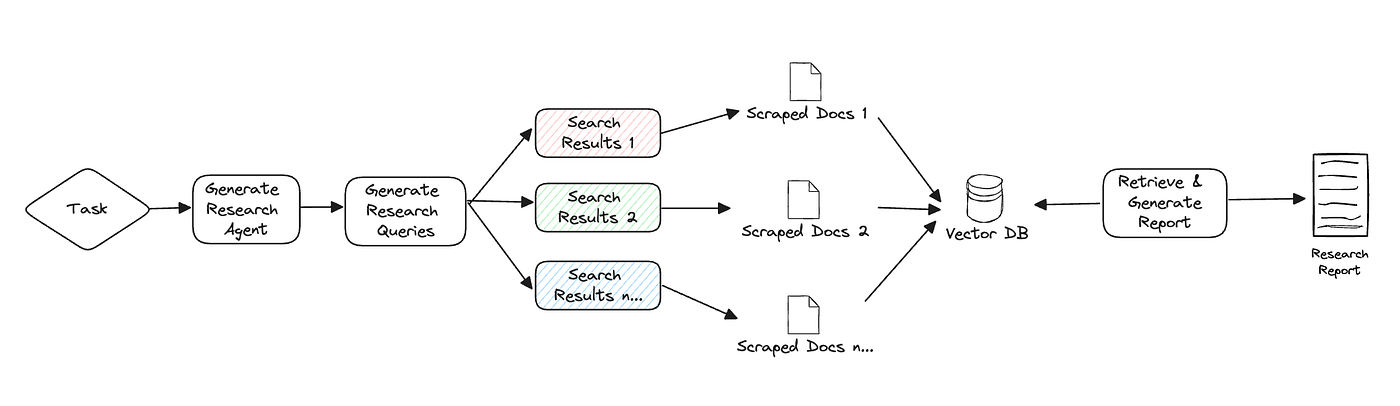
|
||||||
|
|
||||||
|
As seen above, GPT Researcher creates a research plan based on the given task by generating potential research queries that can collectively provide an objective and broad overview of the topic. Once these queries are generated, GPT Researcher uses a search engine like Tavily to find relevant results. Each scraped result is then saved in a vector database. Finally, the top k chunks most related to the research task are retrieved to generate a final research report.
|
||||||
|
|
||||||
|
GPT Researcher supports hybrid research, which involves an additional step of chunking local documents (implemented using Langchain) before retrieving the most related information. After numerous evaluations conducted by the community, we've found that hybrid research improved the correctness of final results by over 40%!
|
||||||
|
|
||||||
|
### Running the Hybrid Research with GPT Researcher
|
||||||
|
|
||||||
|
Now that you have a better understanding of how hybrid research works, let's demonstrate how easy this can be achieved with GPT Researcher.
|
||||||
|
|
||||||
|
#### Step 1: Install GPT Researcher with PIP
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Step 2: Setting up the environment
|
||||||
|
|
||||||
|
We will run GPT Researcher with OpenAI as the LLM vendor and Tavily as the search engine. You'll need to obtain API keys for both before moving forward. Then, export the environment variables in your CLI as follows:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY={your-openai-key}
|
||||||
|
export TAVILY_API_KEY={your-tavily-key}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Step 3: Initialize GPT Researcher with hybrid research configuration
|
||||||
|
|
||||||
|
GPT Researcher can be easily initialized with params that signal it to run a hybrid research. You can conduct many forms of research, head to the documentation page to learn more.
|
||||||
|
|
||||||
|
To get GPT Researcher to run a hybrid research, you need to include all relevant files in my-docs directory (create it if it doesn't exist), and set the instance report_source to "hybrid" as seen below. Once the report source is set to hybrid, GPT Researcher will look for existing documents in the my-docs directory and include them in the research. If no documents exist, it will ignore it.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_research_report(query: str, report_type: str, report_source: str) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, report_source=report_source)
|
||||||
|
research = await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "How does our product roadmap compare to emerging market trends in our industry?"
|
||||||
|
report_source = "hybrid"
|
||||||
|
|
||||||
|
report = asyncio.run(get_research_report(query=query, report_type="research_report", report_source=report_source))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
As seen above, we can run the research on the following example:
|
||||||
|
|
||||||
|
- Research task: "How does our product roadmap compare to emerging market trends in our industry?"
|
||||||
|
- Web: Current market trends, competitor announcements, and industry forecasts
|
||||||
|
- Local: Internal product roadmap documents and feature prioritization lists
|
||||||
|
|
||||||
|
After various community evaluations we've found that the results of this research improve quality and correctness of research by over 40% and remove hallucinations by 50%. Moreover as stated above, local information helps the LLM improve planning reasoning allowing it to make better decisions and researching more relevant web sources.
|
||||||
|
|
||||||
|
But wait, there's more! GPT Researcher also includes a sleek front-end app using NextJS and Tailwind. To learn how to get it running check out the documentation page. You can easily use drag and drop for documents to run hybrid research.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
Hybrid research represents a significant advancement in data gathering and decision making. By leveraging tools like [GPT Researcher](https://gptr.dev), teams can now conduct more comprehensive, context-aware, and actionable research. This approach addresses the limitations of using web or local sources in isolation, offering benefits such as grounded context, enhanced accuracy, reduced bias, improved planning and reasoning, and customized insights.
|
||||||
|
|
||||||
|
The automation of hybrid research can enable teams to make faster, more data-driven decisions, ultimately enhancing productivity and offering a competitive advantage in analyzing an expanding pool of unstructured and dynamic information.
|
||||||
@ -0,0 +1,216 @@
|
|||||||
|
# Introducing Deep Research: The Open Source Alternative
|
||||||
|
|
||||||
|
## The Dawn of Deep Research in AI
|
||||||
|
|
||||||
|
The AI research landscape is witnessing a revolutionary shift with the emergence of "Deep Research" capabilities. But what exactly is deep research, and why should you care?
|
||||||
|
|
||||||
|
Deep research represents the next evolution in AI-powered information retrieval - going far beyond simple search to deliver comprehensive, multi-layered analysis of complex topics. Unlike traditional search engines that return a list of links, or even first-generation AI assistants that provide surface-level summaries, deep research tools deploy sophisticated algorithms to explore topics with unprecedented depth and breadth, mimicking the way human researchers would tackle complex subjects.
|
||||||
|
|
||||||
|
The key features that define true deep research capabilities include iterative analysis that refines queries and results dynamically ([InfoQ, 2025](https://www.infoq.com/news/2025/02/perplexity-deep-research/)), multimodal processing that integrates diverse data formats ([Observer, 2025](https://observer.com/2025/01/openai-google-gemini-agi/)), real-time data retrieval for up-to-date insights ([WinBuzzer, 2025](https://winbuzzer.com/2025/02/15/perplexity-deep-research-challenges-openai-and-googles-ai-powered-information-retrieval-xcxwbn/)), and structured outputs with proper citations for academic and technical applications ([Helicone, 2025](https://www.helicone.ai/blog/openai-deep-research)).
|
||||||
|
|
||||||
|
In recent months, we've seen major players launch their own deep research solutions, each with its unique approach and positioning in the market:
|
||||||
|
|
||||||
|
- **Perplexity AI** focuses on speed, delivering research results in under three minutes with real-time data retrieval ([Analytics Vidhya, 2025](https://www.analyticsvidhya.com/blog/2025/02/perplexity-deep-research/)). Their cost-effective model (starting at free tier) makes advanced research accessible to a broader audience, though some analysts note potential accuracy trade-offs in favor of speed ([Medium, 2025](https://medium.com/towards-agi/perplexity-ai-deep-research-vs-openai-deep-research-an-in-depth-comparison-6784c814fc4a)).
|
||||||
|
|
||||||
|
- **OpenAI's Deep Research** (built on the O3 model) prioritizes depth and precision, excelling in technical and academic applications with advanced reasoning capabilities ([Helicone, 2025](https://www.helicone.ai/blog/openai-deep-research)). Their structured outputs include detailed citations, ensuring reliability and verifiability. However, at $200/month ([Opentools, 2025](https://opentools.ai/news/openai-unveils-groundbreaking-deep-research-chatgpt-for-pro-users)), it represents a significant investment, and comprehensive reports can take 5-30 minutes to generate ([ClickItTech, 2025](https://www.clickittech.com/ai/perplexity-deep-research-vs-openai-deep-research/)).
|
||||||
|
|
||||||
|
- **Google's Gemini 2.0** emphasizes multimodal integration across text, images, audio, and video, with particular strength in enterprise applications ([Adyog, 2024](https://blog.adyog.com/2024/12/31/the-ai-titans-face-off-openais-o3-vs-googles-gemini-2-0/)). At $20/month, it offers a more affordable alternative to OpenAI's solution, though some users note limitations in customization flexibility ([Helicone, 2025](https://www.helicone.ai/blog/openai-deep-research)).
|
||||||
|
|
||||||
|
What makes deep research truly exciting is its potential to democratize advanced knowledge synthesis ([Medium, 2025](https://medium.com/@greeshmamshajan/the-evolution-of-ai-powered-research-perplexitys-disruption-and-the-battle-for-cognitive-87af682cc8e6)), dramatically enhance productivity by automating time-intensive research tasks ([The Mobile Indian, 2025](https://www.themobileindian.com/news/perplexity-deep-research-vs-openai-deep-research-vs-gemini-1-5-pro-deep-research-ai-fight)), and open new avenues for interdisciplinary research through advanced reasoning capabilities ([Observer, 2025](https://observer.com/2025/01/openai-google-gemini-agi/)).
|
||||||
|
|
||||||
|
However, a key limitation in the current market is accessibility - the most powerful deep research tools remain locked behind expensive paywalls or closed systems, putting them out of reach for many researchers, students, and smaller organizations who could benefit most from these capabilities.
|
||||||
|
|
||||||
|
## Introducing GPT Researcher Deep Research ✨
|
||||||
|
|
||||||
|
We're thrilled to announce our answer to this trend: **GPT Researcher Deep Research** - an advanced open-source recursive research system that explores topics with depth and breadth, all while maintaining cost-effectiveness and transparency.
|
||||||
|
|
||||||
|
[GPT Researcher](https://github.com/assafelovic/gpt-researcher) Deep Research not only matches the capabilities of the industry giants but exceeds them in several key metrics:
|
||||||
|
|
||||||
|
- **Cost-effective**: Each deep research operation costs approximately $0.40 (using `o3-mini` on `"high"` reasoning effort)
|
||||||
|
- **Time-efficient**: Complete research in around 5 minutes
|
||||||
|
- **Fully customizable**: Adjust parameters to match your specific research needs
|
||||||
|
- **Transparent**: Full visibility into the research process and methodology
|
||||||
|
- **Open source**: Free to use, modify, and integrate into your workflows
|
||||||
|
|
||||||
|
## How It Works: The Recursive Research Tree
|
||||||
|
|
||||||
|
What makes GPT Researcher's deep research so powerful is its tree-like exploration pattern that combines breadth and depth in an intelligent, recursive approach:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1. **Breadth Exploration**: At each level, it generates multiple search queries to explore different aspects of your topic
|
||||||
|
2. **Depth Diving**: For each branch, it recursively goes deeper, following promising leads and uncovering hidden connections
|
||||||
|
3. **Concurrent Processing**: Utilizing async/await patterns to run multiple research paths simultaneously
|
||||||
|
4. **Context Management**: Automatically aggregates and synthesizes findings across all branches
|
||||||
|
5. **Real-time Tracking**: Provides updates on research progress across both breadth and depth dimensions
|
||||||
|
|
||||||
|
Imagine deploying a team of AI researchers, each following their own research path while collaborating to build a comprehensive understanding of your topic. That's the power of GPT Researcher's deep research approach.
|
||||||
|
|
||||||
|
## Getting Started in Minutes
|
||||||
|
|
||||||
|
Integrating deep research into your projects is remarkably straightforward:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def main():
|
||||||
|
# Initialize researcher with deep research type
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query="What are the latest developments in quantum computing?",
|
||||||
|
report_type="deep", # This triggers deep research mode
|
||||||
|
)
|
||||||
|
|
||||||
|
# Run research
|
||||||
|
research_data = await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Generate report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
print(report)
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
asyncio.run(main())
|
||||||
|
```
|
||||||
|
|
||||||
|
## Under the Hood: How Deep Research Works
|
||||||
|
|
||||||
|
Looking at the codebase reveals the sophisticated system that powers GPT Researcher's deep research capabilities:
|
||||||
|
|
||||||
|
### 1. Query Generation and Planning
|
||||||
|
|
||||||
|
The system begins by generating a set of diverse search queries based on your initial question:
|
||||||
|
|
||||||
|
```python
|
||||||
|
async def generate_search_queries(self, query: str, num_queries: int = 3) -> List[Dict[str, str]]:
|
||||||
|
"""Generate SERP queries for research"""
|
||||||
|
messages = [
|
||||||
|
{"role": "system", "content": "You are an expert researcher generating search queries."},
|
||||||
|
{"role": "user",
|
||||||
|
"content": f"Given the following prompt, generate {num_queries} unique search queries to research the topic thoroughly. For each query, provide a research goal. Format as 'Query: <query>' followed by 'Goal: <goal>' for each pair: {query}"}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
This process creates targeted queries, each with a specific research goal. For example, a query about quantum computing might generate:
|
||||||
|
- "Latest quantum computing breakthroughs 2024-2025"
|
||||||
|
- "Quantum computing practical applications in finance"
|
||||||
|
- "Quantum error correction advancements"
|
||||||
|
|
||||||
|
### 2. Concurrent Research Execution
|
||||||
|
|
||||||
|
The system then executes these queries concurrently, with intelligent resource management:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Process queries with concurrency limit
|
||||||
|
semaphore = asyncio.Semaphore(self.concurrency_limit)
|
||||||
|
|
||||||
|
async def process_query(serp_query: Dict[str, str]) -> Optional[Dict[str, Any]]:
|
||||||
|
async with semaphore:
|
||||||
|
# Research execution logic
|
||||||
|
```
|
||||||
|
|
||||||
|
This approach maximizes efficiency while ensuring system stability - like having multiple researchers working in parallel.
|
||||||
|
|
||||||
|
### 3. Recursive Exploration
|
||||||
|
|
||||||
|
The magic happens with recursive exploration:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Continue deeper if needed
|
||||||
|
if depth > 1:
|
||||||
|
new_breadth = max(2, breadth // 2)
|
||||||
|
new_depth = depth - 1
|
||||||
|
progress.current_depth += 1
|
||||||
|
|
||||||
|
# Create next query from research goal and follow-up questions
|
||||||
|
next_query = f"""
|
||||||
|
Previous research goal: {result['researchGoal']}
|
||||||
|
Follow-up questions: {' '.join(result['followUpQuestions'])}
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Recursive research
|
||||||
|
deeper_results = await self.deep_research(
|
||||||
|
query=next_query,
|
||||||
|
breadth=new_breadth,
|
||||||
|
depth=new_depth,
|
||||||
|
# Additional parameters
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
This creates a tree-like exploration pattern that follows promising leads deeper while maintaining breadth of coverage.
|
||||||
|
|
||||||
|
### 4. Context Management and Synthesis
|
||||||
|
|
||||||
|
Managing the vast amount of gathered information requires sophisticated tracking:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Trim context to stay within word limits
|
||||||
|
trimmed_context = trim_context_to_word_limit(all_context)
|
||||||
|
logger.info(f"Trimmed context from {len(all_context)} items to {len(trimmed_context)} items to stay within word limit")
|
||||||
|
```
|
||||||
|
|
||||||
|
This ensures the most relevant information is retained while respecting model context limitations.
|
||||||
|
|
||||||
|
## Customizing Your Research Experience
|
||||||
|
|
||||||
|
One of the key advantages of GPT Researcher's open-source approach is full customizability. You can tailor the research process to your specific needs through several configuration options:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
deep_research_breadth: 4 # Number of parallel research paths
|
||||||
|
deep_research_depth: 2 # How many levels deep to explore
|
||||||
|
deep_research_concurrency: 4 # Maximum concurrent operations
|
||||||
|
total_words: 2500 # Word count for final report
|
||||||
|
```
|
||||||
|
|
||||||
|
Apply these configurations through environment variables, a config file, or directly in code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query="your query",
|
||||||
|
report_type="deep",
|
||||||
|
config_path="path/to/config.yaml"
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Real-time Progress Tracking
|
||||||
|
|
||||||
|
For applications requiring visibility into the research process, GPT Researcher provides detailed progress tracking:
|
||||||
|
|
||||||
|
```python
|
||||||
|
class ResearchProgress:
|
||||||
|
current_depth: int # Current depth level
|
||||||
|
total_depth: int # Maximum depth to explore
|
||||||
|
current_breadth: int # Current number of parallel paths
|
||||||
|
total_breadth: int # Maximum breadth at each level
|
||||||
|
current_query: str # Currently processing query
|
||||||
|
completed_queries: int # Number of completed queries
|
||||||
|
total_queries: int # Total queries to process
|
||||||
|
```
|
||||||
|
|
||||||
|
This allows you to build interfaces that show research progress in real-time - perfect for applications where users want visibility into the process.
|
||||||
|
|
||||||
|
## Why This Matters: The Impact of Deep Research
|
||||||
|
|
||||||
|
The democratization of deep research capabilities through open-source tools like GPT Researcher represents a paradigm shift in how we process and analyze information. Benefits include:
|
||||||
|
|
||||||
|
1. **Deeper insights**: Uncover connections and patterns that surface-level research would miss
|
||||||
|
2. **Time savings**: Automate hours or days of manual research into minutes
|
||||||
|
3. **Reduced costs**: Enterprise-grade research capabilities at a fraction of the cost
|
||||||
|
4. **Accessibility**: Bringing advanced research tools to individuals and small organizations
|
||||||
|
5. **Transparency**: Full visibility into the research methodology and sources
|
||||||
|
|
||||||
|
## Getting Started Today
|
||||||
|
|
||||||
|
Ready to experience the power of deep research in your projects? Here's how to get started:
|
||||||
|
|
||||||
|
1. **Installation**: `pip install gpt-researcher`
|
||||||
|
2. **API Key**: Set up your API key for the LLM provider and search engine of your choice
|
||||||
|
3. **Configuration**: Customize parameters based on your research needs
|
||||||
|
4. **Implementation**: Use the example code to integrate into your application
|
||||||
|
|
||||||
|
More detailed instructions and examples can be found in the [GPT Researcher documentation](https://docs.gptr.dev/docs/gpt-researcher/gptr/deep_research)
|
||||||
|
|
||||||
|
Whether you're a developer building the next generation of research tools, an academic seeking deeper insights, or a business professional needing comprehensive analysis, GPT Researcher's deep research capabilities offer an accessible, powerful solution that rivals - and in many ways exceeds - the offerings from major AI companies.
|
||||||
|
|
||||||
|
The future of AI-powered research is here, and it's open source. 🎉
|
||||||
|
|
||||||
|
Happy researching!
|
||||||
@ -0,0 +1,91 @@
|
|||||||
|
---
|
||||||
|
slug: stepping-into-the-story
|
||||||
|
title: Stepping Into the Story of GPT Researcher
|
||||||
|
authors: [elishakay]
|
||||||
|
tags: [ai, gpt-researcher, prompts, dreams, community]
|
||||||
|
image: https://github.com/user-attachments/assets/f6e8a6b5-12f8-4faa-ae99-6a2fbaf23cc1
|
||||||
|
---
|
||||||
|

|
||||||
|
|
||||||
|
## The Barnes & Noble Dream
|
||||||
|
|
||||||
|
As a teenager, I remember stepping into Barnes & Noble, the scent of fresh pages filling the air, my fingers tracing the spines of books that had shaped minds and captured hearts. I'd whisper to myself: One day, my name will be here.
|
||||||
|
|
||||||
|
To me, books weren't just stories—they were reflections of the human experience, ways for people to see themselves more clearly. Shakespeare once said, “The purpose of art is to hold a mirror up to nature.” That idea stuck with me. Art, writing, and storytelling weren't just about entertainment; they were about understanding ourselves in new ways.
|
||||||
|
|
||||||
|
But the world changed. The bookstores faded, attention shifted, and the novel—once the pinnacle of deep thought and reflection—gave way to new forms of engagement. The long, immersive experience of reading was replaced with something more dynamic, more interactive.
|
||||||
|
|
||||||
|
## The Journey into Coding: A Simba Moment
|
||||||
|
|
||||||
|
About 9 years ago, [much like Simba in The Lion King](https://open.spotify.com/track/3BUT32qmBXmlqp3EJkgRfp?si=0935ef6eedf247ed), I embarked on a new journey filled with doubt and uncertainty. Leaving my known world of writing, I stepped into the unknown realm of coding. It was a foreign language at first—endless lines of syntax, debugging errors that made no sense, and moments of frustration where I felt like an imposter in a world of developers.
|
||||||
|
|
||||||
|
The journey was tough—I struggled to find my place, faced canceled contracts, and got my butt handed to me more times than I could count. Every rejection, every missed opportunity made me question if I had taken the wrong path. Maybe I wasn't meant to build—maybe I was meant to stay in the world of stories.
|
||||||
|
|
||||||
|
Even when I finally landed a job at Fiverr, working with JavaScript, MySQL, HTML, and CSS, I still felt like I had abandoned my identity as a writer.
|
||||||
|
|
||||||
|
## Discovering GPT Researcher
|
||||||
|
|
||||||
|
One night, about a year ago, deep into a rabbit hole of AI research, I stumbled upon GPT Researcher. The concept struck me instantly—AI wasn't just a tool; it was a means of expanding human knowledge, refining our questions, and reshaping how we approach research itself.
|
||||||
|
|
||||||
|
I reached out to Assaf, not expecting much. But instead of a polite acknowledgment, he welcomed me in. That moment—seeing my first commit merged—felt like an echo of my old dream. Only this time, I wasn't just writing stories. I was building something that helped others uncover their own.
|
||||||
|
|
||||||
|
## The Wicked Witch of the Researcher's Mirror
|
||||||
|
|
||||||
|
Around that time, I found myself repeatedly asking GPT Researcher the same question:
|
||||||
|
|
||||||
|
"Who is Elisha Kramer?"
|
||||||
|
|
||||||
|
At first, it was like the Magic Mirror in Snow White, responding with something generic like, "Elisha Kramer is a software engineer with experience in web development." It pulled information from my LinkedIn, GitHub, and Udemy profiles, painting a picture of who I was professionally. But then, things got weird.
|
||||||
|
|
||||||
|
I made more commits to GPT Researcher. More contributions. And as I coded, I asked a different question.
|
||||||
|
|
||||||
|
"Who is ElishaKay on Github?"
|
||||||
|
|
||||||
|
As time went on, the answer changed since the Researcher was pulling new sources fresh off web search results.
|
||||||
|
|
||||||
|
"ElishaKay is an active open source contributor with multiple repositories and over 500 commits in the past year."
|
||||||
|
|
||||||
|
Holy Shnikes! It was learning. Another commit. Another feature. Another line of documentation. Time to get more specific.
|
||||||
|
|
||||||
|
"Who is ElishaKay of gpt-researcher?"
|
||||||
|
|
||||||
|
"ElishaKay is a core contributor of GPT Researcher, improving research workflows and enhancing AI retrieval through significant code and documentation contributions."
|
||||||
|
|
||||||
|
Now we were talking. But I wasn't done. Like the Wicked Witch, I kept coming back. More commits. More improvements. More features.
|
||||||
|
|
||||||
|
Until finally, I asked:
|
||||||
|
|
||||||
|
"Tell me about gpt-researcher and tips to improve it"
|
||||||
|
|
||||||
|
And GPT Researcher looked back at me and said:
|
||||||
|
|
||||||
|
"GPTR is a thriving open-source community. The best path forward is to continue investing in that community - through code contributions, documentation improvements, and helping new contributors get started. The project's strength lies in its collaborative nature."
|
||||||
|
|
||||||
|
And that's when I knew—I wasn't just using GPT Researcher. I was becoming part of its story.
|
||||||
|
|
||||||
|
## AI as a mirror of ourselves
|
||||||
|
|
||||||
|
This evolving feedback helped me frame my own self-narrative. GPT Researcher wasn't just reflecting what was already known—it was pulling in context from both my work and the broader internet.
|
||||||
|
|
||||||
|
It was reflecting back my own journey, refining it with each step, blurring the illusion of a fixed identity, and embracing an evolving one.
|
||||||
|
|
||||||
|
Every query, every commit, every improvement shaped the tool—and in turn, it shaped me.
|
||||||
|
|
||||||
|
## Building as a Community
|
||||||
|
|
||||||
|
GPT Researcher isn't just a tool. It's a reflection of the open-source spirit, a living, evolving ecosystem where knowledge isn't static but constantly refined. It isn't just answering questions; it's engaging in a dialogue, shaping and reshaping narratives based on the latest contributions, research, and discoveries.
|
||||||
|
It isn't just about me anymore. It's about us.
|
||||||
|
A network of 138 contributors. An open-source project watched by 20,000 stars. A collective movement pushing the boundaries of AI-driven research.
|
||||||
|
|
||||||
|
Every researcher, every developer, every curious mind who refines their questions, contributes a feature, or engages with the tool is part of something bigger. AI isn't just some black box spitting out answers—it's a tool that helps us refine our own thinking, challenge assumptions, and expand our understanding.
|
||||||
|
It's an iterative process, just like life itself.
|
||||||
|
The more context we provide, the better the insights we get. The more we engage, the more it reflects back not just who we were but who we are becoming.
|
||||||
|
|
||||||
|
## A Story Still Being Written
|
||||||
|
|
||||||
|
So while I once dreamed of seeing my name on a book spine in Barnes & Noble, I now see something even greater.
|
||||||
|
My words aren't bound to a single book—they live within every line of code, every contribution, every researcher refining their questions.
|
||||||
|
We are not just users. We are builders.
|
||||||
|
And this isn't just my story.
|
||||||
|
It's our story.
|
||||||
|
And it's still being written.
|
||||||
11
systems/research/gpt-researcher/docs/blog/authors.yml
Normal file
@ -0,0 +1,11 @@
|
|||||||
|
assafe:
|
||||||
|
name: Assaf Elovic
|
||||||
|
title: Creator @ GPT Researcher and Tavily
|
||||||
|
url: https://github.com/assafelovic
|
||||||
|
image_url: https://lh3.googleusercontent.com/a/ACg8ocJtrLku69VG_2Y0sJa5mt66gIGNaEBX5r_mgE6CRPEb7A=s96-c
|
||||||
|
|
||||||
|
elishakay:
|
||||||
|
name: Elisha Kramer
|
||||||
|
title: Core Contributor @ GPT Researcher
|
||||||
|
url: https://github.com/ElishaKay
|
||||||
|
image_url: https://avatars.githubusercontent.com/u/16700452
|
||||||
@ -0,0 +1,6 @@
|
|||||||
|
FROM node:18.17.0-alpine
|
||||||
|
WORKDIR /app
|
||||||
|
COPY ./package.json ./
|
||||||
|
RUN npm install --legacy-peer-deps
|
||||||
|
COPY . .
|
||||||
|
CMD ["node", "index.js"]
|
||||||
@ -0,0 +1,7 @@
|
|||||||
|
FROM node:18.17.0-alpine
|
||||||
|
WORKDIR /app
|
||||||
|
COPY ./package.json ./
|
||||||
|
RUN npm install --legacy-peer-deps
|
||||||
|
RUN npm install -g nodemon
|
||||||
|
COPY . .
|
||||||
|
CMD ["nodemon", "index.js"]
|
||||||
@ -0,0 +1,10 @@
|
|||||||
|
const { SlashCommandBuilder } = require('discord.js');
|
||||||
|
|
||||||
|
module.exports = {
|
||||||
|
data: new SlashCommandBuilder()
|
||||||
|
.setName('ask')
|
||||||
|
.setDescription('Ask a question to the bot'),
|
||||||
|
async execute(interaction) {
|
||||||
|
await interaction.reply('Please provide your question.');
|
||||||
|
}
|
||||||
|
};
|
||||||
@ -0,0 +1,32 @@
|
|||||||
|
const { Client, GatewayIntentBits, REST, Routes } = require('discord.js');
|
||||||
|
require('dotenv').config();
|
||||||
|
|
||||||
|
// Create a new REST client and set your bot token
|
||||||
|
const rest = new REST({ version: '10' }).setToken(process.env.DISCORD_BOT_TOKEN);
|
||||||
|
|
||||||
|
// Define commands
|
||||||
|
const commands = [
|
||||||
|
{
|
||||||
|
name: 'ping',
|
||||||
|
description: 'Replies with Pong!',
|
||||||
|
},
|
||||||
|
{
|
||||||
|
name: 'ask',
|
||||||
|
description: 'Ask a question to the bot',
|
||||||
|
},
|
||||||
|
];
|
||||||
|
|
||||||
|
// Deploy commands to Discord
|
||||||
|
(async () => {
|
||||||
|
try {
|
||||||
|
console.log('Started refreshing application (/) commands.');
|
||||||
|
|
||||||
|
await rest.put(Routes.applicationCommands(process.env.DISCORD_CLIENT_ID), {
|
||||||
|
body: commands,
|
||||||
|
});
|
||||||
|
|
||||||
|
console.log('Successfully reloaded application (/) commands.');
|
||||||
|
} catch (error) {
|
||||||
|
console.error(error);
|
||||||
|
}
|
||||||
|
})();
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
// gptr-webhook.js
|
||||||
|
const WebSocket = require('ws');
|
||||||
|
|
||||||
|
let socket = null;
|
||||||
|
const responseCallbacks = new Map(); // Using Map for multiple callbacks
|
||||||
|
|
||||||
|
async function initializeWebSocket() {
|
||||||
|
if (!socket) {
|
||||||
|
const host = 'gpt-researcher:8000';
|
||||||
|
const ws_uri = `ws://${host}/ws`;
|
||||||
|
|
||||||
|
socket = new WebSocket(ws_uri);
|
||||||
|
|
||||||
|
socket.onopen = () => {
|
||||||
|
console.log('WebSocket connection established');
|
||||||
|
};
|
||||||
|
|
||||||
|
socket.onmessage = (event) => {
|
||||||
|
const data = JSON.parse(event.data);
|
||||||
|
console.log('WebSocket data received:', data);
|
||||||
|
|
||||||
|
// Get the callback for this request
|
||||||
|
const callback = responseCallbacks.get('current');
|
||||||
|
|
||||||
|
if (data.type === 'report') {
|
||||||
|
// Send progress updates
|
||||||
|
if (callback && callback.onProgress) {
|
||||||
|
callback.onProgress(data.output);
|
||||||
|
}
|
||||||
|
} else if (data.content === 'dev_team_result') {
|
||||||
|
// Send final result
|
||||||
|
if (callback && callback.onComplete) {
|
||||||
|
callback.onComplete(data.output);
|
||||||
|
responseCallbacks.delete('current'); // Clean up after completion
|
||||||
|
}
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
socket.onclose = () => {
|
||||||
|
console.log('WebSocket connection closed');
|
||||||
|
socket = null;
|
||||||
|
};
|
||||||
|
|
||||||
|
socket.onerror = (error) => {
|
||||||
|
console.error('WebSocket error:', error);
|
||||||
|
};
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
async function sendWebhookMessage({query, moreContext}) {
|
||||||
|
return new Promise((resolve, reject) => {
|
||||||
|
if (!socket || socket.readyState !== WebSocket.OPEN) {
|
||||||
|
initializeWebSocket();
|
||||||
|
}
|
||||||
|
|
||||||
|
const data = {
|
||||||
|
task: `${query}. Additional context: ${moreContext}`,
|
||||||
|
report_type: 'research_report',
|
||||||
|
report_source: 'web',
|
||||||
|
tone: 'Objective',
|
||||||
|
headers: {},
|
||||||
|
repo_name: typeof repoName === 'undefined' || repoName === '' ? 'assafelovic/gpt-researcher' : repoName,
|
||||||
|
branch_name: typeof branchName === 'undefined' || branchName === '' ? 'master' : branchName
|
||||||
|
};
|
||||||
|
|
||||||
|
const payload = "start " + JSON.stringify(data);
|
||||||
|
|
||||||
|
// Store both progress and completion callbacks
|
||||||
|
responseCallbacks.set('current', {
|
||||||
|
onProgress: (progressData) => {
|
||||||
|
resolve({ type: 'progress', data: progressData });
|
||||||
|
},
|
||||||
|
onComplete: (finalData) => {
|
||||||
|
resolve({ type: 'complete', data: finalData });
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
if (socket.readyState === WebSocket.OPEN) {
|
||||||
|
socket.send(payload);
|
||||||
|
console.log('Message sent:', payload);
|
||||||
|
} else {
|
||||||
|
socket.onopen = () => {
|
||||||
|
socket.send(payload);
|
||||||
|
console.log('Message sent after connection:', payload);
|
||||||
|
};
|
||||||
|
}
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
module.exports = {
|
||||||
|
sendWebhookMessage
|
||||||
|
};
|
||||||
170
systems/research/gpt-researcher/docs/discord-bot/index.js
Normal file
@ -0,0 +1,170 @@
|
|||||||
|
require('dotenv').config();
|
||||||
|
const { Client, GatewayIntentBits, ActionRowBuilder, Events, ModalBuilder, TextInputBuilder, TextInputStyle, ChannelType } = require('discord.js');
|
||||||
|
const keepAlive = require('./server');
|
||||||
|
const { sendWebhookMessage } = require('./gptr-webhook');
|
||||||
|
const { jsonrepair } = require('jsonrepair');
|
||||||
|
const { EmbedBuilder } = require('discord.js');
|
||||||
|
|
||||||
|
const client = new Client({
|
||||||
|
intents: [
|
||||||
|
GatewayIntentBits.Guilds,
|
||||||
|
GatewayIntentBits.GuildMessages,
|
||||||
|
GatewayIntentBits.MessageContent,
|
||||||
|
GatewayIntentBits.DirectMessages
|
||||||
|
],
|
||||||
|
});
|
||||||
|
|
||||||
|
function splitMessage(message, chunkSize = 1500) {
|
||||||
|
const chunks = [];
|
||||||
|
for (let i = 0; i < message.length; i += chunkSize) {
|
||||||
|
chunks.push(message.slice(i, i + chunkSize));
|
||||||
|
}
|
||||||
|
return chunks;
|
||||||
|
}
|
||||||
|
|
||||||
|
client.on('ready', () => {
|
||||||
|
console.log(`Logged in as ${client.user.tag}!`);
|
||||||
|
});
|
||||||
|
|
||||||
|
// Cooldown object to store the last message time for each channel
|
||||||
|
const cooldowns = {};
|
||||||
|
|
||||||
|
client.on('messageCreate', async message => {
|
||||||
|
if (message.author.bot) return;
|
||||||
|
// only share the /ask guide when a new message is posted in the help forum - limit to every 30 minutes per post
|
||||||
|
console.log(`Channel Data: ${message.channel.id}`);
|
||||||
|
console.log(`Message Channel Data: ${console.log(JSON.stringify(message.channel, null, 2))}`);
|
||||||
|
|
||||||
|
const channelId = message.channel.id;
|
||||||
|
const channelParentId = message.channel.parentId;
|
||||||
|
//return if its not posted in the help forum
|
||||||
|
if(channelParentId != '1129339320562626580') return
|
||||||
|
|
||||||
|
const now = Date.now();
|
||||||
|
const cooldownAmount = 30 * 60 * 1000; // 30 minutes in milliseconds
|
||||||
|
|
||||||
|
if (!cooldowns[channelId] || (now - cooldowns[channelId]) > cooldownAmount) {
|
||||||
|
// await message.reply('please use the /ask command to launch a report by typing `/ask` into the chatbox & hitting ENTER.');
|
||||||
|
|
||||||
|
const exampleEmbed = new EmbedBuilder()
|
||||||
|
.setTitle('please use the /ask command to launch a report by typing `/ask` into the chatbox & hitting ENTER.')
|
||||||
|
.setImage('https://media.discordapp.net/attachments/1127851779573420053/1285577932353568902/ask.webp?ex=66eb6fff&is=66ea1e7f&hm=32bc8335ed4c09c15a8541c058bbd513cf2ce757221a116d9c248c39a12d75df&=&format=webp&width=1740&height=704');
|
||||||
|
|
||||||
|
message.channel.send({ embeds: [exampleEmbed] });
|
||||||
|
cooldowns[channelId] = now;
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
|
||||||
|
client.on(Events.InteractionCreate, async interaction => {
|
||||||
|
if (interaction.isChatInputCommand()) {
|
||||||
|
if (interaction.commandName === 'ask') {
|
||||||
|
const modal = new ModalBuilder()
|
||||||
|
.setCustomId('myModal')
|
||||||
|
.setTitle('Ask the AI Researcher');
|
||||||
|
|
||||||
|
const queryInput = new TextInputBuilder()
|
||||||
|
.setCustomId('queryInput')
|
||||||
|
.setLabel('Your question')
|
||||||
|
.setStyle(TextInputStyle.Paragraph)
|
||||||
|
.setPlaceholder('What are you exploring today / what tickles your mind?');
|
||||||
|
|
||||||
|
const moreContextInput = new TextInputBuilder()
|
||||||
|
.setCustomId('moreContextInput')
|
||||||
|
.setLabel('Additional context (optional)')
|
||||||
|
.setStyle(TextInputStyle.Paragraph)
|
||||||
|
.setPlaceholder('Any additional context or details that would help us understand your question better?')
|
||||||
|
.setRequired(false);
|
||||||
|
|
||||||
|
const firstActionRow = new ActionRowBuilder().addComponents(queryInput);
|
||||||
|
const secondActionRow = new ActionRowBuilder().addComponents(moreContextInput);
|
||||||
|
|
||||||
|
modal.addComponents(firstActionRow, secondActionRow);
|
||||||
|
|
||||||
|
await interaction.showModal(modal);
|
||||||
|
}
|
||||||
|
} else if (interaction.isModalSubmit()) {
|
||||||
|
if (interaction.customId === 'myModal') {
|
||||||
|
const query = interaction.fields.getTextInputValue('queryInput');
|
||||||
|
const moreContext = interaction.fields.getTextInputValue('moreContextInput');
|
||||||
|
|
||||||
|
let thread;
|
||||||
|
if (interaction?.channel?.type === ChannelType.GuildText) {
|
||||||
|
thread = await interaction.channel.threads.create({
|
||||||
|
name: `Discussion: ${query.slice(0, 30)}...`,
|
||||||
|
autoArchiveDuration: 60,
|
||||||
|
reason: 'Discussion thread for the query',
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
await interaction.deferUpdate();
|
||||||
|
|
||||||
|
runDevTeam({ interaction, query, moreContext, thread })
|
||||||
|
.catch(console.error);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
async function runDevTeam({ interaction, query, moreContext, thread }) {
|
||||||
|
const queryToDisplay = `**user query**: ${query}.
|
||||||
|
${moreContext ? '\n**more context**: ' + moreContext : ''}
|
||||||
|
\nBrowsing the web to investigate your query... give me a minute or so`;
|
||||||
|
|
||||||
|
if (!thread) {
|
||||||
|
await interaction.followUp({ content: queryToDisplay });
|
||||||
|
} else {
|
||||||
|
await thread.send(queryToDisplay);
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
while (true) {
|
||||||
|
const response = await sendWebhookMessage({ query, moreContext });
|
||||||
|
|
||||||
|
if (response.type === 'progress') {
|
||||||
|
// Handle progress updates
|
||||||
|
const progressChunks = splitMessage(response.data);
|
||||||
|
for (const chunk of progressChunks) {
|
||||||
|
if (!thread) {
|
||||||
|
await interaction.followUp({ content: chunk });
|
||||||
|
} else {
|
||||||
|
await thread.send(chunk);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
} else if (response.type === 'complete') {
|
||||||
|
// Handle final result
|
||||||
|
if (response.data && response.data.rubber_ducker_thoughts) {
|
||||||
|
let rubberDuckerChunks = '';
|
||||||
|
let theGuidance = response.data.rubber_ducker_thoughts;
|
||||||
|
|
||||||
|
try {
|
||||||
|
rubberDuckerChunks = splitMessage(theGuidance);
|
||||||
|
} catch (error) {
|
||||||
|
console.error('Error splitting messages:', error);
|
||||||
|
rubberDuckerChunks = splitMessage(typeof theGuidance === 'object' ? JSON.stringify(theGuidance) : theGuidance);
|
||||||
|
}
|
||||||
|
|
||||||
|
for (const chunk of rubberDuckerChunks) {
|
||||||
|
if (!thread) {
|
||||||
|
await interaction.followUp({ content: chunk });
|
||||||
|
} else {
|
||||||
|
await thread.send(chunk);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
break; // Exit the loop when we get the final result
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return true;
|
||||||
|
} catch (error) {
|
||||||
|
console.error({ content: 'Error handling message:', error });
|
||||||
|
if (!thread) {
|
||||||
|
return await interaction.followUp({ content: 'There was an error processing your request.' });
|
||||||
|
} else {
|
||||||
|
return await thread.send('There was an error processing your request.');
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
keepAlive();
|
||||||
|
client.login(process.env.DISCORD_BOT_TOKEN);
|
||||||
@ -0,0 +1,21 @@
|
|||||||
|
{
|
||||||
|
"name": "Discord-Bot-JS",
|
||||||
|
"version": "1.0.0",
|
||||||
|
"description": "",
|
||||||
|
"main": "index.js",
|
||||||
|
"dependencies": {
|
||||||
|
"discord.js": "^14.16.1",
|
||||||
|
"dotenv": "^16.4.5",
|
||||||
|
"express": "^4.17.1",
|
||||||
|
"jsonrepair": "^3.8.0",
|
||||||
|
"nodemon": "^3.1.4",
|
||||||
|
"ws": "^8.18.0"
|
||||||
|
},
|
||||||
|
"scripts": {
|
||||||
|
"test": "echo \"Error: no test specified\" && exit 1",
|
||||||
|
"dev": "nodemon --legacy-watch index.js"
|
||||||
|
},
|
||||||
|
"keywords": [],
|
||||||
|
"author": "",
|
||||||
|
"license": "ISC"
|
||||||
|
}
|
||||||
29
systems/research/gpt-researcher/docs/discord-bot/server.js
Normal file
@ -0,0 +1,29 @@
|
|||||||
|
const express = require("express")
|
||||||
|
|
||||||
|
const server = express()
|
||||||
|
|
||||||
|
server.all("/", (req, res) => {
|
||||||
|
res.send("Bot is running!")
|
||||||
|
})
|
||||||
|
|
||||||
|
function keepAlive() {
|
||||||
|
server.listen(5000, () => {
|
||||||
|
console.log("Server is ready.")
|
||||||
|
})
|
||||||
|
|
||||||
|
// Handle uncaught exceptions
|
||||||
|
process.on("uncaughtException", (err) => {
|
||||||
|
console.error("Uncaught Exception:", err);
|
||||||
|
// Graceful shutdown logic
|
||||||
|
// process.exit(1); // Exit process to trigger Docker's restart policy
|
||||||
|
});
|
||||||
|
|
||||||
|
// Handle unhandled promise rejections
|
||||||
|
process.on("unhandledRejection", (reason, promise) => {
|
||||||
|
console.error("Unhandled Rejection at:", promise, "reason:", reason);
|
||||||
|
// Graceful shutdown logic
|
||||||
|
// process.exit(1); // Exit process to trigger Docker's restart policy
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
module.exports = keepAlive
|
||||||
5
systems/research/gpt-researcher/docs/docs/contribute.md
Normal file
@ -0,0 +1,5 @@
|
|||||||
|
# Contribute
|
||||||
|
|
||||||
|
We highly welcome contributions! Please check out [contributing](https://github.com/assafelovic/gpt-researcher/blob/master/CONTRIBUTING.md) if you're interested.
|
||||||
|
|
||||||
|
Please check out our [roadmap](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap) page and reach out to us via our [Discord community](https://discord.gg/QgZXvJAccX) if you're interested in joining our mission.
|
||||||
@ -0,0 +1,73 @@
|
|||||||
|
"""
|
||||||
|
Custom Prompt Example for GPT Researcher
|
||||||
|
|
||||||
|
This example demonstrates how to use the custom_prompt parameter to customize report generation
|
||||||
|
based on specific formatting requirements or content needs.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import nest_asyncio # Required for notebooks/interactive environments
|
||||||
|
|
||||||
|
# Apply nest_asyncio to allow for nested event loops (needed in notebooks)
|
||||||
|
nest_asyncio.apply()
|
||||||
|
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
|
||||||
|
async def custom_report_example():
|
||||||
|
"""Demonstrate various custom prompt examples with GPT Researcher."""
|
||||||
|
|
||||||
|
# Define your research query
|
||||||
|
query = "What are the latest advancements in renewable energy?"
|
||||||
|
report_type = "research_report"
|
||||||
|
|
||||||
|
# Initialize the researcher
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type=report_type,
|
||||||
|
verbose=True # Set to True to see detailed logs
|
||||||
|
)
|
||||||
|
|
||||||
|
# Conduct the research (this step is the same regardless of custom prompts)
|
||||||
|
print("🔍 Conducting research...")
|
||||||
|
await researcher.conduct_research()
|
||||||
|
print("✅ Research completed!\n")
|
||||||
|
|
||||||
|
# Example 1: Standard report (no custom prompt)
|
||||||
|
print("\n📝 EXAMPLE 1: STANDARD REPORT\n" + "="*40)
|
||||||
|
standard_report = await researcher.write_report()
|
||||||
|
print(f"Standard Report Length: {len(standard_report.split())} words\n")
|
||||||
|
print(standard_report[:500] + "...\n") # Print first 500 chars
|
||||||
|
|
||||||
|
# Example 2: Short summary with custom prompt
|
||||||
|
print("\n📝 EXAMPLE 2: SHORT SUMMARY\n" + "="*40)
|
||||||
|
short_prompt = "Provide a brief summary of the research findings in 2-3 paragraphs without citations."
|
||||||
|
short_report = await researcher.write_report(custom_prompt=short_prompt)
|
||||||
|
print(f"Short Report Length: {len(short_report.split())} words\n")
|
||||||
|
print(short_report + "\n")
|
||||||
|
|
||||||
|
# Example 3: Bullet point format
|
||||||
|
print("\n📝 EXAMPLE 3: BULLET POINT FORMAT\n" + "="*40)
|
||||||
|
bullet_prompt = "List the top 5 advancements in renewable energy as bullet points with a brief explanation for each."
|
||||||
|
bullet_report = await researcher.write_report(custom_prompt=bullet_prompt)
|
||||||
|
print(bullet_report + "\n")
|
||||||
|
|
||||||
|
# Example 4: Question and answer format
|
||||||
|
print("\n📝 EXAMPLE 4: Q&A FORMAT\n" + "="*40)
|
||||||
|
qa_prompt = "Present the research as a Q&A session with 5 important questions and detailed answers about renewable energy advancements."
|
||||||
|
qa_report = await researcher.write_report(custom_prompt=qa_prompt)
|
||||||
|
print(qa_report[:500] + "...\n") # Print first 500 chars
|
||||||
|
|
||||||
|
# Example 5: Technical audience
|
||||||
|
print("\n📝 EXAMPLE 5: TECHNICAL AUDIENCE\n" + "="*40)
|
||||||
|
technical_prompt = "Create a technical summary focusing on engineering challenges and solutions in renewable energy. Use appropriate technical terminology."
|
||||||
|
technical_report = await researcher.write_report(custom_prompt=technical_prompt)
|
||||||
|
print(technical_report[:500] + "...\n") # Print first 500 chars
|
||||||
|
|
||||||
|
# Show research costs
|
||||||
|
print("\n💰 RESEARCH COSTS")
|
||||||
|
print(f"Total tokens used: {researcher.get_costs()}")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
asyncio.run(custom_report_example())
|
||||||
@ -0,0 +1,82 @@
|
|||||||
|
# Detailed Report
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
|
||||||
|
The `DetailedReport` class inspired by the recent STORM paper, is a powerful component of GPT Researcher, designed to generate comprehensive reports on complex topics. It's particularly useful for creating long-form content that exceeds the typical limits of LLM outputs. This class orchestrates the research process, breaking down the main query into subtopics, conducting in-depth research on each, and combining the results into a cohesive, detailed report.
|
||||||
|
|
||||||
|
Located in `backend/report_types/detailed_report.py` in the [GPT Researcher GitHub repository](https://github.com/assafelovic/gpt-researcher), this class leverages the capabilities of the `GPTResearcher` agent to perform targeted research and generate content.
|
||||||
|
|
||||||
|
## Key Features
|
||||||
|
|
||||||
|
- Breaks down complex topics into manageable subtopics
|
||||||
|
- Conducts in-depth research on each subtopic
|
||||||
|
- Generates a comprehensive report with introduction, table of contents, and body
|
||||||
|
- Avoids redundancy by tracking previously written content
|
||||||
|
- Supports asynchronous operations for improved performance
|
||||||
|
|
||||||
|
## Class Structure
|
||||||
|
|
||||||
|
### Initialization
|
||||||
|
|
||||||
|
The `DetailedReport` class is initialized with the following parameters:
|
||||||
|
|
||||||
|
- `query`: The main research query
|
||||||
|
- `report_type`: Type of the report
|
||||||
|
- `report_source`: Source of the report
|
||||||
|
- `source_urls`: Initial list of source URLs
|
||||||
|
- `config_path`: Path to the configuration file
|
||||||
|
- `tone`: Tone of the report (using the `Tone` enum)
|
||||||
|
- `websocket`: WebSocket for real-time communication
|
||||||
|
- `subtopics`: Optional list of predefined subtopics
|
||||||
|
- `headers`: Optional headers for HTTP requests
|
||||||
|
|
||||||
|
## How It Works
|
||||||
|
|
||||||
|
1. The `DetailedReport` class starts by conducting initial research on the main query.
|
||||||
|
2. It then breaks down the topic into subtopics.
|
||||||
|
3. For each subtopic, it:
|
||||||
|
- Conducts focused research
|
||||||
|
- Generates draft section titles
|
||||||
|
- Retrieves relevant previously written content to avoid redundancy
|
||||||
|
- Writes a report section
|
||||||
|
4. Finally, it combines all subtopic reports, adds a table of contents, and includes source references to create the final detailed report.
|
||||||
|
|
||||||
|
## Usage Example
|
||||||
|
|
||||||
|
Here's how you can use the `DetailedReport` class in your project:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import asyncio
|
||||||
|
from fastapi import WebSocket
|
||||||
|
from gpt_researcher.utils.enum import Tone
|
||||||
|
from backend.report_type import DetailedReport
|
||||||
|
|
||||||
|
async def generate_report(websocket: WebSocket):
|
||||||
|
detailed_report = DetailedReport(
|
||||||
|
query="The impact of artificial intelligence on modern healthcare",
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="web_search",
|
||||||
|
source_urls=[], # You can provide initial source URLs if available
|
||||||
|
config_path="path/to/config.yaml",
|
||||||
|
tone=Tone.FORMAL,
|
||||||
|
websocket=websocket,
|
||||||
|
subtopics=[], # You can provide predefined subtopics if desired
|
||||||
|
headers={} # Add any necessary HTTP headers
|
||||||
|
)
|
||||||
|
|
||||||
|
final_report = await detailed_report.run()
|
||||||
|
return final_report
|
||||||
|
|
||||||
|
# In your FastAPI app
|
||||||
|
@app.websocket("/generate_report")
|
||||||
|
async def websocket_endpoint(websocket: WebSocket):
|
||||||
|
await websocket.accept()
|
||||||
|
report = await generate_report(websocket)
|
||||||
|
await websocket.send_text(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
This example demonstrates how to create a `DetailedReport` instance and run it to generate a comprehensive report on the impact of AI on healthcare.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
The `DetailedReport` class is a sophisticated tool for generating in-depth, well-structured reports on complex topics. By breaking down the main query into subtopics and leveraging the power of GPT Researcher, it can produce content that goes beyond the typical limitations of LLM outputs. This makes it an invaluable asset for researchers, content creators, and anyone needing detailed, well-researched information on a given topic.
|
||||||
@ -0,0 +1,261 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "6ab73899",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Tavily Samples"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "013eda36",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Setup"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "8ad25551",
|
||||||
|
"metadata": {
|
||||||
|
"ExecuteTime": {
|
||||||
|
"end_time": "2023-11-08T15:57:13.339729Z",
|
||||||
|
"start_time": "2023-11-08T15:57:11.156595Z"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# install tavily\n",
|
||||||
|
"!pip install tavily-python"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 3,
|
||||||
|
"id": "c0722950",
|
||||||
|
"metadata": {
|
||||||
|
"ExecuteTime": {
|
||||||
|
"end_time": "2023-11-08T16:01:01.318977Z",
|
||||||
|
"start_time": "2023-11-08T16:01:01.314688Z"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# import and connect\n",
|
||||||
|
"from tavily import TavilyClient\n",
|
||||||
|
"client = TavilyClient(api_key=\"\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 5,
|
||||||
|
"id": "9328a188",
|
||||||
|
"metadata": {
|
||||||
|
"ExecuteTime": {
|
||||||
|
"end_time": "2023-11-08T16:02:25.587726Z",
|
||||||
|
"start_time": "2023-11-08T16:02:18.663961Z"
|
||||||
|
},
|
||||||
|
"scrolled": true
|
||||||
|
},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"{'query': 'What happend in the latest burning man floods?',\n",
|
||||||
|
" 'follow_up_questions': ['How severe were the floods at Burning Man?',\n",
|
||||||
|
" 'What were the impacts of the floods?',\n",
|
||||||
|
" 'How did the organizers handle the floods at Burning Man?'],\n",
|
||||||
|
" 'answer': None,\n",
|
||||||
|
" 'images': None,\n",
|
||||||
|
" 'results': [{'content': \"This year’s rains opened the floodgates for Burning Man criticism Give Newsletters Site search Vox main menu Filed under: The Burning Man flameout, explained Climate change — and schadenfreude\\xa0— finally caught up to the survivalist cosplayers. Share this story Share Has Burning Man finally lost its glamour? September 1, after most of the scheduled events and live performances were canceled due to the weather, Burning Man organizers closed routes in and out of the area, forcing attendees to stay behindShare Attendees look at a rainbow over flooding on a desert plain on September 1, 2023, after heavy rains turned the annual Burning Man festival site in Nevada's Black Rock desert into a mud...\",\n",
|
||||||
|
" 'url': 'https://www.vox.com/culture/2023/9/6/23861675/burning-man-2023-mud-stranded-climate-change-playa-foot',\n",
|
||||||
|
" 'score': 0.9797,\n",
|
||||||
|
" 'raw_content': None},\n",
|
||||||
|
" {'content': 'Tens of thousands of Burning Man festivalgoers are slowly making their way home from the Nevada desert after muddy conditions from heavy rains made it nearly impossible to leave over the weekend. according to burningman.org. Though the death at this year\\'s Burning Man is still being investigated, a social media hoax was blamed for spreading rumors that it\\'s due to a breakout of Ebola. \"Thank goodness this community knows how to take care of each other,\" the Instagram page for Burning Man Information Radio wrote on a post predicting more rain.News Burning Man attendees make mass exodus after being stranded in the mud at festival A caravan of festivalgoers were backed up as much as eight hours when they were finally allowed to leave...',\n",
|
||||||
|
" 'url': 'https://www.today.com/news/what-is-burning-man-flood-death-rcna103231',\n",
|
||||||
|
" 'score': 0.9691,\n",
|
||||||
|
" 'raw_content': None},\n",
|
||||||
|
" {'content': '“It was a perfect, typical Burning Man weather until Friday — then the rain started coming down hard,\" said Phillip Martin, 37. \"Then it turned into Mud Fest.\" After more than a half-inch (1.3 centimeters) of rain fell Friday, flooding turned the playa to foot-deep mud — closing roads and forcing burners to lean on each other for help. ABC News Video Live Shows Election 2024 538 Stream on No longer stranded, tens of thousands clean up and head home after Burning Man floods Mark Fromson, 54, who goes by the name “Stuffy” on the playa, had been staying in an RV, but the rains forced him to find shelter at another camp, where fellow burners provided him food and cover.RENO, Nev. -- The traffic jam leaving the Burning Man festival eased up considerably Tuesday as the exodus from the mud-caked Nevada desert entered another day following massive rain that left tens of thousands of partygoers stranded for days.',\n",
|
||||||
|
" 'url': 'https://abcnews.go.com/US/wireStory/wait-times-exit-burning-man-drop-after-flooding-102936473',\n",
|
||||||
|
" 'score': 0.9648,\n",
|
||||||
|
" 'raw_content': None},\n",
|
||||||
|
" {'content': 'Burning Man hit by heavy rains, now mud soaked.People there told to conserve food and water as they shelter in place.(Video: Josh Keppel) pic.twitter.com/DuBj0Ejtb8 More on this story Burning Man revelers begin exodus from festival after road reopens Officials investigate death at Burning Man as thousands stranded by floods Burning Man festival-goers trapped in desert as rain turns site to mud Tens of thousands of ‘burners’ urged to conserve food and water as rain and flash floods sweep Nevada Burning Man festivalgoers surrounded by mud in Nevada desert – video Burning Man attendees roadblocked by climate activists: ‘They have a privileged mindset’Last year, Burning Man drew approximately 80,000 people. This year, only about 60,000 were expected - with many citing the usual heat and dust and eight-hour traffic jams when they tried to leave.',\n",
|
||||||
|
" 'url': 'https://www.theguardian.com/culture/2023/sep/02/burning-man-festival-mud-trapped-shelter-in-place',\n",
|
||||||
|
" 'score': 0.9618,\n",
|
||||||
|
" 'raw_content': None},\n",
|
||||||
|
" {'content': 'Skip links Live Navigation menu Live Death at Burning Man investigated in US, thousands stranded by flooding Attendees trudged through mud, many barefoot or wearing plastic bags on their feet. The revellers were urged to shelter in place and conserve food, water and other supplies. Thousands of festivalgoers remain stranded as organisers close vehicular traffic to the festival site following storm flooding in Nevada’s desert. Authorities in Nevada are investigating a death at the site of the Burning Man festival, where thousands of attendees remained stranded after flooding from storms swept through the Nevada desert in3 Sep 2023. Authorities in Nevada are investigating a death at the site of the Burning Man festival, where thousands of attendees remained stranded after flooding from storms swept through the ...',\n",
|
||||||
|
" 'url': 'https://www.aljazeera.com/news/2023/9/3/death-under-investigation-after-storm-flooding-at-burning-man-festival',\n",
|
||||||
|
" 'score': 0.9612,\n",
|
||||||
|
" 'raw_content': None}],\n",
|
||||||
|
" 'response_time': 6.23}"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 5,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"# simple query using tavily's advanced search\n",
|
||||||
|
"client.search(\"What happend in the latest burning man floods?\", search_depth=\"advanced\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "e98ea835",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Sample 1: Reseach Report using Tavily and GPT-4 with Langchain"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "b7b05128",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# install lanchain\n",
|
||||||
|
"!pip install langchain"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 12,
|
||||||
|
"id": "b2246f61",
|
||||||
|
"metadata": {
|
||||||
|
"ExecuteTime": {
|
||||||
|
"end_time": "2023-11-08T16:57:59.797466Z",
|
||||||
|
"start_time": "2023-11-08T16:57:59.793194Z"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# set up openai api key\n",
|
||||||
|
"openai_api_key = \"\""
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 13,
|
||||||
|
"id": "c574f1b8",
|
||||||
|
"metadata": {
|
||||||
|
"ExecuteTime": {
|
||||||
|
"end_time": "2023-11-08T16:59:03.572367Z",
|
||||||
|
"start_time": "2023-11-08T16:58:01.823114Z"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"# The Burning Man Festival 2023: A Festival Turned Mud Fest\n",
|
||||||
|
"\n",
|
||||||
|
"**Abstract:** The Burning Man Festival of 2023 in Nevada’s Black Rock desert will be remembered for a significant event: a heavy rainfall that turned the festival site into a muddy mess, testing the community spirit of the annual event attendees and stranding tens of thousands of festival-goers. \n",
|
||||||
|
"\n",
|
||||||
|
"**Keywords:** Burning Man Festival, flooding, rainfall, mud, community spirit, Nevada, Black Rock desert, stranded attendees, shelter\n",
|
||||||
|
"\n",
|
||||||
|
"---\n",
|
||||||
|
"## 1. Introduction\n",
|
||||||
|
"\n",
|
||||||
|
"The Burning Man Festival, an annual event known for its art installations, free spirit, and community ethos, faced an unprecedented challenge in 2023 due to heavy rains that flooded the festival site, turning it into a foot-deep mud pit[^1^][^2^]. The festival, held in Nevada's Black Rock desert, is known for its harsh weather conditions, including heat and dust, but this was the first time the event was affected to such an extent by rainfall[^4^].\n",
|
||||||
|
"\n",
|
||||||
|
"## 2. Impact of the Rain\n",
|
||||||
|
"\n",
|
||||||
|
"The heavy rains started on Friday, and more than a half-inch of rain fell, leading to flooding that turned the playa into a foot-deep mud pit[^2^]. The roads were closed due to the muddy conditions, stranding tens of thousands of festival-goers[^2^][^5^]. The burners, as the attendees are known, were forced to lean on each other for help[^2^].\n",
|
||||||
|
"\n",
|
||||||
|
"## 3. Community Spirit Tested\n",
|
||||||
|
"\n",
|
||||||
|
"The unexpected weather conditions put the Burning Man community spirit to the test[^1^]. Festival-goers found themselves sheltering in place, conserving food and water, and helping each other out[^3^]. For instance, Mark Fromson, who had been staying in an RV, was forced to find shelter at another camp due to the rains, where fellow burners provided him with food and cover[^2^].\n",
|
||||||
|
"\n",
|
||||||
|
"## 4. Exodus After Rain\n",
|
||||||
|
"\n",
|
||||||
|
"Despite the challenges, the festival-goers made the best of the situation. Once the rain stopped and things dried up a bit, the party quickly resumed[^3^]. A day later than scheduled, the massive wooden effigy known as the Man was set ablaze[^5^]. As the situation improved, thousands of Burning Man attendees began their mass exodus from the festival site[^5^].\n",
|
||||||
|
"\n",
|
||||||
|
"## 5. Conclusion\n",
|
||||||
|
"\n",
|
||||||
|
"The Burning Man Festival of 2023 will be remembered for the community spirit shown by the attendees in the face of heavy rainfall and flooding. Although the event was marred by the weather, the festival-goers managed to make the best of the situation, demonstrating the resilience and camaraderie that the Burning Man Festival is known for.\n",
|
||||||
|
"\n",
|
||||||
|
"---\n",
|
||||||
|
"**References**\n",
|
||||||
|
"\n",
|
||||||
|
"[^1^]: \"Attendees walk through a muddy desert plain...\" NPR. 2023. https://www.npr.org/2023/09/02/1197441202/burning-man-festival-rains-floods-stranded-nevada.\n",
|
||||||
|
"\n",
|
||||||
|
"[^2^]: “'It was a perfect, typical Burning Man weather until Friday...'\" ABC News. 2023. https://abcnews.go.com/US/wireStory/wait-times-exit-burning-man-drop-after-flooding-102936473.\n",
|
||||||
|
"\n",
|
||||||
|
"[^3^]: \"The latest on the Burning Man flooding...\" WUNC. 2023. https://www.wunc.org/2023-09-03/the-latest-on-the-burning-man-flooding.\n",
|
||||||
|
"\n",
|
||||||
|
"[^4^]: \"Burning Man hit by heavy rains, now mud soaked...\" The Guardian. 2023. https://www.theguardian.com/culture/2023/sep/02/burning-man-festival-mud-trapped-shelter-in-place.\n",
|
||||||
|
"\n",
|
||||||
|
"[^5^]: \"One day later than scheduled, the massive wooden effigy known as the Man was set ablaze...\" CNN. 2023. https://www.cnn.com/2023/09/05/us/burning-man-storms-shelter-exodus-tuesday/index.html.\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"# libraries\n",
|
||||||
|
"from langchain.adapters.openai import convert_openai_messages\n",
|
||||||
|
"from langchain_community.chat_models import ChatOpenAI\n",
|
||||||
|
"\n",
|
||||||
|
"# setup query\n",
|
||||||
|
"query = \"What happend in the latest burning man floods?\"\n",
|
||||||
|
"\n",
|
||||||
|
"# run tavily search\n",
|
||||||
|
"content = client.search(query, search_depth=\"advanced\")[\"results\"]\n",
|
||||||
|
"\n",
|
||||||
|
"# setup prompt\n",
|
||||||
|
"prompt = [{\n",
|
||||||
|
" \"role\": \"system\",\n",
|
||||||
|
" \"content\": f'You are an AI critical thinker research assistant. '\\\n",
|
||||||
|
" f'Your sole purpose is to write well written, critically acclaimed,'\\\n",
|
||||||
|
" f'objective and structured reports on given text.'\n",
|
||||||
|
"}, {\n",
|
||||||
|
" \"role\": \"user\",\n",
|
||||||
|
" \"content\": f'Information: \"\"\"{content}\"\"\"\\n\\n' \\\n",
|
||||||
|
" f'Using the above information, answer the following'\\\n",
|
||||||
|
" f'query: \"{query}\" in a detailed report --'\\\n",
|
||||||
|
" f'Please use MLA format and markdown syntax.'\n",
|
||||||
|
"}]\n",
|
||||||
|
"\n",
|
||||||
|
"# run gpt-4\n",
|
||||||
|
"lc_messages = convert_openai_messages(prompt)\n",
|
||||||
|
"report = ChatOpenAI(model='gpt-4',openai_api_key=openai_api_key).invoke(lc_messages).content\n",
|
||||||
|
"\n",
|
||||||
|
"# print report\n",
|
||||||
|
"print(report)\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "c679fbfe",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3 (ipykernel)",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python3"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.10.6"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 5
|
||||||
|
}
|
||||||
@ -0,0 +1,77 @@
|
|||||||
|
# Simple Run
|
||||||
|
|
||||||
|
### Run PIP Package
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
### Using Quick Run
|
||||||
|
async def main():
|
||||||
|
"""
|
||||||
|
This is a sample script that shows how to run a research report.
|
||||||
|
"""
|
||||||
|
# Query
|
||||||
|
query = "What happened in the latest burning man floods?"
|
||||||
|
|
||||||
|
# Report Type
|
||||||
|
report_type = "research_report"
|
||||||
|
|
||||||
|
# Initialize the researcher
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, config_path=None)
|
||||||
|
# Conduct research on the given query
|
||||||
|
await researcher.conduct_research()
|
||||||
|
# Write the report
|
||||||
|
report = await researcher.write_report()
|
||||||
|
|
||||||
|
return report
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
asyncio.run(main())
|
||||||
|
|
||||||
|
# Custom Report Formatting
|
||||||
|
|
||||||
|
### Using Custom Prompts
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
|
||||||
|
async def main():
|
||||||
|
"""
|
||||||
|
This example shows how to use custom prompts to control report formatting.
|
||||||
|
"""
|
||||||
|
# Query
|
||||||
|
query = "What are the latest advancements in renewable energy?"
|
||||||
|
|
||||||
|
# Report Type
|
||||||
|
report_type = "research_report"
|
||||||
|
|
||||||
|
# Initialize the researcher
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type)
|
||||||
|
|
||||||
|
# Conduct research on the given query
|
||||||
|
await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Generate a standard report
|
||||||
|
standard_report = await researcher.write_report()
|
||||||
|
print("Standard Report Generated")
|
||||||
|
|
||||||
|
# Generate a short, concise report using custom_prompt
|
||||||
|
custom_prompt = "Provide a concise summary in 2 paragraphs without citations."
|
||||||
|
short_report = await researcher.write_report(custom_prompt=custom_prompt)
|
||||||
|
print("Short Report Generated")
|
||||||
|
|
||||||
|
# Generate a bullet-point format report
|
||||||
|
bullet_prompt = "List the top 5 advancements as bullet points with brief explanations."
|
||||||
|
bullet_report = await researcher.write_report(custom_prompt=bullet_prompt)
|
||||||
|
print("Bullet-Point Report Generated")
|
||||||
|
|
||||||
|
return standard_report, short_report, bullet_report
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
asyncio.run(main())
|
||||||
|
|
||||||
|
For more comprehensive examples of using custom prompts, see the `custom_prompt.py` file included in the examples directory.
|
||||||
|
```
|
||||||
@ -0,0 +1,125 @@
|
|||||||
|
# Hybrid Research
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
GPT Researcher can combine web search capabilities with local document analysis to provide comprehensive, context-aware research results.
|
||||||
|
|
||||||
|
This guide will walk you through the process of setting up and running hybrid research using GPT Researcher.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
Before you begin, ensure you have the following:
|
||||||
|
|
||||||
|
- Python 3.10 or higher installed on your system
|
||||||
|
- pip (Python package installer)
|
||||||
|
- An OpenAI API key (you can also choose other supported [LLMs](../gpt-researcher/llms/llms.md))
|
||||||
|
- A Tavily API key (you can also choose other supported [Retrievers](../gpt-researcher/search-engines/retrievers.md))
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install gpt-researcher
|
||||||
|
```
|
||||||
|
|
||||||
|
## Setting Up the Environment
|
||||||
|
|
||||||
|
Export your API keys as environment variables:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY=your_openai_api_key_here
|
||||||
|
export TAVILY_API_KEY=your_tavily_api_key_here
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, you can set these in your Python script:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
os.environ['OPENAI_API_KEY'] = 'your_openai_api_key_here'
|
||||||
|
os.environ['TAVILY_API_KEY'] = 'your_tavily_api_key_here'
|
||||||
|
```
|
||||||
|
Set the environment variable REPORT_SOURCE to an empty string "" in default.py
|
||||||
|
## Preparing Documents
|
||||||
|
|
||||||
|
### 1. Local Documents
|
||||||
|
1. Create a directory named `my-docs` in your project folder.
|
||||||
|
2. Place all relevant local documents (PDFs, TXTs, DOCXs, etc.) in this directory.
|
||||||
|
|
||||||
|
### 2. Online Documents
|
||||||
|
1. Here is an example of your online document URL example: https://xxxx.xxx.pdf (supports file formats like PDFs, TXTs, DOCXs, etc.)
|
||||||
|
|
||||||
|
|
||||||
|
## Running Hybrid Research By "Local Documents"
|
||||||
|
|
||||||
|
Here's a basic script to run hybrid research:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_research_report(query: str, report_type: str, report_source: str) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, report_source=report_source)
|
||||||
|
research = await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "How does our product roadmap compare to emerging market trends in our industry?"
|
||||||
|
report_source = "hybrid"
|
||||||
|
|
||||||
|
report = asyncio.run(get_research_report(query=query, report_type="research_report", report_source=report_source))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Running Hybrid Research By "Online Documents"
|
||||||
|
|
||||||
|
Here's a basic script to run hybrid research:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_research_report(query: str, report_type: str, report_source: str) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, document_urls=document_urls, report_source=report_source)
|
||||||
|
research = await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "How does our product roadmap compare to emerging market trends in our industry?"
|
||||||
|
report_source = "hybrid"
|
||||||
|
document_urls = ["https://xxxx.xxx.pdf", "https://xxxx.xxx.doc"]
|
||||||
|
|
||||||
|
report = asyncio.run(get_research_report(query=query, report_type="research_report", document_urls=document_urls, report_source=report_source))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
To run the script:
|
||||||
|
|
||||||
|
1. Save it as `run_research.py`
|
||||||
|
2. Execute it with: `python run_research.py`
|
||||||
|
|
||||||
|
## Understanding the Results
|
||||||
|
|
||||||
|
The output will be a comprehensive research report that combines insights from both web sources and your local documents. The report typically includes an executive summary, key findings, detailed analysis, comparisons between your internal data and external trends, and recommendations based on the combined insights.
|
||||||
|
|
||||||
|
## Troubleshooting
|
||||||
|
|
||||||
|
1. **API Key Issues**: Ensure your API keys are correctly set and have the necessary permissions.
|
||||||
|
2. **Document Loading Errors**: Check that your local documents are in supported formats and are not corrupted.
|
||||||
|
3. **Memory Issues**: For large documents or extensive research, you may need to increase your system's available memory or adjust the `chunk_size` in the document processing step.
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
**Q: How long does a typical research session take?**
|
||||||
|
A: The duration varies based on the complexity of the query and the amount of data to process. It can range from 1-5 minutes for very comprehensive research.
|
||||||
|
|
||||||
|
**Q: Can I use GPT Researcher with other language models?**
|
||||||
|
A: Currently, GPT Researcher is optimized for OpenAI's models. Support for other models can be found [here](../gpt-researcher/llms/llms.md).
|
||||||
|
|
||||||
|
**Q: How does GPT Researcher handle conflicting information between local and web sources?**
|
||||||
|
A: The system attempts to reconcile differences by providing context and noting discrepancies in the final report. It prioritizes more recent or authoritative sources when conflicts arise.
|
||||||
|
|
||||||
|
**Q: Is my local data sent to external servers during the research process?**
|
||||||
|
A: No, your local documents are processed on your machine. Only the generated queries and synthesized information (not raw data) are sent to external services for web research.
|
||||||
|
|
||||||
|
For more information and updates, please visit the [GPT Researcher GitHub repository](https://github.com/assafelovic/gpt-researcher).
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
{
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 0,
|
||||||
|
"metadata": {
|
||||||
|
"colab": {
|
||||||
|
"provenance": []
|
||||||
|
},
|
||||||
|
"kernelspec": {
|
||||||
|
"name": "python3",
|
||||||
|
"display_name": "Python 3"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"name": "python"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 1,
|
||||||
|
"metadata": {
|
||||||
|
"id": "byPgKYhAE6gn"
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import os\n",
|
||||||
|
"os.environ['OPENAI_API_KEY'] = 'your_openai_api_key'\n",
|
||||||
|
"os.environ['TAVILY_API_KEY'] = 'your_tavily_api_key' # Get a free key here: https://app.tavily.com"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"source": [
|
||||||
|
"!pip install -U gpt-researcher nest_asyncio"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"id": "-rXET3OZLxwH"
|
||||||
|
},
|
||||||
|
"execution_count": null,
|
||||||
|
"outputs": []
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"source": [
|
||||||
|
"import nest_asyncio # required for notebooks\n",
|
||||||
|
"nest_asyncio.apply()\n",
|
||||||
|
"\n",
|
||||||
|
"from gpt_researcher import GPTResearcher\n",
|
||||||
|
"import asyncio\n",
|
||||||
|
"\n",
|
||||||
|
"async def get_report(query: str, report_type: str) -> str:\n",
|
||||||
|
" researcher = GPTResearcher(query, report_type)\n",
|
||||||
|
" research_result = await researcher.conduct_research()\n",
|
||||||
|
" report = await researcher.write_report()\n",
|
||||||
|
" \n",
|
||||||
|
" # Get additional information\n",
|
||||||
|
" research_context = researcher.get_research_context()\n",
|
||||||
|
" research_costs = researcher.get_costs()\n",
|
||||||
|
" research_images = researcher.get_research_images()\n",
|
||||||
|
" research_sources = researcher.get_research_sources()\n",
|
||||||
|
" \n",
|
||||||
|
" return report, research_context, research_costs, research_images, research_sources\n",
|
||||||
|
"\n",
|
||||||
|
"if __name__ == \"__main__\":\n",
|
||||||
|
" query = \"Should I invest in Nvidia?\"\n",
|
||||||
|
" report_type = \"research_report\"\n",
|
||||||
|
"\n",
|
||||||
|
" report, context, costs, images, sources = asyncio.run(get_report(query, report_type))\n",
|
||||||
|
" \n",
|
||||||
|
" print(\"Report:\")\n",
|
||||||
|
" print(report)\n",
|
||||||
|
" print(\"\\nResearch Costs:\")\n",
|
||||||
|
" print(costs)\n",
|
||||||
|
" print(\"\\nResearch Images:\")\n",
|
||||||
|
" print(images)\n",
|
||||||
|
" print(\"\\nResearch Sources:\")\n",
|
||||||
|
" print(sources)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"id": "KWZe2InrL0ji"
|
||||||
|
},
|
||||||
|
"execution_count": null,
|
||||||
|
"outputs": []
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
@ -0,0 +1,47 @@
|
|||||||
|
import nest_asyncio # required for notebooks
|
||||||
|
|
||||||
|
nest_asyncio.apply()
|
||||||
|
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
|
||||||
|
async def get_report(query: str, report_type: str, custom_prompt: str = None):
|
||||||
|
researcher = GPTResearcher(query, report_type)
|
||||||
|
research_result = await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Generate report with optional custom prompt
|
||||||
|
report = await researcher.write_report(custom_prompt=custom_prompt)
|
||||||
|
|
||||||
|
# Get additional information
|
||||||
|
research_context = researcher.get_research_context()
|
||||||
|
research_costs = researcher.get_costs()
|
||||||
|
research_images = researcher.get_research_images()
|
||||||
|
research_sources = researcher.get_research_sources()
|
||||||
|
|
||||||
|
return report, research_context, research_costs, research_images, research_sources
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "Should I invest in Nvidia?"
|
||||||
|
report_type = "research_report"
|
||||||
|
|
||||||
|
# Standard report
|
||||||
|
report, context, costs, images, sources = asyncio.run(get_report(query, report_type))
|
||||||
|
|
||||||
|
print("Standard Report:")
|
||||||
|
print(report)
|
||||||
|
|
||||||
|
# Custom report with specific formatting requirements
|
||||||
|
custom_prompt = "Answer in short, 2 paragraphs max without citations. Focus on the most important facts for investors."
|
||||||
|
custom_report, _, _, _, _ = asyncio.run(get_report(query, report_type, custom_prompt))
|
||||||
|
|
||||||
|
print("\nCustomized Short Report:")
|
||||||
|
print(custom_report)
|
||||||
|
|
||||||
|
print("\nResearch Costs:")
|
||||||
|
print(costs)
|
||||||
|
print("\nNumber of Research Images:")
|
||||||
|
print(len(images))
|
||||||
|
print("\nNumber of Research Sources:")
|
||||||
|
print(len(sources))
|
||||||
@ -0,0 +1,20 @@
|
|||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
|
||||||
|
async def get_report(query: str, report_source: str, sources: list) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_source=report_source, source_urls=sources)
|
||||||
|
research_context = await researcher.conduct_research()
|
||||||
|
return await researcher.write_report()
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "What are the biggest trends in AI lately?"
|
||||||
|
report_source = "static"
|
||||||
|
sources = [
|
||||||
|
"https://en.wikipedia.org/wiki/Artificial_intelligence",
|
||||||
|
"https://www.ibm.com/think/insights/artificial-intelligence-trends",
|
||||||
|
"https://www.forbes.com/advisor/business/ai-statistics"
|
||||||
|
]
|
||||||
|
|
||||||
|
report = asyncio.run(get_report(query=query, report_source=report_source, sources=sources))
|
||||||
|
print(report)
|
||||||
34
systems/research/gpt-researcher/docs/docs/faq.md
Normal file
@ -0,0 +1,34 @@
|
|||||||
|
# FAQ
|
||||||
|
|
||||||
|
### How do I get started?
|
||||||
|
It really depends on what you're aiming for.
|
||||||
|
|
||||||
|
If you're looking to connect your AI application to the internet with Tavily tailored API, check out the [Tavily API](https://docs.tavily.com/docs/tavily-api/introductionn) documentation.
|
||||||
|
If you're looking to build and deploy our open source autonomous research agent GPT Researcher, please see [GPT Researcher](/docs/gpt-researcher/getting-started/introduction) documentation.
|
||||||
|
You can also check out demos and examples for inspiration [here](/docs/examples/examples).
|
||||||
|
|
||||||
|
### What is GPT Researcher?
|
||||||
|
|
||||||
|
GPT Researcher is a popular open source autonomous research agent that takes care of the tedious task of research for you, by scraping, filtering and aggregating over 20+ web sources per a single research task.
|
||||||
|
|
||||||
|
GPT Researcher is built with best practices for leveraging LLMs (prompt engineering, RAG, chains, embeddings, etc), and is optimized for quick and efficient research. It is also fully customizable and can be tailored to your specific needs.
|
||||||
|
|
||||||
|
To learn more about GPT Researcher, check out the [documentation page](/docs/gpt-researcher/getting-started/introduction).
|
||||||
|
|
||||||
|
### How much does each research run cost?
|
||||||
|
|
||||||
|
A research task using GPT Researcher costs around $0.01 per a single run (for GPT-4 usage). We're constantly optimizing LLM calls to reduce costs and improve performance.
|
||||||
|
|
||||||
|
### How do you ensure the report is factual and accurate?
|
||||||
|
|
||||||
|
we do our best to ensure that the information we provide is factual and accurate. We do this by using multiple sources, and by using proprietary AI to score and rank the most relevant and accurate information. We also use proprietary AI to filter out irrelevant information and sources.
|
||||||
|
|
||||||
|
Lastly, by using RAG and other techniques, we ensure that the information is relevant to the context of the research task, leading to more accurate generative AI content and reduced hallucinations.
|
||||||
|
|
||||||
|
### What are your plans for the future?
|
||||||
|
|
||||||
|
We're constantly working on improving our products and services. We're currently working on improving our search API together with design partners, and adding more data sources to our search engine. We're also working on improving our research agent GPT Researcher, and adding more features to it while growing our amazing open source community.
|
||||||
|
|
||||||
|
If you're interested in our roadmap or looking to collaborate, check out our [roadmap page](https://trello.com/b/3O7KBePw/gpt-researcher-roadmap).
|
||||||
|
|
||||||
|
Feel free to [contact us](mailto:assafelovic@gmail.com) if you have any further questions or suggestions!
|
||||||
@ -0,0 +1,26 @@
|
|||||||
|
# Azure Storage
|
||||||
|
|
||||||
|
If you want to use Azure Blob Storage as the source for your GPT Researcher report context, follow these steps:
|
||||||
|
|
||||||
|
> **Step 1** - Set these environment variables with a .env file in the root folder
|
||||||
|
|
||||||
|
```bash
|
||||||
|
AZURE_CONNECTION_STRING=
|
||||||
|
AZURE_CONTAINER_NAME=
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Step 2** - Add the `azure-storage-blob` dependency to your requirements.txt file
|
||||||
|
|
||||||
|
```bash
|
||||||
|
azure-storage-blob
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Step 3** - When running the GPTResearcher class, pass the `report_source` as `azure`
|
||||||
|
|
||||||
|
```python
|
||||||
|
report = GPTResearcher(
|
||||||
|
query="What happened in the latest burning man floods?",
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="azure",
|
||||||
|
)
|
||||||
|
```
|
||||||
@ -0,0 +1,154 @@
|
|||||||
|
# Data Ingestion
|
||||||
|
|
||||||
|
When you're dealing with a large amount of context data, you may want to start meditating upon a standalone process for data ingestion.
|
||||||
|
|
||||||
|
Some signs that the system is telling you to move to a custom data ingestion process:
|
||||||
|
|
||||||
|
- Your embedding model is hitting API rate limits
|
||||||
|
- Your Langchain VectorStore's underlying database needs rate limiting
|
||||||
|
- You sense you need to add custom pacing/throttling logic in your Python code
|
||||||
|
|
||||||
|
As mentioned in our [YouTube Tutorial Series](https://www.youtube.com/watch?v=yRuduRCblbg), GPTR is using [Langchain Documents](https://python.langchain.com/api_reference/core/documents/langchain_core.documents.base.Document.html) and [Langchain VectorStores](https://python.langchain.com/v0.1/docs/modules/data_connection/vectorstores/) under the hood.
|
||||||
|
|
||||||
|
These are 2 beautiful abstractions that make the GPTR architecture highly configurable.
|
||||||
|
|
||||||
|
The current research flow, whether you're generating reports on web or local documents, is:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Step 1: transform your content (web results or local documents) into Langchain Documents
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Step 2: Insert your Langchain Documents into a Langchain VectorStore
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Step 3: Pass your Langchain Vectorstore into your GPTR report ([more on that here](https://docs.gptr.dev/docs/gpt-researcher/context/vector-stores) and below)
|
||||||
|
```
|
||||||
|
|
||||||
|
Code samples below:
|
||||||
|
|
||||||
|
Assuming your .env variables are like so:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
OPENAI_API_KEY={Your OpenAI API Key here}
|
||||||
|
TAVILY_API_KEY={Your Tavily API Key here}
|
||||||
|
PGVECTOR_CONNECTION_STRING=postgresql://username:password...
|
||||||
|
```
|
||||||
|
|
||||||
|
Below is a custom data ingestion process that you can use to ingest your data into a Langchain VectorStore. See a [full working example here](https://github.com/assafelovic/gpt-researcher/pull/819#issue-2501632831).
|
||||||
|
In this example, we're using a Postgres VectorStore to embed data of a Github Branch, but you can use [any supported Langchain VectorStore](https://python.langchain.com/v0.2/docs/integrations/vectorstores/).
|
||||||
|
|
||||||
|
Note that when you create the Langchain Documents, you should include as metadata the `source` and `title` fields in order for GPTR to leverage your Documents seamlessly. In the example below, we're splitting the documents list into chunks of 100 & then inserting 1 chunk at a time into the vector store.
|
||||||
|
|
||||||
|
### Step 1: Transform your content into Langchain Documents
|
||||||
|
|
||||||
|
```python
|
||||||
|
from langchain_core.documents import Document
|
||||||
|
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||||
|
|
||||||
|
async def transform_to_langchain_docs(self, directory_structure):
|
||||||
|
documents = []
|
||||||
|
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
|
||||||
|
run_timestamp = datetime.utcnow().strftime('%Y%m%d%H%M%S')
|
||||||
|
|
||||||
|
for file_name in directory_structure:
|
||||||
|
if not file_name.endswith('/'):
|
||||||
|
try:
|
||||||
|
content = self.repo.get_contents(file_name, ref=self.branch_name)
|
||||||
|
try:
|
||||||
|
decoded_content = base64.b64decode(content.content).decode()
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error decoding content: {e}")
|
||||||
|
print("the problematic file_name is", file_name)
|
||||||
|
continue
|
||||||
|
print("file_name", file_name)
|
||||||
|
print("content", decoded_content)
|
||||||
|
|
||||||
|
# Split each document into smaller chunks
|
||||||
|
chunks = splitter.split_text(decoded_content)
|
||||||
|
|
||||||
|
# Extract metadata for each chunk
|
||||||
|
for index, chunk in enumerate(chunks):
|
||||||
|
metadata = {
|
||||||
|
"id": f"{run_timestamp}_{uuid4()}", # Generate a unique UUID for each document
|
||||||
|
"source": file_name,
|
||||||
|
"title": file_name,
|
||||||
|
"extension": os.path.splitext(file_name)[1],
|
||||||
|
"file_path": file_name
|
||||||
|
}
|
||||||
|
document = Document(
|
||||||
|
page_content=chunk,
|
||||||
|
metadata=metadata
|
||||||
|
)
|
||||||
|
documents.append(document)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error saving to vector store: {e}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
await save_to_vector_store(documents)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step 2: Insert your Langchain Documents into a Langchain VectorStore
|
||||||
|
|
||||||
|
```python
|
||||||
|
from langchain_postgres import PGVector
|
||||||
|
from langchain_postgres.vectorstores import PGVector
|
||||||
|
from sqlalchemy.ext.asyncio import create_async_engine
|
||||||
|
|
||||||
|
from langchain_community.embeddings import OpenAIEmbeddings
|
||||||
|
|
||||||
|
async def save_to_vector_store(self, documents):
|
||||||
|
# The documents are already Document objects, so we don't need to convert them
|
||||||
|
embeddings = OpenAIEmbeddings()
|
||||||
|
# self.vector_store = FAISS.from_documents(documents, embeddings)
|
||||||
|
pgvector_connection_string = os.environ["PGVECTOR_CONNECTION_STRING"]
|
||||||
|
|
||||||
|
collection_name = "my_docs"
|
||||||
|
|
||||||
|
vector_store = PGVector(
|
||||||
|
embeddings=embeddings,
|
||||||
|
collection_name=collection_name,
|
||||||
|
connection=pgvector_connection_string,
|
||||||
|
use_jsonb=True
|
||||||
|
)
|
||||||
|
|
||||||
|
# for faiss
|
||||||
|
# self.vector_store = vector_store.add_documents(documents, ids=[doc.metadata["id"] for doc in documents])
|
||||||
|
|
||||||
|
# Split the documents list into chunks of 100
|
||||||
|
for i in range(0, len(documents), 100):
|
||||||
|
chunk = documents[i:i+100]
|
||||||
|
# Insert the chunk into the vector store
|
||||||
|
vector_store.add_documents(chunk, ids=[doc.metadata["id"] for doc in chunk])
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step 3: Pass your Langchain Vectorstore into your GPTR report
|
||||||
|
|
||||||
|
```python
|
||||||
|
async_connection_string = pgvector_connection_string.replace("postgresql://", "postgresql+psycopg://")
|
||||||
|
|
||||||
|
# Initialize the async engine with the psycopg3 driver
|
||||||
|
async_engine = create_async_engine(
|
||||||
|
async_connection_string,
|
||||||
|
echo=True
|
||||||
|
)
|
||||||
|
|
||||||
|
async_vector_store = PGVector(
|
||||||
|
embeddings=embeddings,
|
||||||
|
collection_name=collection_name,
|
||||||
|
connection=async_engine,
|
||||||
|
use_jsonb=True
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="langchain_vectorstore",
|
||||||
|
vector_store=async_vector_store,
|
||||||
|
)
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
```
|
||||||
@ -0,0 +1,61 @@
|
|||||||
|
# Filtering by Domain
|
||||||
|
|
||||||
|
You can filter web search results by specific domains when using either the Tavily or Google Search retrievers. This functionality is available across all interfaces - pip package, NextJS frontend, and vanilla JS frontend.
|
||||||
|
|
||||||
|
> Note: We welcome contributions to add domain filtering to other retrievers!
|
||||||
|
|
||||||
|
To set Tavily as a retriever, you'll need to set the `RETRIEVER` environment variable to `tavily` and set the `TAVILY_API_KEY` environment variable to your Tavily API key.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
RETRIEVER=tavily
|
||||||
|
TAVILY_API_KEY=your_tavily_api_key
|
||||||
|
```
|
||||||
|
|
||||||
|
To set Google as a retriever, you'll need to set the `RETRIEVER` environment variable to `google` and set the `GOOGLE_API_KEY` and `GOOGLE_CX_KEY` environment variables to your Google API key and Google Custom Search Engine ID.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
RETRIEVER=google
|
||||||
|
GOOGLE_API_KEY=your_google_api_key
|
||||||
|
GOOGLE_CX_KEY=your_google_custom_search_engine_id
|
||||||
|
```
|
||||||
|
|
||||||
|
## Using the Pip Package
|
||||||
|
|
||||||
|
When using the pip package, you can pass a list of domains to filter results:
|
||||||
|
|
||||||
|
```python
|
||||||
|
report = GPTResearcher(
|
||||||
|
query="Latest AI Startups",
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="web",
|
||||||
|
domains=["forbes.com", "techcrunch.com"]
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Using the NextJS Frontend
|
||||||
|
|
||||||
|
When using the NextJS frontend, you can pass a list of domains to filter results via the Settings Modal:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Using the Vanilla JS Frontend
|
||||||
|
|
||||||
|
When using the Vanilla JS frontend, you can pass a list of domains to filter results via the relevant input field:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Filtering by Domain based on URL Param
|
||||||
|
|
||||||
|
If you'd like to show off for your work pals how GPTR is the ultra-customizable Deep Research Agent, you can send them a link to your hosted GPTR app with the domain filter included in the URL itself.
|
||||||
|
|
||||||
|
This can be handle for demonstrating a proof of concept of the Research Agent tailored to a specific domain. Some examples below:
|
||||||
|
|
||||||
|
### Single Domain:
|
||||||
|
|
||||||
|
https://gptr.app/?domains=wikipedia.org
|
||||||
|
|
||||||
|
### Multiple Domains:
|
||||||
|
|
||||||
|
https://gptr.app/?domains=wired.com,forbes.com,wikipedia.org
|
||||||
|
|
||||||
|
The `https://gptr.app` part of the URL can be replaces with [the domain that you deployed GPTR on](https://docs.gptr.dev/docs/gpt-researcher/getting-started/linux-deployment).
|
||||||
{kind=link}
|
After Width: | Height: | Size: 193 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
{kind=link}
|
After Width: | Height: | Size: 432 KiB |
@ -0,0 +1,22 @@
|
|||||||
|
# Local Documents
|
||||||
|
|
||||||
|
## Just Local Docs
|
||||||
|
|
||||||
|
You can instruct the GPT Researcher to run research tasks based on your local documents. Currently supported file formats are: PDF, plain text, CSV, Excel, Markdown, PowerPoint, and Word documents.
|
||||||
|
|
||||||
|
Step 1: Add the env variable `DOC_PATH` pointing to the folder where your documents are located.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export DOC_PATH="./my-docs"
|
||||||
|
```
|
||||||
|
|
||||||
|
Step 2:
|
||||||
|
- If you're running the frontend app on localhost:8000, simply select "My Documents" from the "Report Source" Dropdown Options.
|
||||||
|
- If you're running GPT Researcher with the [PIP package](https://docs.tavily.com/docs/gpt-researcher/gptr/pip-package), pass the `report_source` argument as "local" when you instantiate the `GPTResearcher` class [code sample here](https://docs.gptr.dev/docs/gpt-researcher/context/tailored-research).
|
||||||
|
|
||||||
|
## Local Docs + Web (Hybrid)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check out the blog post on [Hybrid Research](https://docs.gptr.dev/blog/gptr-hybrid) to learn more about how to combine local documents with web research.
|
||||||
|
```
|
||||||
@ -0,0 +1,147 @@
|
|||||||
|
# Tailored Research
|
||||||
|
|
||||||
|
The GPT Researcher package allows you to tailor the research to your needs such as researching on specific sources (URLs) or local documents, and even specify the agent prompt instruction upon which the research is conducted.
|
||||||
|
|
||||||
|
### Research on Specific Sources 📚
|
||||||
|
|
||||||
|
You can specify the sources you want the GPT Researcher to research on by providing a list of URLs. The GPT Researcher will then conduct research on the provided sources via `source_urls`.
|
||||||
|
|
||||||
|
If you want GPT Researcher to perform additional research outside of the URLs you provided, i.e., conduct research on various other websites that it finds suitable for the query/sub-query, you can set the parameter `complement_source_urls` as `True`. Default value of `False` will only scour the websites you provide via `source_urls`.
|
||||||
|
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_report(query: str, report_type: str, sources: list) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, source_urls=sources, complement_source_urls=False)
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "What are the biggest trends in AI lately?"
|
||||||
|
report_source = "static"
|
||||||
|
sources = [
|
||||||
|
"https://en.wikipedia.org/wiki/Artificial_intelligence",
|
||||||
|
"https://www.ibm.com/think/insights/artificial-intelligence-trends",
|
||||||
|
"https://www.forbes.com/advisor/business/ai-statistics"
|
||||||
|
]
|
||||||
|
report = asyncio.run(get_report(query=query, report_source=report_source, sources=sources))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Specify Agent Prompt 📝
|
||||||
|
|
||||||
|
You can specify the agent prompt instruction upon which the research is conducted. This allows you to guide the research in a specific direction and tailor the report layout.
|
||||||
|
Simply pass the prompt as the `query` argument to the `GPTResearcher` class and the "custom_report" `report_type`.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_report(prompt: str, report_type: str) -> str:
|
||||||
|
researcher = GPTResearcher(query=prompt, report_type=report_type)
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
report_type = "custom_report"
|
||||||
|
prompt = "Research the latest advancements in AI and provide a detailed report in APA format including sources."
|
||||||
|
|
||||||
|
report = asyncio.run(get_report(prompt=prompt, report_type=report_type))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Research on Local Documents 📄
|
||||||
|
You can instruct the GPT Researcher to research on local documents by providing the path to those documents. Currently supported file formats are: PDF, plain text, CSV, Excel, Markdown, PowerPoint, and Word documents.
|
||||||
|
|
||||||
|
*Step 1*: Add the env variable `DOC_PATH` pointing to the folder where your documents are located.
|
||||||
|
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export DOC_PATH="./my-docs"
|
||||||
|
```
|
||||||
|
|
||||||
|
*Step 2*: When you create an instance of the `GPTResearcher` class, pass the `report_source` argument as `"local"`.
|
||||||
|
|
||||||
|
GPT Researcher will then conduct research on the provided documents.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
async def get_report(query: str, report_source: str) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_source=report_source)
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "What can you tell me about myself based on my documents?"
|
||||||
|
report_source = "local" # "local" or "web"
|
||||||
|
|
||||||
|
report = asyncio.run(get_report(query=query, report_source=report_source))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Hybrid Research 🔄
|
||||||
|
You can combine the above methods to conduct hybrid research. For example, you can instruct the GPT Researcher to research on both web sources and local documents.
|
||||||
|
Simply provide the sources and set the `report_source` argument as `"hybrid"` and watch the magic happen.
|
||||||
|
|
||||||
|
Please note! You should set the proper retrievers for the web sources and doc path for local documents for this to work.
|
||||||
|
To learn more about retrievers check out the [Retrievers](https://docs.gptr.dev/docs/gpt-researcher/search-engines/retrievers) documentation.
|
||||||
|
|
||||||
|
|
||||||
|
### Research on LangChain Documents 🦜️🔗
|
||||||
|
You can instruct the GPT Researcher to research on a list of langchain document instances.
|
||||||
|
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from langchain_core.documents import Document
|
||||||
|
from typing import List, Dict
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from langchain_postgres.vectorstores import PGVector
|
||||||
|
from langchain_openai import OpenAIEmbeddings
|
||||||
|
from sqlalchemy import create_engine
|
||||||
|
import asyncio
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
CONNECTION_STRING = 'postgresql://someuser:somepass@localhost:5432/somedatabase'
|
||||||
|
|
||||||
|
def get_retriever(collection_name: str, search_kwargs: Dict[str, str]):
|
||||||
|
engine = create_engine(CONNECTION_STRING)
|
||||||
|
embeddings = OpenAIEmbeddings()
|
||||||
|
|
||||||
|
index = PGVector.from_existing_index(
|
||||||
|
use_jsonb=True,
|
||||||
|
embedding=embeddings,
|
||||||
|
collection_name=collection_name,
|
||||||
|
connection=engine,
|
||||||
|
)
|
||||||
|
|
||||||
|
return index.as_retriever(search_kwargs=search_kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
async def get_report(query: str, report_type: str, report_source: str, documents: List[Document]) -> str:
|
||||||
|
researcher = GPTResearcher(query=query, report_type=report_type, report_source=report_source, documents=documents)
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
return report
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
query = "What can you tell me about blue cheese based on my documents?"
|
||||||
|
report_type = "research_report"
|
||||||
|
report_source = "langchain_documents"
|
||||||
|
|
||||||
|
# using a LangChain retriever to get all the documents regarding cheese
|
||||||
|
# https://api.python.langchain.com/en/latest/retrievers/langchain_core.retrievers.BaseRetriever.html#langchain_core.retrievers.BaseRetriever.invoke
|
||||||
|
langchain_retriever = get_retriever("cheese_collection", { "k": 3 })
|
||||||
|
documents = langchain_retriever.invoke("All the documents about cheese")
|
||||||
|
report = asyncio.run(get_report(query=query, report_type=report_type, report_source=report_source, documents=documents))
|
||||||
|
print(report)
|
||||||
|
```
|
||||||
@ -0,0 +1,155 @@
|
|||||||
|
# Vector Stores
|
||||||
|
|
||||||
|
The GPT Researcher package allows you to integrate with existing langchain vector stores that have been populated.
|
||||||
|
For a complete list of supported langchain vector stores, please refer to this [link](https://python.langchain.com/v0.2/docs/integrations/vectorstores/).
|
||||||
|
|
||||||
|
You can create a set of embeddings and langchain documents and store them in any supported vector store of your choosing.
|
||||||
|
GPT-Researcher will work with any langchain vector store that implements the `asimilarity_search` method.
|
||||||
|
|
||||||
|
**If you want to use the existing knowledge in your vector store, make sure to set `report_source="langchain_vectorstore"`. Any other settings will add additional information from scraped data and might contaminate your vectordb (See _How to add scraped data to your vector store_ for more context)**
|
||||||
|
|
||||||
|
## Faiss
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
from langchain.text_splitter import CharacterTextSplitter
|
||||||
|
from langchain_openai import OpenAIEmbeddings
|
||||||
|
from langchain_community.vectorstores import FAISS
|
||||||
|
from langchain_core.documents import Document
|
||||||
|
|
||||||
|
# exerpt taken from - https://paulgraham.com/wealth.html
|
||||||
|
essay = """
|
||||||
|
May 2004
|
||||||
|
|
||||||
|
(This essay was originally published in Hackers & Painters.)
|
||||||
|
|
||||||
|
If you wanted to get rich, how would you do it? I think your best bet would be to start or join a startup.
|
||||||
|
That's been a reliable way to get rich for hundreds of years. The word "startup" dates from the 1960s,
|
||||||
|
but what happens in one is very similar to the venture-backed trading voyages of the Middle Ages.
|
||||||
|
|
||||||
|
Startups usually involve technology, so much so that the phrase "high-tech startup" is almost redundant.
|
||||||
|
A startup is a small company that takes on a hard technical problem.
|
||||||
|
|
||||||
|
Lots of people get rich knowing nothing more than that. You don't have to know physics to be a good pitcher.
|
||||||
|
But I think it could give you an edge to understand the underlying principles. Why do startups have to be small?
|
||||||
|
Will a startup inevitably stop being a startup as it grows larger?
|
||||||
|
And why do they so often work on developing new technology? Why are there so many startups selling new drugs or computer software,
|
||||||
|
and none selling corn oil or laundry detergent?
|
||||||
|
|
||||||
|
|
||||||
|
The Proposition
|
||||||
|
|
||||||
|
Economically, you can think of a startup as a way to compress your whole working life into a few years.
|
||||||
|
Instead of working at a low intensity for forty years, you work as hard as you possibly can for four.
|
||||||
|
This pays especially well in technology, where you earn a premium for working fast.
|
||||||
|
|
||||||
|
Here is a brief sketch of the economic proposition. If you're a good hacker in your mid twenties,
|
||||||
|
you can get a job paying about $80,000 per year. So on average such a hacker must be able to do at
|
||||||
|
least $80,000 worth of work per year for the company just to break even. You could probably work twice
|
||||||
|
as many hours as a corporate employee, and if you focus you can probably get three times as much done in an hour.[1]
|
||||||
|
You should get another multiple of two, at least, by eliminating the drag of the pointy-haired middle manager who
|
||||||
|
would be your boss in a big company. Then there is one more multiple: how much smarter are you than your job
|
||||||
|
description expects you to be? Suppose another multiple of three. Combine all these multipliers,
|
||||||
|
and I'm claiming you could be 36 times more productive than you're expected to be in a random corporate job.[2]
|
||||||
|
If a fairly good hacker is worth $80,000 a year at a big company, then a smart hacker working very hard without
|
||||||
|
any corporate bullshit to slow him down should be able to do work worth about $3 million a year.
|
||||||
|
...
|
||||||
|
...
|
||||||
|
...
|
||||||
|
"""
|
||||||
|
|
||||||
|
document = [Document(page_content=essay)]
|
||||||
|
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=30, separator="\n")
|
||||||
|
docs = text_splitter.split_documents(documents=document)
|
||||||
|
|
||||||
|
vector_store = FAISS.from_documents(documents, OpenAIEmbeddings())
|
||||||
|
|
||||||
|
query = """
|
||||||
|
Summarize the essay into 3 or 4 succinct sections.
|
||||||
|
Make sure to include key points regarding wealth creation.
|
||||||
|
|
||||||
|
Include some recommendations for entrepreneurs in the conclusion.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
# Create an instance of GPTResearcher
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="langchain_vectorstore",
|
||||||
|
vector_store=vector_store,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Conduct research and write the report
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## PGVector
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
from langchain_postgres.vectorstores import PGVector
|
||||||
|
from langchain_openai import OpenAIEmbeddings
|
||||||
|
|
||||||
|
CONNECTION_STRING = 'postgresql://someuser:somepass@localhost:5432/somedatabase'
|
||||||
|
|
||||||
|
|
||||||
|
# assuming the vector store exists and contains the relevent documents
|
||||||
|
# also assuming embeddings have been or will be generated
|
||||||
|
vector_store = PGVector.from_existing_index(
|
||||||
|
use_jsonb=True,
|
||||||
|
embedding=OpenAIEmbeddings(),
|
||||||
|
collection_name='some collection name',
|
||||||
|
connection=CONNECTION_STRING,
|
||||||
|
async_mode=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
query = """
|
||||||
|
Create a short report about apples.
|
||||||
|
Include a section about which apples are considered best
|
||||||
|
during each season.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Create an instance of GPTResearcher
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="langchain_vectorstore",
|
||||||
|
vector_store=vector_store,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Conduct research and write the report
|
||||||
|
await researcher.conduct_research()
|
||||||
|
report = await researcher.write_report()
|
||||||
|
```
|
||||||
|
## Adding Scraped Data to your vector store
|
||||||
|
|
||||||
|
In some cases in which you want to store the scraped data and documents into your own vector store for future usages, GPT-Researcher also allows you to do so seamlessly just by inputting your vector store (make sure to set `report_source` value to something other than `langchain_vectorstore`)
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gpt_researcher import GPTResearcher
|
||||||
|
|
||||||
|
from langchain_community.vectorstores import InMemoryVectorStore
|
||||||
|
from langchain_openai import OpenAIEmbeddings
|
||||||
|
|
||||||
|
vector_store = InMemoryVectorStore(embedding=OpenAIEmbeddings())
|
||||||
|
|
||||||
|
query = "The best LLM"
|
||||||
|
|
||||||
|
# Create an instance of GPTResearcher
|
||||||
|
researcher = GPTResearcher(
|
||||||
|
query=query,
|
||||||
|
report_type="research_report",
|
||||||
|
report_source="web",
|
||||||
|
vector_store=vector_store,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Conduct research, the context will be chunked and stored in the vector_store
|
||||||
|
await researcher.conduct_research()
|
||||||
|
|
||||||
|
# Query the 5 most relevant context in our vector store
|
||||||
|
related_contexts = await vector_store.asimilarity_search("GPT-4", k = 5)
|
||||||
|
print(related_contexts)
|
||||||
|
print(len(related_contexts)) #Should be 5
|
||||||
|
```
|
||||||
@ -0,0 +1,73 @@
|
|||||||
|
# Discord Bot
|
||||||
|
|
||||||
|
## Intro
|
||||||
|
|
||||||
|
You can either leverage the official GPTR Discord bot or create your own custom bot.
|
||||||
|
|
||||||
|
To add the official GPTR Discord bot, simply [click here to invite GPTR to your Discord server](https://discord.com/oauth2/authorize?client_id=1281438963034361856&permissions=1689934339898432&integration_type=0&scope=bot).
|
||||||
|
|
||||||
|
|
||||||
|
## To create your own discord bot with GPTR functionality
|
||||||
|
|
||||||
|
Add a .env file in the root of the project and add the following:
|
||||||
|
|
||||||
|
```
|
||||||
|
DISCORD_BOT_TOKEN=
|
||||||
|
DISCORD_CLIENT_ID=
|
||||||
|
```
|
||||||
|
You can fetch the token from the Discord Developer Portal by following these steps:
|
||||||
|
|
||||||
|
1. Go to https://discord.com/developers/applications/
|
||||||
|
2. Click the "New Application" button and give your bot a name
|
||||||
|
3. Navigate to the OAuth2 tab to generate an invite URL for your bot
|
||||||
|
4. Under "Scopes", select "bot"
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
5. Select the appropriate bot permissions
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
6. Copy your bot's token and paste it into the `.env` file you created earlier
|
||||||
|
|
||||||
|
|
||||||
|
### Deploying the bot commands
|
||||||
|
|
||||||
|
```bash
|
||||||
|
node deploy-commands.js
|
||||||
|
```
|
||||||
|
|
||||||
|
In our case, this will make the "ask" and "ping" commands available to users of the bot.
|
||||||
|
|
||||||
|
|
||||||
|
### Running the bot via Docker
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose --profile discord run --rm discord-bot
|
||||||
|
```
|
||||||
|
|
||||||
|
### Running the bot via CLI
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# install dependencies
|
||||||
|
npm install
|
||||||
|
|
||||||
|
# run the bot
|
||||||
|
npm run dev
|
||||||
|
```
|
||||||
|
|
||||||
|
### Installing NodeJS and NPM on Ubuntu
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#install nvm
|
||||||
|
wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.4/install.sh | bash
|
||||||
|
|
||||||
|
export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
|
||||||
|
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
|
||||||
|
|
||||||
|
# install nodejs
|
||||||
|
nvm install 18.17.0
|
||||||
|
|
||||||
|
# install npm
|
||||||
|
sudo apt-get install npm
|
||||||
|
```
|
||||||
@ -0,0 +1,30 @@
|
|||||||
|
# Embed Script
|
||||||
|
|
||||||
|
The embed script enables you to embed the latest GPTR NextJS app into your web app.
|
||||||
|
|
||||||
|
To achieve this, simply add these 2 script tags into your HTML:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
<script>localStorage.setItem("GPTR_API_URL", "http://localhost:8000");</script>
|
||||||
|
<script src="https://gptr.app/embed.js"></script>
|
||||||
|
```
|
||||||
|
|
||||||
|
Here's a minmalistic HTML example (P.S. You can also save this as an index.html file and open it with your Web Browser)
|
||||||
|
|
||||||
|
```html
|
||||||
|
<!DOCTYPE html>
|
||||||
|
<html lang="en">
|
||||||
|
<head>
|
||||||
|
<meta charset="UTF-8">
|
||||||
|
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||||
|
<title>GPT Researcher Embed Demo</title>
|
||||||
|
</head>
|
||||||
|
<body style="margin: 0; padding: 0;">
|
||||||
|
<!-- GPT Researcher Embed -->
|
||||||
|
<script>localStorage.setItem("GPTR_API_URL", "http://localhost:8000");</script>
|
||||||
|
<script src="https://gptr.app/embed.js"></script>
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
|
```
|
||||||
|
|
||||||
|
This example relies on setting a custom localstorage value for `GPTR_API_URL`. To point your embedded frontend at a custom GPTR API Server, feel free to edit `http://localhost:8000` to your custom GPTR server address.
|
||||||
{kind=link}
|
After Width: | Height: | Size: 2.2 MiB |
{kind=link}
|
After Width: | Height: | Size: 722 KiB |
@ -0,0 +1,17 @@
|
|||||||
|
# Intro to the Frontends
|
||||||
|
|
||||||
|
The frontends enhance GPT-Researcher by providing:
|
||||||
|
|
||||||
|
1. Intuitive Research Interface: Streamlined input for research queries.
|
||||||
|
2. Real-time Progress Tracking: Visual feedback on ongoing research tasks.
|
||||||
|
3. Interactive Results Display: Easy-to-navigate presentation of findings.
|
||||||
|
4. Customizable Settings: Adjust research parameters to suit specific needs.
|
||||||
|
5. Responsive Design: Optimal experience across various devices.
|
||||||
|
|
||||||
|
These features aim to make the research process more efficient and user-friendly, complementing GPT-Researcher's powerful agent capabilities.
|
||||||
|
|
||||||
|
## Choosing an Option
|
||||||
|
|
||||||
|
- Static Frontend: Quick setup, lightweight deployment.
|
||||||
|
- NextJS Frontend: Feature-rich, scalable, better performance and SEO (For production, NextJS is recommended)
|
||||||
|
- Discord Bot: Integrate GPT-Researcher into your Discord server.
|
||||||
@ -0,0 +1,99 @@
|
|||||||
|
# NextJS Frontend
|
||||||
|
|
||||||
|
This frontend project aims to enhance the user experience of GPT Researcher, providing an intuitive and efficient interface for automated research. It offers two deployment options to suit different needs and environments.
|
||||||
|
|
||||||
|
#### Demo
|
||||||
|
<iframe height="400" width="700" src="https://github.com/user-attachments/assets/092e9e71-7e27-475d-8c4f-9dddd28934a3" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
|
||||||
|
|
||||||
|
View an in-depth Product Tutorial here: [GPT-Researcher Frontend Tutorial](https://www.youtube.com/watch?v=hIZqA6lPusk)
|
||||||
|
|
||||||
|
|
||||||
|
## NextJS Frontend App
|
||||||
|
|
||||||
|
The React app (located in the `frontend` directory) is our Frontend 2.0 which we hope will enable us to display the robustness of the backend on the frontend, as well.
|
||||||
|
|
||||||
|
It comes with loads of added features, such as:
|
||||||
|
- a drag-n-drop user interface for uploading and deleting files to be used as local documents by GPTResearcher.
|
||||||
|
- a GUI for setting your GPTR environment variables.
|
||||||
|
- the ability to trigger the multi_agents flow via the Backend Module or Langgraph Cloud Host (currently in closed beta).
|
||||||
|
- stability fixes
|
||||||
|
- and more coming soon!
|
||||||
|
|
||||||
|
### Run the NextJS React App with Docker
|
||||||
|
|
||||||
|
> **Step 1** - [Install Docker](https://docs.gptr.dev/docs/gpt-researcher/getting-started/getting-started-with-docker)
|
||||||
|
|
||||||
|
> **Step 2** - Clone the '.env.example' file, add your API Keys to the cloned file and save the file as '.env'
|
||||||
|
|
||||||
|
> **Step 3** - Within the docker-compose file comment out services that you don't want to run with Docker.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
If that doesn't work, try running it without the dash:
|
||||||
|
```bash
|
||||||
|
docker compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Step 4** - By default, if you haven't uncommented anything in your docker-compose file, this flow will start 2 processes:
|
||||||
|
- the Python server running on localhost:8000
|
||||||
|
- the React app running on localhost:3000
|
||||||
|
|
||||||
|
Visit localhost:3000 on any browser and enjoy researching!
|
||||||
|
|
||||||
|
If, for some reason, you don't want to run the GPTR API Server on localhost:8000, no problem! You can set the `NEXT_PUBLIC_GPTR_API_URL` environment variable in your `.env` file to the URL of your GPTR API Server.
|
||||||
|
|
||||||
|
For example:
|
||||||
|
```
|
||||||
|
NEXT_PUBLIC_GPTR_API_URL=https://gptr.app
|
||||||
|
```
|
||||||
|
|
||||||
|
Or:
|
||||||
|
```
|
||||||
|
NEXT_PUBLIC_GPTR_API_URL=http://localhost:7000
|
||||||
|
```
|
||||||
|
|
||||||
|
## Running NextJS Frontend via CLI
|
||||||
|
|
||||||
|
A more robust solution with enhanced features and performance.
|
||||||
|
|
||||||
|
#### Prerequisites
|
||||||
|
- Node.js (v18.17.0 recommended)
|
||||||
|
- npm
|
||||||
|
|
||||||
|
#### Setup and Running
|
||||||
|
|
||||||
|
1. Navigate to NextJS directory:
|
||||||
|
```
|
||||||
|
cd nextjs
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Set up Node.js:
|
||||||
|
```
|
||||||
|
nvm install 18.17.0
|
||||||
|
nvm use v18.17.0
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Install dependencies:
|
||||||
|
```
|
||||||
|
npm install --legacy-peer-deps
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Start development server:
|
||||||
|
```
|
||||||
|
npm run dev
|
||||||
|
```
|
||||||
|
|
||||||
|
5. Access at `http://localhost:3000`
|
||||||
|
|
||||||
|
Note: Requires backend server on `localhost:8000` as detailed in option 1.
|
||||||
|
|
||||||
|
|
||||||
|
### Adding Google Analytics
|
||||||
|
|
||||||
|
To add Google Analytics to your NextJS frontend, simply add the following to your `.env` file:
|
||||||
|
|
||||||
|
```
|
||||||
|
NEXT_PUBLIC_GA_MEASUREMENT_ID="G-G2YVXKHJNZ"
|
||||||
|
```
|
||||||
@ -0,0 +1,44 @@
|
|||||||
|
# React Package
|
||||||
|
|
||||||
|
The GPTR React package is an abstraction on top of the NextJS app meant to empower users to easily import the GPTR frontend into any React App. The package is [available on npm](https://www.npmjs.com/package/gpt-researcher-ui).
|
||||||
|
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
|
||||||
|
```bash
|
||||||
|
npm install gpt-researcher-ui
|
||||||
|
```
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
import React from 'react';
|
||||||
|
import { GPTResearcher } from 'gpt-researcher-ui';
|
||||||
|
|
||||||
|
function App() {
|
||||||
|
return (
|
||||||
|
<div className="App">
|
||||||
|
<GPTResearcher
|
||||||
|
apiUrl="http://localhost:8000"
|
||||||
|
defaultPrompt="What is quantum computing?"
|
||||||
|
onResultsChange={(results) => console.log('Research results:', results)}
|
||||||
|
/>
|
||||||
|
</div>
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
export default App;
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Publishing to a private npm registry
|
||||||
|
|
||||||
|
If you'd like to build and publish the package into your own private npm registry, you can do so by running the following commands:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd frontend/nextjs/
|
||||||
|
npm run build:lib
|
||||||
|
npm run build:types
|
||||||
|
npm publish
|
||||||
|
```
|
||||||
|
|
||||||